В этой статье поговорим про интеграцию данных с помощью CDC-подхода и репликацию SQL-таблиц из корпоративной СУБД в несколько разных удаленных хранилищ в реальном времени с применением Apache Kafka и Debezium, развернутых в Kafka Connect и Confluent Cloud.
Постановка задачи: CDC с Big Data в реальном времени
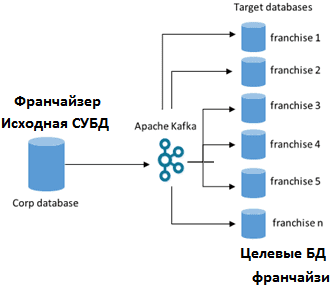
Рассмотрим кейс, который часто встречается в реальной жизни: головному офису предприятия с распределенной структурой требуется оперативно передать данные из своей корпоративной СУБД в удаленные филиалы. В разбираемом примере франчайзеру нужно реплицировать несколько таблиц из своего хранилища данных в системы разных франчайзи в реальном времени. При этом такая односторонняя интеграция должна обрабатывать репликацию большого количества обновлений, внесенных в таблицы исходной СУБД, с возможностью масштабирования по мере роста сети франчайзи, т.е. увеличения числа целевых баз-приемников данных [1].
Для решения подобной задачи целесообразно использовать концепцию CDC – захват изменения данных (Сhange Data Capture), который представляет собой набор шаблонов разработки ПО для определения и отслеживания данных, которые изменились. По сути, CDC — это подход к интеграции данных, основанный на идентификации, регистрации и доставке изменений в корпоративных источниках данных во внешние системы. CDC можно применять в любой базе или хранилище данных. Технически это реализуется с помощью табличных триггеров, отметок времени или номеров версий в строках таблиц СУБД, сканирования лог-файлов или обработки событий [2]. Подробнее об этом читайте в нашей новой статье.
Возвращаясь к рассматриваемому примеру, подчеркнем 2 особенности, которые обусловливают необходимость использования соответствующих технологий стека Big Data:
- работа с большими объемами данных;
- потоковая передача информации (обработка в режиме реального времени).
С учетом этих особенностей и первоочередной потребности в интеграции данных из всего множества технологий Big Data имеет смысл выбрать Apache Kafka – распределенную отказоустойчивую платформу потоковой обработки событий. Кроме того, благодаря модели работы «издатель-подписчик» и возможности работать с данными фактически любого формата за счет реестра схем (Schema Registry), Kafka отлично подходит для построения интеграционных систем, о чем мы уже рассказывали здесь. Однако, помимо Kafka в данном кейсе также было решено использовать потоковую CDC-систему Debezium, о которой мы поговорим далее.
Администрирование кластера Kafka
Код курса
KAFKA
Ближайшая дата курса
14 апреля, 2025
Продолжительность
24 ак.часов
Стоимость обучения
72 000 руб.
Что такое Debezium и при чем здесь Apache Kafka
Debezium — это распределенная платформа с открытым исходным кодом для сбора измененных данных, которая постоянно отслеживает исходные базы и позволяет любому приложению передавать каждое изменение на уровне строки в том же порядке, в котором они были внесены в первоисточнике. Debezium основан на Apache Kafka, что позволяет использовать ключевые преимущества этой Big Data платформы: отказоустойчивость, масштабируемость и надежную обработку больших объемов данных в реальном времени.
Архитектура Данных
Код курса
ARMG
Ближайшая дата курса
19 мая, 2025
Продолжительность
24 ак.часов
Стоимость обучения
72 000 руб.
