Почему в хранилище и витрину данных могут попасть дубли, чем это чревато и какие встроенные механизмы дедупликации есть в ClickHouse. Примеры OPTIMIZE-запросов и работы с движком ReplacingMergeTree.
Причины дублирования данных и их последствия
Дублирование данных в хранилищах и в витринах – довольно частая проблема в дата-инженерии. Это приводит к росту затрат на инфраструктуру, поскольку при больших объемах информации дубли могут потреблять довольно ощутимые ресурсы. Однако, затраты на хранение и снижение скорости вычислений – не самые страшные последствия дубликатов. Гораздо более неприятна ситуация с нарушением целостности данных, т.е. их рассогласованием. Например, маркетологи и экономисты используют одни и те же данные о продажах, но с разным уровнем детализации и точности, эксплуатируя разные витрины данных, дубли в которых могут возникнуть по следующим причинам:
- ошибки на этапе ETL, когда одни и те же данные загружаются в хранилище несколько раз и/или из-за отсутствия механизмов отслеживания изменений обновленные записи добавляются как новые, вместо обновления существующих;
- недостаточная интеграция источников данных, когда различные источники данных используют разные способы идентификации записей, что приводит к их дублированию при интеграции. Особенно часто это происходит, если источники данных не согласованы в правилах очистки и стандартизации, что приводит к созданию схожих, хотя и не полностью идентичных записей.
- отсутствие или неправильная настройка уникальных ключей у вставляемых в хранилище записей;
- технические сбои в сети или системе, которые могут привести к повторной отправке данных, если успешная загрузка не подтверждена.
В итоге при наличии дублей аналитические выводы могут отличаться, снижая доверие к data-driven управлению. Поэтому дедупликация – один из важнейших этапов подготовки данных к загрузке в хранилища и витрины. Поскольку корпоративные DWH и витрины данных часто строятся на основе ClickHouse, о чем мы писали здесь, задача удаления дублей из этой колоночной базы, актуальная для многих дата-инженеров. Дубли в ClickHouse могут возникнуть дубли из-за асинхронной вставки данных, если нет дополнительных проверок на уникальность. Кроме того, при работе в кластере в случаях репликации данных между узлами возможны конфликты, приводящие к дублированию записей. Наконец, в отличие от реляционных баз данных, ClickHouse не поддерживает явные ограничения уникальности, что усложняет предотвращение дублирования на уровне базы данных.
Построение DWH на ClickHouse
Код курса
CLICH
Ближайшая дата курса
14 июля, 2025
Продолжительность
24 ак.часов
Стоимость обучения
72 000
Удаление дубликатов в ClickHouse встроенными механизмами на практическом примере
Впрочем, ClickHouse изначально содержит встроенные механизмы дедубликации. Одним из них является табличный движок ReplacingMergeTree, который выполняет удаление дублирующихся записей с одинаковым значением ключа сортировки, заданного с помощью оператора ORDER BY при DDL-запросе CREATE TABLE. Это не первичный ключ таблицы (PRIMARY KEY), который вообще может не задаваться при использовании определенных движков, таких как Log, TinyLog или Memory.
Возвращаясь к ReplacingMergeTree, отметим, что он выполняет удаление дублей только во время слияния частей данных для их более эффективного хранения. Слияние – это фоновый процесс, который запускается внутренними механизмами СУБД и явно не управляется, кроме запроса OPTIMIZE, что мы разберем далее. При этом некоторая часть данных может остаться необработанной. Явно вызвать внеочередное слияние можно с помощью запроса OPTIMIZE, который пытается запустить внеплановое слияние частей данных для таблиц. Он не устраняет причину появления ошибки Too many parts и работает только для таблиц семейства MergeTree, MaterializedView и Buffer, не поддерживая другие табличные движки.
Чтобы выполнить дедупликацию по произвольному набору столбцов с помощью запроса OPTIMIZE, можно явно указать список столбцов или использовать комбинацию выражений COLUMNS и EXCEPT. Список столбцов для дедупликации должен включать все столбцы, указанные в условиях сортировки (первичный ключ и ключ сортировки), а также в условиях партиционирования (ключ партиционирования). Например, следующий SQL-запрос в Clickhouse
OPTIMIZE TABLE customer DEDUPLICATE BY * EXCEPT (colX, colY);
запустит дедупликацию в таблице customer по всем столбцам, кроме материализованных выражений, псевдонимов и colX, colY.
