 1222
1222 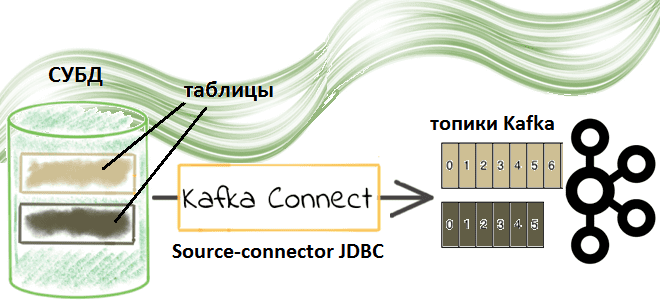
Содержание
Недавно мы рассматривали пример потоковой передачи данных между реляционными СУБД с помощью готовых JDBC-коннекторов через cURL-вызовы к REST API Kafka Connect. Сегодня заглянем под капот такой интеграции и разберем подробнее, что именно представляет собой JDBC-коннектор источника Kafka от Confluent.
Компоненты Kafka Confluent для потоковой интеграции данных: коннекторы и реестр схем
В прошлый раз мы показали, как Kafka Connect позволяет реализовать гибкую интеграцию между разными приложениями, заменяя медленные пакетные задания точечных интеграций между отдельными сервисами на быстрые потоковые обновления по всему ИТ-ландшафту предприятия. Этот компонент платформы Confluent отвечает за масштабируемый и надежный способ перемещения данных в Apache Kafka и из нее. На практике чаще всего используется JDBC Connector (Source & Sink), который позволяет интегрировать разные СУБД через обмен данными в топиках Kafka [1].
Если с загруженными данными публикации не будет никаких операций, можно использовать только JDBC-коннектор, не запуская другой компонент платформы Kafka Confluent: реестр схем (Shema Registry). Однако, в реальных кейсах обычно требуется поддерживать совместимый формат данных в источниках и потребителях. Именно это и обеспечивает Shema Registry, поддерживая простое использование Avro, Protobuf и схемы JSON в качестве общих форматов данных для записей Kafka, которые коннекторы читают и записывают. Подробнее о Shema Registry мы писали здесь.
Что особенно важно в задачах интеграции данных, JDBC-коннектор поддерживает эволюцию схемы при использовании конвертера Avro. При изменении схемы таблицы базы данных JDBC-коннектор может обнаружить это, создать новую схему Connect и зарегистрировать новую схему Avro в реестре схем. Успех этого действия зависит от уровня совместимости Shema Registry, который по умолчанию является обратным. Например, если из таблицы удалить столбец, изменение будет обратно совместимым, и соответствующая схема Avro может быть успешно зарегистрирована в реестре. Но, когда схема Avro уже зарегистрирована в реестре и изменена схема таблицы, добавление нового столбца или изменение его типа не будет отражено в Shema Registry, т.к. такие изменения не имеют обратной совместимости. Избежать такого несоответствия поможет изменение уровня совместимости реестра схем одним из следующих способов [2]:
- Установить уровень совместимости для субъектов, которые используются коннектором, с помощью PUT/config/(string: subject). Эти субъекты имеют формат topic-keyи topic-value, где топик определяется конфигурацией prefix и именем таблицы.
- Настроить реестр схем для использования другого уровня совместимости, определив compatibility.level – глобальный параметр, который применяется ко всем схемам в реестре.
Из-за ограничений JDBC API некоторые совместимые изменения схемы могут считаться несовместимыми. В частности, как мы упомянули выше, добавление столбца со значением по умолчанию — это изменение с обратной совместимостью. Но ограничения JDBC API затрудняют сопоставление этого значения со значениями правильного типа в схеме Kafka Connect, поэтому значения по умолчанию не заданы, из-за чего схема, зарегистрированная в реестре, не имеет обратной совместимости.
Подобные ограничения совместимости схемы наблюдаются при использовании JDBC-коннектора вместе с коннектором HDFS. Когда включена интеграция Hive, совместимость схемы должна быть обратной, прямой и полной, чтобы схема Apache Hive могла запрашивать все данные в топике Kafka [2]. Эти нюансы следует учитывать в production при постоянной загрузке данных из разных СУБД в Apache Kafka и дальнейшей передаче через несколько конвейеров в другие системы, чтобы с помощью реестра схем снизить операционную сложность интеграции, обеспечив совместимость и эволюцию данных [1].
Как работает JDBC-коннектор Kafka Confluent
Итак, source-коннектор JDBC Kafka Connect позволяет импортировать данные из любой реляционной СУБД с драйвером JDBC в топик Apache Kafka. Данные загружаются путем периодического выполнения SQL-запроса и создания выходной записи для каждой строки в наборе результатов. По умолчанию каждая таблица из базы-источника копируется в отдельный выходной топик Kafka, а исходная СУБД непрерывно отслеживается на наличие новых или удаленных таблиц. При копировании данных из таблицы JDBC-коннектор может загружать только новые или измененные строки, указывая, какие столбцы следует использовать для их обнаружения.
