
Сегодня заглянем под капот stateful-приложений Kafka Streams и рассмотрим, что такое RocksDB, как устроено это key-value NoSQL-хранилище и почему его необходимо настраивать для быстрой и безотказной работы приложений потоковой аналитики больших данных. Читайте далее, какие проблемы приложений Kafka Streams связаны с RocksDB и как ограничить повышенное потребление оперативной памяти. Что...

Продолжая добавлять в наши практические курсы по Apache Kafka и Spark еще больше интересных примеров, сегодня рассмотрим, как с помощью этих технологий Big Data анализировать метаданные сетевых потоков в реальном времени. В этой статье мы приготовили для вас кейс по потоковой аналитики больших данных о сетевом трафике с помощью Apache...

Чтобы добавить в наши практические курсы по Apache Kafka еще больше интересных примеров, сегодня рассмотрим кейс немецкой ИТ-компании Mobimeo, которая несколько раз перекраивала свою систему аналитики больших данных, чтобы быстро узнавать о событиях клиентских приложений. Читайте далее, зачем дата-инженеры Mobimeo предпочли AVRO формату JSON, почему вместо брокера сообщений ActiveMQ решили...

Один из факторов повышенной надежности Apache Kafka обеспечивается записью сообщений на жесткий диск. Однако, операции ввода-вывода (IO, input-output) с дисковым пространством считаются медленными и часто являются узким местом во всей системе. Спустившись на уровень операционной системы и ядра, сегодня рассмотрим, как Kafka справляется с этим ограничением, позволяя быстро обрабатывать огромные...

В этой статье разберем одну из тем практического обучения администраторов Apache Kafka и рассмотрим разницу между сохранением сообщений и фиксированных смещений в этой Big Data платформе потоковой обработке событий. Читайте далее про конфигурации потребителя и брокера, отвечающие за время хранения сообщений и политику очистки журналов. Еще раз про offset или...

В рамках обучения аналитиков Big Data и разработчиков Apache Spark и Kafka, сегодня рассмотрим кейс ИТ-компании Southworks по онлайн-обработке потокового видео как наглядный пример эффективного сочетания этих потоковых фреймворков с пакетными задачами. Читайте далее, как реализовать лямбда-архитектуру масштабируемой Big Data системы на базе Apache Kafka, Spark Structured Streaming и NoSQL-СУБД...

Вчера мы говорили про важные обновления Apache Kafka 2.8.0, помимо долгожданного KIP-500, который позволяет избавиться от Zookeeper для синхронизации метаданных в распределенном кластере с помощью встроенного Quorum Controller. Сегодня рассмотрим, какие KIP’ы нового релиза коснулись одного из основных инструментов разработчика Apache Kafka – библиотеки Streams для создания распределенных приложений потоковой...

KIP-500, который позволяет наконец-то избавиться от Zookeeper в кластере Apache Kafka, заменив его Quorum Controller – далеко не единственное важное обновление в релизе 2.8.0. Сегодня рассмотрим, какие еще улучшения реализованы в новой версии главной Big Data платформы потоковой обработки событий, выпущенной в апреле 2021 года. Apache Kafka 2.8.0: новинки главных...
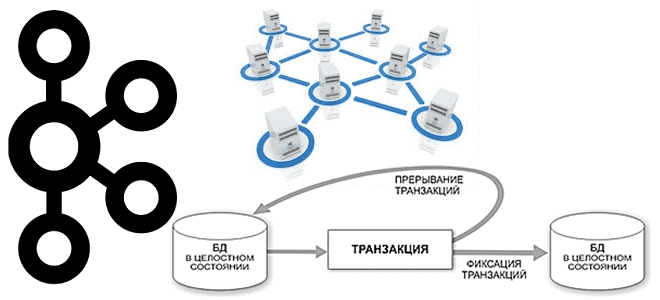
Продолжая говорить про обучение разработчиков и администраторов Apache Kafka, сегодня разберем сложности семантики строго однократной доставки сообщений (exactly once) в случае нескольких экземплярах, находящихся в разных кластерах. Читайте далее, что не так с межкластерными транзакциями, какие KIP’ы связаны с этой проблемой и при чем здесь MirrorMaker. Что не так с...
Сегодня рассмотрим важную тему из курсов для разработчиков и администраторов Apache Kafka: как сэкономить место на диске и увеличить пропускную способность всей Big Data системы на базе этой платформы потоковой обработки событий. Читайте далее, зачем добавлять задержку перед отправкой сообщений брокеру, как кодеки сжатия помогут снизить затраты на облачный Kafka-кластер...