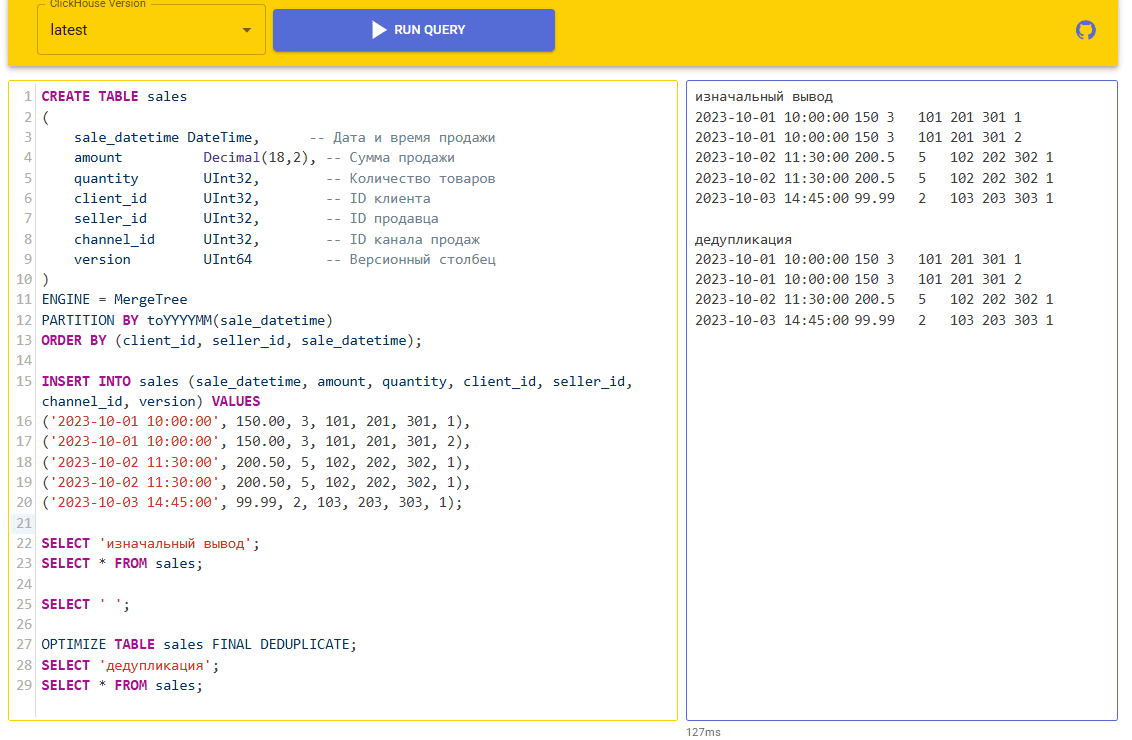
Если в OPTIMIZE-запросе не указаны столбцы, по которым нужно удалить дубли, то учитываются все столбцы таблицы. Строка удаляется только в том случае, если все значения во всех столбцах равны соответствующим значениям в другой строке. Например, создадим таблицу с данными о продажах и вставим туда строки с дублями.
