 1021
1021 
Содержание
Сегодня поговорим про сохранение состояний при потоковой обработке больших данных с помощью Apache Spark и рассмотрим особенности Structured Streaming в новой версии этого популярного Big Data фреймворка. Читайте далее про Stateless и Stateful приложений в реальном времени, управление состояниями, связь DStream с RDD и UI в Spark Structured Streaming.
Состояния в потоковой обработке данных или что такое Stateful и Stateless
Напомним, потоковая обработка данных выполняется в реальном времени по мере их поступления и предполагает 2 способа выполнения [1]:
- без сохранения состояния (stateless), когда каждая входящая запись обрабатывается автономно не зависимо от других, например, отображение (map), фильтрация, объединение со статическими данными и прочие подобные операции.
- с сохранением состояния (stateful), когда обработка входящей записи зависит от результата ранее обработанных записей. Поэтому необходимо поддерживать промежуточную информацию между обработкой разных записей, чтобы каждая входящая запись читала и обновляла эти данные, которые называются состоянием (state). Примерами stateful-операций являются агрегирование количества записей по отдельному ключу, дедупликация и прочие действия с отслеживанием состояния.
В потоковой обработке выделяют 2 типа состояний [1]:
- состояние выполнения самого процесса (State of Progress) – метаданные, которые отслеживают информацию, уже обработанную в потоковом режиме. Обычно это называется контрольной точкой (checkpoint) или сохранением смещения (saving of offsets) входящих данных. Эта информация необходима для обеспечения отказоустойчивости в случае перезапуска, обновления или сбоя задачи и является минимальным гарантом надежной потоковой обработки больших данных.
- состояние данных в процессе потоковой обработки (State of Data) – промежуточная информация, полученная из обработанных на текущий момент данных, которую необходимо поддерживать между записями. Как правило, в контексте потоковой передачи данных, именно эта информация подразумевается под термином «состояние», если четко не указано о смещениях или состоянии выполнения.
На практике для хранения состояний используется соответствующее хранилище в различных видах, от базового HashMap в памяти до Apache Hadoop HDFS, Cassandra или RocksDb, которая используется в Apache Kafka Streams, о чем мы подробно рассказывали здесь и упоминали в этом материале. А как реализуется потоковая обработка в Apache Spark, мы рассмотрим далее.
Потоковая обработка в Apache Spark: до и после версии 2.3, веб-GUI 3.0
За потоковую обработку в Apache Spark отвечает механизм структурированной потоковой передачи (Structured Streaming) – масштабируемый и отказоустойчивый механизм на базе Spark SQL. Он позволяет использовать Dataset и DataFrame API в Scala, Java, Python или R для выражения потоковых агрегатов, временных окон обработки событий, соединений потока с пакетом. При этом Structured Streaming сам позаботится о постепенном и непрерывном запуске потоковых вычислений и обновит окончательный результат по мере поступления данных. Также система обеспечит сквозные строго однократные (exactly-once) гарантии отказоустойчивости с помощью контрольных точек и журналов упреждающей записи. Как обычно в Apache Spark, запросы структурированной потоковой передачи обрабатываются с помощью механизма микропакетной обработки (micro-batch), который обрабатывает потоки данных как серию небольших пакетных заданий. Сквозные задержки при этом составляют не более 100 миллисекунд с гарантией exactly-once, а начиная со Spark 2.3 — до 1 миллисекунды с гарантией как минимум один раз (at-least-once). Выбрать режим гарантии отказоустойчивости в запросах можно самостоятельно без изменения операций Dataset и DataFrame [2]. Подробнее о гарантиях доставки сообщений мы писали в этой статье на примере Apache Kafka.
Основная абстракция данных, которой оперирует Spark Streaming, называется дискретизированный поток (DStream) – непрерывная последовательность RDD (Resilient Distributed Dataset, надежная распределенная коллекция типа таблицы). RDD представляет собой функциональную структуру данных в виде набора объектов Java или Scala, о чем мы рассказывали здесь. DStreams могут быть созданы в реальном времени из Apache HDFS, Kafka или Flume, а также путем преобразования существующих DStreams с помощью операций map, window и reduceByKeyAndWindow. Во время выполнения программы Spark Streaming каждый DStream периодически генерирует RDD из оперативных данных или преобразует RDD, созданный родительским DStream [3].