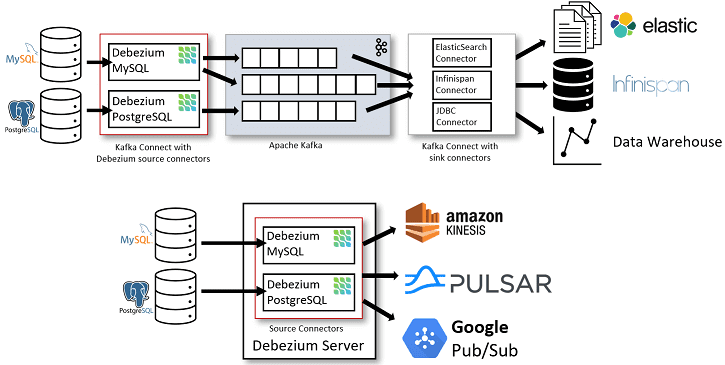
Обычно Debezium используется, чтобы позволить различным приложениям почти немедленно реагировать на изменение данных в СУБД: события вставки, обновления и удаления, включая отправку push-уведомлений на одно или несколько мобильных устройств, агрегацию изменений и генерацию потока исправлений для объектов. Debezium распределяет процессы мониторинга или коннекторы между несколькими узлами, реплицируя события, чтобы минимизировать риск потери информации. Принцип работы Debezium как набора коннекторов для различных СУБД, совместимых с фреймворком Apache Kafka Connect, можно представить следующим образом [3]:
- коннекторы источников данных Debezium отправляют записи в Apache Kafka, причем по умолчанию изменения одной таблицы СУБД записываются в топик Kafka, имя которого соответствует имени таблицы;
- после того, как записи о событиях изменений находятся в Apache Kafka, различные коннекторы приемников Debezium в экосистеме Kafka Connect могут передавать записи в другие базы и хранилища данных, системы аналитики или кэши.
- Сервер Debezium настроен на использование одного из исходных коннекторов Debezium для сбора изменений из исходной базы данных. События изменений могут быть сериализованы в форматы JSON или Apache Avro, а затем отправлены в инфраструктуру обмена сообщениями: Amazon Kinesis, Google Cloud Pub/Sub, Apache Pulsar или Kafka.
Альтернативным способом использования коннекторов Debezium является встроенный движок, когда система запускается не через Kafka Connect, а как библиотека пользовательского Java-приложения. Это может пригодиться для использования событий изменения данных в самом приложении без развертывания полных кластеров Kafka и Kafka Connect или в случае потоковой передачи изменений в альтернативные брокеры обмена сообщениями: AWS Kinesis, Google Cloud Pub/Sub, Apache Pulsar. Подробнее о практическом применении AWS Kinesis читайте в нашей новой статье.
CDC-репликация больших данных с коннекторами Debezium в Confluent Cloud
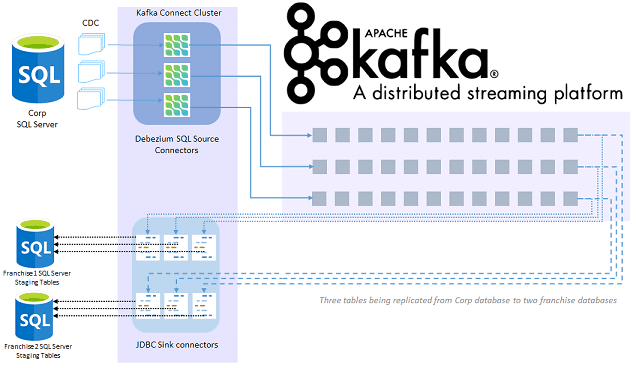
Таким образом, рассматриваемый кейс потоковой репликации данных из головной СУБД в филиальные сводится к следующей последовательности действий [1]:
- включить отслеживание измененных данных (CDC) в исходной базе данных SQL и в таблицах, которые нужно реплицировать;
- настройка коннектор источника Debezium для чтения обновлений CDC с сервера SQL и отправки обновлений CDC в разделы топиков Kafka;
- настройка коннекторов приемника JDBC для извлечения данных из топиков Kafka и отправки обновлений в целевые базы данных.
В рассматриваемом примере Apache Kafka использовался в рамках облачной платформы Confluent Cloud, которая по умолчанию не поставляет коннектор Debezium и драйвер SQL JDBC, нужный коннектору JDBC-приемника для записи в целевую SQL-СУБД. Поэтому jar-файл SQL-драйвера JDBC был помещен в папку kafka-connect-jdbc. А для оптимизации размера сообщения, записываемого в Kafka, данные представлялись в формате Avro с помощью реестр управляемых схем от Confluent Cloud.