CREATE TABLE sales
(
sale_datetime DateTime, -- Дата и время продажи
amount Decimal(18,2), -- Сумма продажи
quantity UInt32, -- Количество товаров
client_id UInt32, -- ID клиента
seller_id UInt32, -- ID продавца
channel_id UInt32, -- ID канала продаж
version UInt64 -- Версионный столбец
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(sale_datetime)
ORDER BY (client_id, seller_id, sale_datetime);
INSERT INTO sales (sale_datetime, amount, quantity, client_id, seller_id, channel_id, version) VALUES
('2023-10-01 10:00:00', 150.00, 3, 101, 201, 301, 1),
('2023-10-01 10:00:00', 150.00, 3, 101, 201, 301, 2),
('2023-10-02 11:30:00', 200.50, 5, 102, 202, 302, 1),
('2023-10-02 11:30:00', 200.50, 5, 102, 202, 302, 1),
('2023-10-03 14:45:00', 99.99, 2, 103, 203, 303, 1);
Затем выведем исходные данные и запустим дедупликацию с помощью OPTIMIZE. Чтобы ClickHouse выполнил полное объединение всех частей данных во всей таблице, а не только к видимой части данных, добавим к запросу модификатор FINAL, об особенностях работы которого мы писали здесь:
OPTIMIZE TABLE sales FINAL DEDUPLICATE;
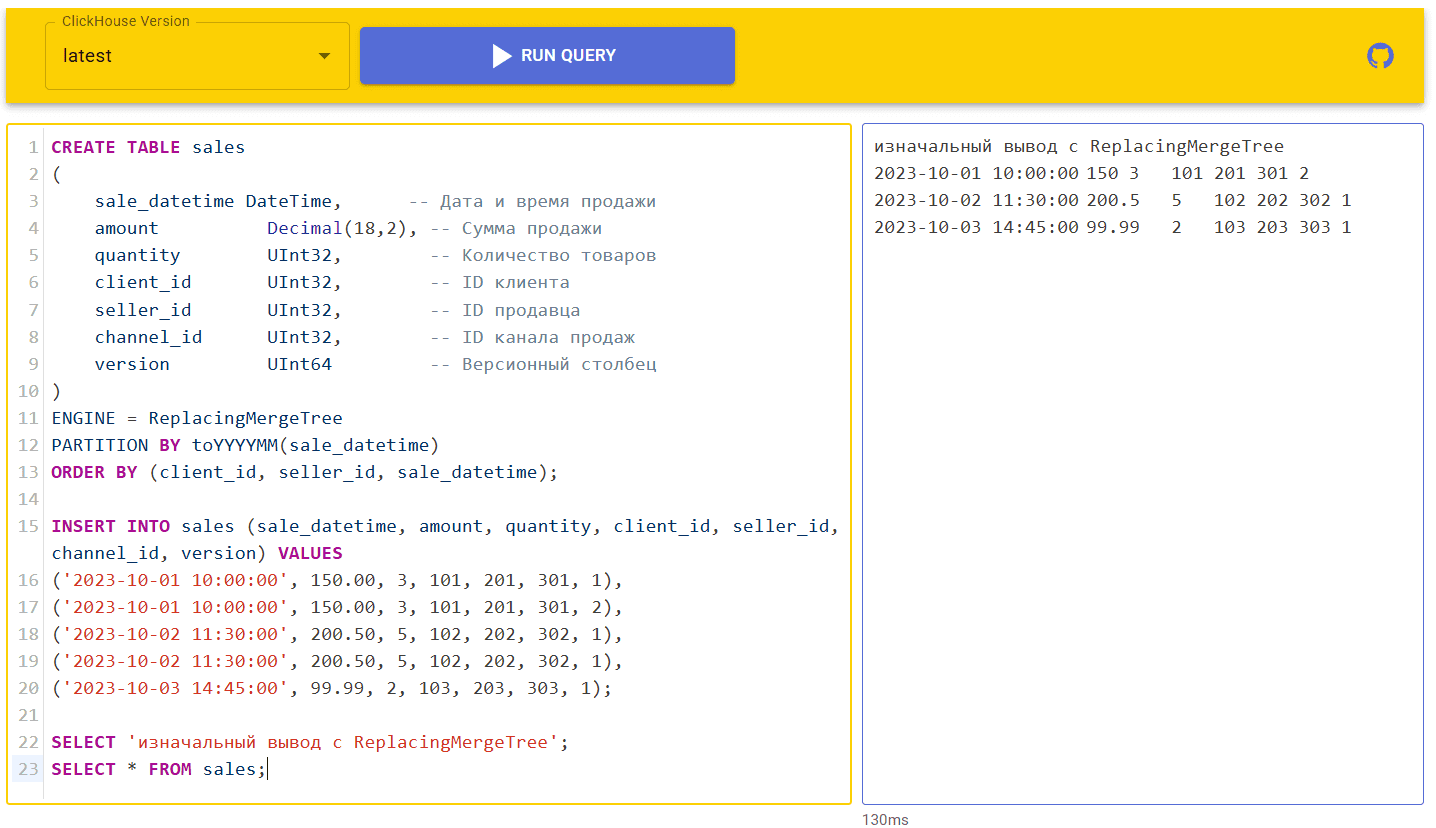
Хотя запрос OPTIMIZE работает, удаляя дубли, он приводит к чтению и записи большого объёма данных. При использовании движка ReplacingMergeTree дедупликация запускается в фоновом режиме в неизвестный момент времени, без гарантии отсутствия дублей в таблице в определенный момент времени. Кроме того, ReplacingMergeTree гарантирует отсутствие дублей во вставке (т. е. если в INSERT-запросе есть дубли — движок их удалит, и в таблицу попадут только уникальные значения). Изменим табличный движок в ранее рассмотренном примере.
