 598
598 
Содержание
Чтобы дополнить наши курсы по Kafka и Spark интересными примерами, сегодня рассмотрим практический кейс разработки микросервисного конвейера машинного обучения на этих фреймворках. Читайте далее, зачем выносить ML-компонент в отдельное Python-приложение от остальной части Big Data pipeline’а, и как Docker поддерживает эту концепцию микросервисного подхода.
Постановка задачи и компоненты микросервисного ML-конвейера на Kafka и Spark
Предположим, в рамках системы автоматического реагирования на обращения пользователей необходимо анализировать тональность и семантику входящий сообщений, чтобы направить жалобу с максимальным эмоциональным окрасом и наиболее значимым содержанием на ручной разбор ответственному сотруднику. Анализ речи и текстов с помощью алгоритмов машинного обучения относится к классу задач обработки естественного языка (NLP, Natural Language Processing).
На практике одним из наиболее простых и достаточно популярных инструментов решения NLP-задач является NLTK – open-source Python-платформа. Она предоставляет интерфейсы для более чем 50 корпусов и лексических ресурсов, таких как WordNet, а также набор библиотек обработки текста для классификации, токенизации, стемминга, тегирования, синтаксического и семантического анализа, а также оболочки для промышленных NLP-библиотек [1]. Таким образом, в рамках рассматриваемого кейса за анализ текста сообщений средствами машинного обучения будет отвечать NLTK с предварительно обученными ML-моделями.
Поскольку речь идет о потоковой обработке данных, в дело вступают Apache Kafka и Spark [2]:
- поступающие данные постоянно записываются в топики Kafka в виде сообщений, например, в формате JSON;
- задания Spark Structured Streaming потребляют данные из топиков Kafka, в режиме максимально близком к реальному времени.
Помимо этих фреймворков, для разработки всего микросервисного ML-конвейера также понадобятся следующие компоненты:
- Flask – Python-пакет с открытым исходным кодом для создания RESTful-микросервисов;
- Docker – мощная технология контейнеризации, ускоряющая все DevOps-процессы, от разработки и тестирования ПО до развертывания и обновления за счет упаковки рабочего окружения приложений со всеми зависимостями в изолированные контейнеры;
- Jupyter lab – портативная среда для запуска ML-конвейера.
Сам модуль машинного обучения может быть реализован двумя способами:
- вызов ML-модели непосредственно в среде Spark-конвейера;
- создание микросервиса, который будет вызывать конвейер.
Хотя 2-ой вариант требует создания оболочки для ML-модели, он позволяет отделить часть Machine Learning от остального конвейера, упрощая изменение алгоритмов машинного обучения Таким образом, для развертывания новой версии модели не нужно менять весь data pipeline: достаточно лишь поменять микросервис. Также микросервисный подход позволяет тестировать разные версии ML-моделей с регулировкой входящего трафика. Например, 80% потока входящих сообщений данных для версии А и 20% для версии B. Как реализовать все это с использованием упомянутых компонентов, рассмотрим далее.
От локального Jupyter-notebook до распределенного PySpark-приложения: 9 простых шагов
Весь процесс создания описанного ML-конвейера на базе Apache Kafka, Spark и микросервисного подхода состоит из следующих основных шагов:
- создание Docker-образа для Spark/Jupyter;
- запуск Docker-контейнеров для кластера Apache Kafka, а также notebook’ов Jupyter и Spark;
- создание и развертывание NLP-микросервиса для анализа содержания входящего сообщения. Например, следующий Python-код
@app.route(‘/predict’, methods=[‘POST’])
def predict():
result = sid.polarity_scores(request.get_json()[‘data’])
return jsonify(result)
получает POST-запрос с JSON-сообщением в форме {«data»: «some text»}, где данные поля содержат предложение для анализа. Функция polarity_scores — это алгоритм машинного обучения, который запускает анализ тональности, возвращая результат в формате JSON.