Интересно, что в старых версиях Apache Spark Streaming (до 2.3.) управление состоянием было не совсем эффективным из-за двух основных ограничений [1]:
- в каждом микропакете состояние сохранялось вместе с метаданными контрольной точки — смещениями или ходом потоковой передачи. Эти данные записывались в конце каждого микропакета, даже если в состоянии не было никаких изменений. Более того, не было предусмотрено инкрементальной сохранности данных состояния. Каждый раз моментальный снимок всего состояния сериализовался и сохранялся в хранилище, вместо того, чтобы сохранять только ту часть состояния, которая изменилась.
- Сохранение состояния в хранилище было тесно связано с задачами и заданиями Spark RDD. Эта синхронность вызывала дополнительные накладные расходы, связанные с задержкой обработки, а также потерю ресурсов.
Оба этих ограничения вызвали серьезные проблемы с производительностью, особенно при увеличении размера состояния. Поэтому начиная с версии Apache Spark 2.3 управление состоянием отделено от контрольных точек метаданных, больше не является частью заданий и задач, выполняется асинхронно с RDD и поддерживает инкрементное сохранение состояния. Поскольку Apache Spark является частью экосистемы Hadoop, логично, что в качестве хранилища состояний используется распределенная файловая система HDFS [1].
В частности, при запуске потоковых запросов, где требуется сквозная отказоустойчивость, необходимо указать расположение контрольных точек (Checkpoint location), куда система будет записывать всю информацию о них. Это должен быть каталог в отказоустойчивой файловой системе, совместимой с HDFS. Этот параметр может быть установлен в качестве опции в DataStreamWriter при запуске запроса. Например, на языке Python это будет выглядеть следующим образом [2]:
aggDF \
.writeStream \
.outputMode("complete") \
.option("checkpointLocation", "path/to/HDFS/dir") \
.format("memory") \
.start()
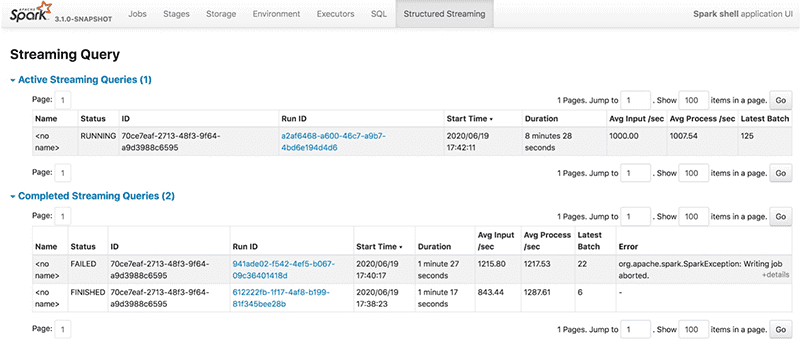
Чтобы облегчить процесс разработки Big Data приложений, в новой версии Apache Spark 3.0 был введен наглядный веб-GUI для Structured Streaming. Он обеспечивает мониторинг всех потоковых заданий, отображая статистику и информацию для отладки в реальном времени с помощью 2-х набор статистических данных [4]:
- агрегированные сведения о задании потокового запроса (streaming query job);
- подробную информацию о потоковых запросах, включая Input Rate, Process Rate, Input Rows, Batch Duration, Operation Duration и т.д.
Больше деталей по применению Apache Spark для аналитики больших данных в проектах цифровизации частного бизнеса, а также государственных и муниципальных предприятий, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Потоковая обработка в Apache Spark
- Анализ данных с Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
[elementor-template id=»13619″]
Источники
- https://medium.com/@chandanbaranwal/state-management-in-spark-structured-streaming-aaa87b6c9d31
- https://spark.apache.org/docs/3.0.0-preview/structured-streaming-programming-guide/
- https://spark.apache.org/docs/0.7.3/api/streaming/spark/streaming/DStream/
- https://databricks.com/blog/2020/07/29/a-look-at-the-new-structured-streaming-ui-in-apache-spark-3-0/