CREATE TABLE sales
(
sale_datetime DateTime, -- Дата и время продажи
amount Decimal(18,2), -- Сумма продажи
quantity UInt32, -- Количество товаров
client_id UInt32, -- ID клиента
seller_id UInt32, -- ID продавца
channel_id UInt32, -- ID канала продаж
version UInt64 -- Версионный столбец
)
ENGINE = ReplacingMergeTree
PARTITION BY toYYYYMM(sale_datetime)
ORDER BY (client_id, seller_id, sale_datetime);
INSERT INTO sales (sale_datetime, amount, quantity, client_id, seller_id, channel_id, version) VALUES
('2023-10-01 10:00:00', 150.00, 3, 101, 201, 301, 1),
('2023-10-01 10:00:00', 150.00, 3, 101, 201, 301, 2),
('2023-10-02 11:30:00', 200.50, 5, 102, 202, 302, 1),
('2023-10-02 11:30:00', 200.50, 5, 102, 202, 302, 1),
('2023-10-03 14:45:00', 99.99, 2, 103, 203, 303, 1);
SELECT 'изначальный вывод с ReplacingMergeTree';
SELECT * FROM sales;
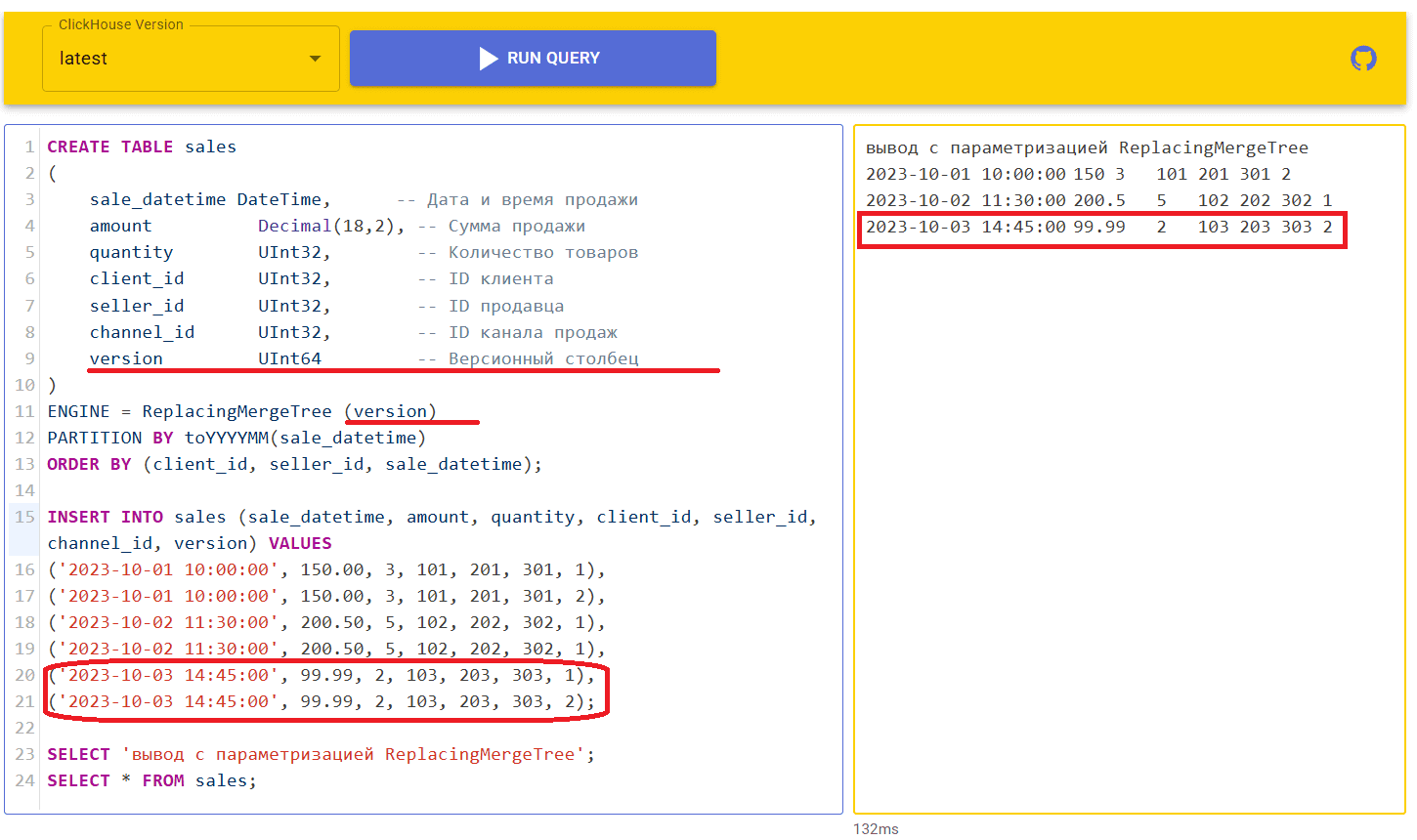
Работу с движком ReplacingMergeTree можно настроить, добавив параметр ver — столбец с номером версии, который имеет тип данных UInt*, Date, DateTime или DateTime64. При задании этого необязательного параметра ReplacingMergeTree оставляет только строку для каждого уникального ключа сортировки:
- последнюю в выборке, если параметр ver не задан. Под выборкой здесь понимается набор строк в наборе частей данных, участвующих в слиянии. Последняя по времени вставка данных будет последней в выборке. Поэтому после дедупликации для каждого значения ключа сортировки останется самая последняя строка из самой последней вставки.
- с максимальной версией, если параметр ver задан. Если он одинаковый у нескольких строк, то в результате слияния останется самая последняя строка из самой последней вставки.