Можно настроить приложения потоков Java для десериализации и приема данных несколькими способами, включая консольные продюсеры Kafka, source-коннекторы JDBC и продюсеры клиентов Java. Source-коннектор JDBC Kafka поддерживает копирование таблиц с различными типами JDBC-данных, динамическое добавление и удаление таблиц из базы, белые и черные списки, различные интервалы опроса и другие параметры, а также особенно важные для большинства пользователей настройки управления инкрементным копированием данных из СУБД.
Kafka Connect отслеживает самую последнюю запись, полученную из каждой таблицы, чтобы снова запускаться в нужном месте на следующей итерации или в случае сбоя. Коннектор источника использует эту возможность только для получения обновленных строк из таблицы или из вывода настраиваемого запроса на каждой итерации в зависимости от режима обнаружения измененных строк.
Главными функциями source-коннектора JDBC Kafka можно назвать следующие [1]:
- семантика доставки хотя бы 1 раз (at least once), гарантируя, что записи будут доставлены в топик Kafka хотя бы один раз. Если коннектор перезапускается, в топике Kafka могут быть повторяющиеся записи.
- Выполнение только одной задачи в режиме запроса, но в ее рамках может читать сразу несколько таблиц СУБД.
- 3 режима инкрементальных запросов (Incrementing Column, Timestamp Column, Custom Query), каждый из которых отслеживает набор столбцов для обработанных, новых или измененных строк. Все эти режимы используют столбцы для обнаружения изменений, а потому требуют их индексирования для эффективного выполнения запросов. Также есть режим Bulk, который не фильтруется и не является инкрементным, а будет загружать все строки из таблицы на каждой итерации. Это полезно при периодической выгрузке всей таблицы, где записи в конечном итоге удаляются, а следующая система может безопасно обрабатывать дубликаты.
- Ключи сообщений. Поскольку сообщение в Kafka представляют собой пару ключ-значение, то для JDBC-коннектора значение как полезная нагрузка – это содержимое принимаемой строки таблицы. По умолчанию JDBC-коннектор не генерирует ключ сообщения, однако он может пригодится при настройке стратегии партиционирования, направляя сообщения в конкретный раздел. Также ключи могут поддерживать последующую обработку данных, например, в рамках JOIN-соединения. Без указания ключа, сообщения отправляются в разделы с использованием циклического распределения. Чтобы установить ключ сообщения для JDBC-коннектора, следует добавить в его конфигурацию два преобразования одного сообщения (SMT, Single Message Transformation): ValueToKey SMT и ExtractField SMT.
- Сопоставление типов столбцов с типами полей в Kafka Connect. По умолчанию коннектор сопоставляет типы SQL/JDBC для точного представления в Java, что достаточно просто для многих типов данных SQL. Например, типы SQL NUMERIC и DECIMAL чаще всего соответствуют логическому типу Connect Decimal, который использует представление Java BigDecimal. Avro сериализует десятичные типы как байты, которые могут быть трудными для использования и которые могут потребовать дополнительного преобразования в соответствующий тип данных. В таких случаях используется свойство конфигурации numeric.mapping для преобразования числовых значений к наиболее подходящему типу примитива.
Таким образом, интеграция данных между разными СУБД с помощью source-коннектора JDBC Kafka – отличный непрерывной доставки информации без единой строчки кода. Однако, организовать потоковую передачу событий из таблиц базы данных только на нем одном с настройками по умолчанию невозможно из-за его специфических особенностей или ограничений [2]:
- помимо обнаружения новых строк в инкрементных столбцах, может быть изменена сама схема таблицы БД, что не всегда автоматически отражается в реестре схем;
- если в столбец добавлена новая строка, в таблице должен быть дополнительный столбец с меткой времени для обнаружения этих изменений и их добавления в топик Kafka;
- в случае удаления данных в строках таблица JDBC-коннектор отстает от события DELETE, используя SQL-запросы SELECT для извлечения данных.
Поэтому необходимо тщательно настраивать конфигурационные свойства source-коннектора JDBC Kafka, о чем мы поговорим в следующий раз. Про другой коннектор к Kafka от Confluent читайте в нашей новой статье. А как записать данные из GridDB в Apache Kafka через JDBC-коннектор, смотрите здесь.
Освоить на практике эти и другие тонкости администрирования и эксплуатации Apache Kafka для разработки распределенных приложений потоковой аналитики больших данных вам помогут специализированные курсы в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://gautambangalore.medium.com/data-ingestion-from-rdbms-by-leveraging-confluents-jdbc-kafka-connector-34a034fb841a
- https://docs.confluent.io/kafka-connect-jdbc/current/source-connector/index/