- Запуск Jupyter-notebook с токеном безопасности, созданном на этапе 2;
- инициализация связи между Spark и Kafka с помощью JAR-файла, установленном при создании Docker-образа demo-pyspark-notebook. Следующий код устанавливает ссылки на этот и другие JAR-файлы с помощью переменной среды PYSPARK_SUBMIT_ARGS:
import os
os.environ[‘PYSPARK_SUBMIT_ARGS’] = «—packages=org.apache.spark:spark-sql-kafka-0-10_2.12:3.0.0 pyspark-shell»
Здесь же следует инициализировать pySpark с помощью пакета findspark:
import findspark
findspark.init()
- запуск Kafka-продюсера, который будет писать сообщения в топики. Для простоты обучения в рассматриваемом примере для этого используется библиотека confluent_kafka в Python. Она отправляет сообщение JSON {«data»: value}, где value — это предложение текста для анализа. Для каждого сообщения, записанного в очередь, требуется ключ – случайный uuidkey, чтобы равномерно распределять данные по узлам кластера.
- Чтение сообщений из топиков Kafka с помощью Spark Structured Streaming. Следующий код загружает микропакеты данных в структуру данных Apache Spark – датафреймы:
df_raw = spark \
.readStream \
.format(‘kafka’) \
.option(‘kafka.bootstrap.servers’, bootstrap_servers) \
.option(«startingOffsets», «earliest») \
.option(‘subscribe’, topic) \
.load()
Начальное смещение (startingOffset) установлено на самое раннее (earliest), чтобы конвейер читал все данные из очереди, каждый раз при запуске кода. Поскольку из всего набора данных в топиках Kafka необходимы только фактические значения, следует запустить преобразование через функцию CAST, которая преобразует выражение из одного типа данных в другой:
df_json = df_raw.selectExpr(‘CAST(value AS STRING) as json’)
- задание пользовательской функции для применения ML-модели. UDF (User Defined Function) применяется к каждой строке датафрейма:
def apply_sentiment_analysis(data):
import requests
import json
result = requests.post(‘REST-service URL’, json=json.loads(data))
return json.dumps(result.json())
Здесь сперва определяется функция apply_setiment_analysis, которая отправляет запрос в конечную точку и возвращает ответ. Необходимый импорт помещен в саму функцию, т.к. этот код может быть распределен на нескольких узлах кластера.
vader_udf = udf(lambda data: apply_sentiment_analysis(data), StringType())
Далее функция apply_setiment_analysis оборачивается в UDF с именем vader_udf, возвращая столбец с данными строкового типа. Об особенностях UDF в Apache Spark мы недавно писали здесь и здесь.
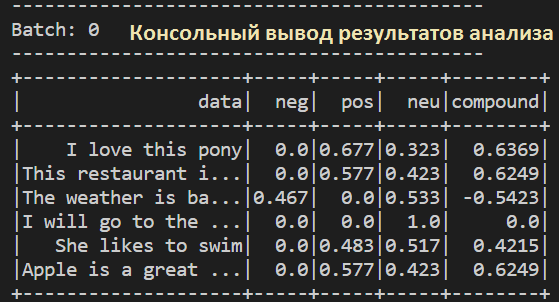
- Наконец, созданная UDF применяется к данным. На этом шаге отображаются результаты. JSON-формат входных данных преобразован в строку с помощью вспомогательной функции from_json. Аналогичное преобразование применено к выходному столбцу из алгоритма анализа тональности.
Результаты отображаются в консоли, и их можно визуализировать только с того терминала, где запущен Jupyter. Триггер команды (once = True) будет запускать обработку потока только на короткий период и отображать выходные данные.

Подробнее код и рекомендации по запуску отдельных компонентов рассмотренного ML-конвейера приведены в источнике [2].
Построить подобный ML-конвейер для решения NLP-задач на Apache Kafka и Spark для, а также освоить все нюансы потоковой аналитики больших данных с помощью Machine Learning средствами Python и PySpark, вам помогут специализированные курсы в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Apache Kafka для разработчиков
- Анализ данных с Apache Spark
- Машинное обучение в Apache Spark
- Потоковая обработка в Apache Spark
- Apache Spark для разработчиков
- Машинное обучение на Python
- NLP с Python
Источники