Добавим параметризацию к ранее рассмотренному примеру:
CREATE TABLE sales
(
sale_datetime DateTime, -- Дата и время продажи
amount Decimal(18,2), -- Сумма продажи
quantity UInt32, -- Количество товаров
client_id UInt32, -- ID клиента
seller_id UInt32, -- ID продавца
channel_id UInt32, -- ID канала продаж
version UInt64 -- Версионный столбец
)
ENGINE = ReplacingMergeTree (version)
PARTITION BY toYYYYMM(sale_datetime)
ORDER BY (client_id, seller_id, sale_datetime);
INSERT INTO sales (sale_datetime, amount, quantity, client_id, seller_id, channel_id, version) VALUES
('2023-10-01 10:00:00', 150.00, 3, 101, 201, 301, 1),
('2023-10-01 10:00:00', 150.00, 3, 101, 201, 301, 2),
('2023-10-02 11:30:00', 200.50, 5, 102, 202, 302, 1),
('2023-10-02 11:30:00', 200.50, 5, 102, 202, 302, 1),
('2023-10-03 14:45:00', 99.99, 2, 103, 203, 303, 1),
('2023-10-03 14:45:00', 99.99, 2, 103, 203, 303, 2);
SELECT 'вывод с параметризацией ReplacingMergeTree';
SELECT * FROM sales;
Таким образом, ClickHouse позволяет избавиться от дубликатов записей с помощью встроенных механизмов: табличный движок ReplacingMergeTree и OPTIMIZE-запрос. Впрочем, это не отменяет необходимости выстраивать ETL-процесс так, чтобы в хранилище попадали качественные данные. Читайте в новой статье, почему при CDC-передаче данных из PostgreSQL в ClickHouse с помощью PeerDB возникают дубли и как их устранить.
ClickHouse для инженеров данных
Код курса
YACH
Ближайшая дата курса
в любое время
Продолжительность
24 ак.часов
Стоимость обучения
72 000
Научиться работать с ClickHouse вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