Примечательно, что Confluent Cloud и другие управляемые поставщики данных Kafka не позволяют клиентам автоматически создавать топики. Поэтому требовалось создать топики для запуска Kafka Connect, работы коннекторов Debezium и фактической репликации данных. Создавая исходный коннектор Debezium для чтения данных из SQL-таблиц и заполнения обновлений CDC в виде сообщений топика, соответствующей исходной таблице, стоит особенно обратить внимание на следующие атрибуты [1]:
- table.whitelist, чтобы сообщить Debezium, из какой таблицы с поддержкой CDC следует читать данные. Можно указать несколько таблиц, используя список, разделенный запятыми или создать отдельный коннектор для каждой таблицы, чтобы их приостанавливать, возобновлять или перезапускать их по отдельности.
- snapshot, initial-значение для которого запустит заполнение топика Kafka коннектором Debezium всеми записями в исходной базе данных, как только коннектор будет создан. Например, если в исходной таблице 1000 записей, то в топике Kafka, соответствующей таблице, появится 1000 сообщений в течение нескольких секунд после создания коннектора. По мере того, как сообщения проходят через платформу Kafka Connect, они могут быть преобразованы с помощью преобразования отдельных сообщений (SMT, Single Message Transforms).
- Преобразование ExtractNewRecordState transform – SMT-преобразователь, предоставляемый Debezium по умолчанию, который можно настроить в исходном коннекторе, чтобы сообщение преобразовывалось еще до того, как оно будет сохранено в теме Kafka, или в коннекторе приемника, чтобы сообщение преобразовывалось непосредственно перед сохранением в целевой базе.
- Преобразование RegexRouter — SMT для указания топика, куда коннектор будет записывать сообщения. По умолчанию Debezium выполняет запись в топик с именем, которое соответствует формату <databaseServer>.<schemaName>.<tableName>.
Аналогичным образом перечислим наиболее важные атрибуты в коннекторе-приемнике [1]:
- topics, чтобы указать, из каких топиков коннектор приемника будет извлекать данные. Можно иметь отдельный коннектор для каждого топика или общий для чтения из всех, перечислив их в списке, разделенном запятыми. Например, при репликации данных в 100 франчайзинговых приемников, будет 100 sink-коннекторов, каждый из которых соответствует одной базе данных.
- name.format, чтобы указать, в какую таблицу-приемника данных будет происходить запись. Вместо фактического имени таблицы можно задать целевое назначение на основе имени топика <databaseName>.{Topic}. Например, если имя базы данных — «franchise1», а коннектор приемника читает из топика с именами dbo.Product и dbo.ProductPrice, он будет записывать в таблицы franchise1.dbo.Product и franchise1.dbo.ProductPrice.
- fetch.min.bytes и consumer.fetch.wait.max.ms позволят задать пропускную способность коннектора приемника.
Таким образом, после настройки коннекторов источника и приемника все обновления, внесенные в таблицы исходной базы данных, реплицируются в несколько целевых СУБД. Впрочем, прежде чем использовать коннекторы Kafka Connect для CDC-сценариев, следует внимательно рассмотреть их ограничения, о которых мы рассказываем здесь.
Другой пример реализации CDC-подхода на Kafka и Debezium мы рассматриваем в кейсе построения OLAP-системы реального времени с Apache Pinot. О том, как компания Confluent выпустила корпоративный CDC-коннектор Kafka к Oracle, читайте в нашей новой статье. Чтобы наглядно показать, как настроить интеграцию PostgreSQL с Kafka, я реализовала коннектор Debezium на serverless-платформе Upstash и подробно описала всю последовательность действий.
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
25 июня, 2025
Продолжительность
24 ак.часов
Стоимость обучения
72 000 руб.
А подробнее узнать все особенности администрирования кластеров и разработки Kafka-приложений для аналитики больших данных, вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- https://medium.com/@shiva.prathipati/real-time-database-replication-using-kafka-d9e7a592e476
- https://ru.wikipedia.org/wiki/Захват_изменения_данных
- https://debezium.io/documentation/reference/architecture.html