 1477
1477 
Содержание
Есть мнение, что использование Apache Kafka в качестве корпоративной сервисной шины (ESB, Enterprise Service Bus) является антипаттерном. Сегодня мы проясним это категоричное утверждение и рассмотрим, как корректно реализовать ESB с помощью Kafka на практическом примере шины данных в компании Avito.ru.
Что такое ESB и чем это отличается от брокера сообщений
Напомним, ESB относится к SOA-концепции (Service Oriented Architecture) и представляет собой элемент IT-ландшафта для интеграции разрозненных информационных систем в единый программный комплекс с централизованным управлением передачей информации и применением сервис-ориентированного подхода. Как правило, ESB включает следующие компоненты [1]:
- набор коннекторов для подключения к различным системам с целью приема и отправки данных;
- очередь сообщений (Message Queue, MQ) для организации промежуточного хранения сообщений в ходе их доставки;
- платформа, которая связывает коннекторы с очередью, а также организует асинхронную передачу информации между источниками и приемниками с гарантированной доставкой сообщений и возможностью их трансформации.
Таким образом, брокер сообщений является частью ESB-решения, которое в целом обеспечивает мониторинг и контроль маршрутизации обмена сообщениями между сервисами на основе контента, разрешая конфликты между ними. Также ESB позволяет управлять развертываниями и версиями сервисов. Поэтому постановка вопроса «Apache Kafka vs ESB» не совсем корректна: Кафка дополняет ESB, выступая в качестве масштабируемой отказоустойчивой стриминговой платформы, что особенно актуально для высоконагруженных распределенных Big Data систем [2].
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
18 мая, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Шина данных и Apache Kafka: рекомендации и антипаттерны
Подчеркнем, что при построении корпоративной шины данных не рекомендуется встраивать в нее логику интеграции или бизнес-логику, т.к. это приведет к исчезновению масштабируемости, гибкости и независимости от различных систем. В частности, используя экосистему Kafka для создания приложений с помощью Kafka Streams, KSQL или любого клиента Kafka (Java, .Net, Python или Go), не следует пытаться создать новую ESB на основе Kafka. Именно такая лишенная гибкости централизация считается антипаттерном для применения этой Big Data системы. Наоборот, нужно обеспечить всем компонентам Kafka гибко взаимодействовать с группами продуктов и сервисов [3].
Именно в таком ключе перед разработчиками компании Avito и была поставлена задача создания корпоративной шины данных (service data bus), реализацию которой мы рассмотрим далее. Этот кейс был наглядно представлен сотрудником компании Антоном Суховым на 5-м Backend-митапе Авито в декабре 2019 года [4].
Кафка и шина данных на пример Авито: self-service для эффективной интеграции
Основными бизнес-требованиями к корпоративной шине данных в Авито были следующие [4]:
- критичность данных (нельзя ничего потерять);
- возможность повторного воспроизведения событий за несколько дней;
- масштабирование на 3 датацентра в будущем.
Из требований к решению наиболее значимыми считались:
- поддержка разных схем данных (событий);
- обеспечение как минимум однократной доставки сообщений (at least once);
- работа по принципу «издатель-подписчик» (publisher-subscriber);
- возможность полного контроля над всей системой и каждым ее компонентом в отдельности;
- быстрота обновлений;
- простота интеграции между различными сервисами.
С учетом этих требований было решено проектировать систему следующим образом:
- различные сервисы подключаются к шине данных через универсальный лаконичный API;
- шина данных напрямую взаимодействует с хранилищем, которое может быть любым, однако в этом конкретном случае выбрана Apache Kafka;
- с учетом универсального подхода к API и хранилища следует скрыть их особенности реализации, инкапсулировав их так, что пользователю они предоставляются в режиме самообслуживания (self-service) через шину данных.
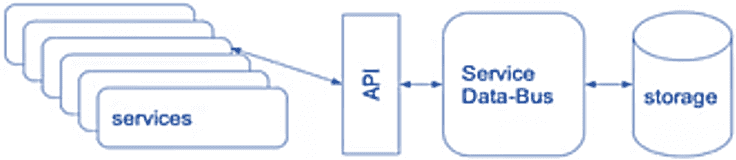
Интересен выбор протокола для API шины данных: HTTP/RPC или WebSocket — протокол связи поверх TCP-соединения, предназначенный для обмена сообщениями между браузером и веб-сервером в режиме реального времени [5]. Выбор протокола определялся используемыми методами обмена данными:
- записать данные – produce (clientID, topic, []Message);
- прочитать данные – consume (clientID, topic, offset) []Message;
При том смещение (offset) может указывать на самую старую запись (oldest), самую новую (newest), или вычисляться по метке времени (timestamp).
В пользу HTTP/RPC выступает возможность кодогенерации клиента и сервиса, однако этот протокол не подходит из-за рассинхронизации между репликами, развернутыми в Kubernetes , при выполнении consume-запросов. Избежать этого позволит превращение решения из stateless в stateful, что значительно усложняет реализацию. Поэтому разработчики Авито решили использовать протокол WebSocket. В итоге система работает следующим образом:
- при первом обращении к шине данных выполняется аутентификация и авторизация сервиса;
- через интерфейс хранилища идентифицируется нужный топик Kafka для чтения или записи данных;
- механизм групп получателей сообщений (consumer group) позволяет реализовать считывание одних и тех же данных разными клиентами;
- валидация данных выполняется на клиенте.
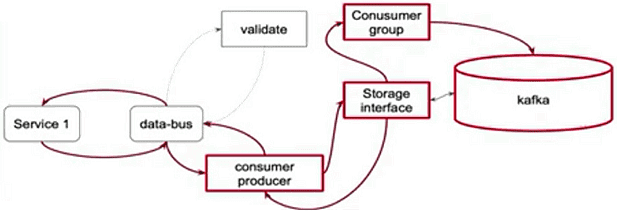
Таким образом, шина данных обеспечивает простую работу с Apache Kafka в режиме self-service, предоставляя все преимущества этой Big Data системы, но скрывая от пользователя специфические особенности ее работы. Аналогичный подход к самообслуживанию мы недавно описывали на примере администрирования кластеров Apache Kafka в Booking.com, рассматривая доклад Александра Миронова, представленный на зимнем Кафка-митапе Авито в январе 2020 года. Напомним, подробности реализации шины данных компании Авито изложены в видеодокладе ее ведущего разработчика Антона Сухова [4].
Apache Kafka: администрирование кластера
Код курса
KAFKA
Ближайшая дата курса
8 июня, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
А технические детали эксплуатации ApacheKafka для потоковой обработки больших данных в проектах цифровизации своего бизнеса, а также государственных и муниципальных предприятий, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- http://www.sovtex.ru/products/esb/
- https://www.quora.com/How-does-Kafka-differ-from-an-Enterprise-service-bus-Do-they-solve-the-same-problems
- https://www.confluent.io/blog/apache-kafka-vs-enterprise-service-bus-esb-friends-enemies-or-frenemies/
- https://habr.com/ru/company/avito/blog/479952/
- https://ru.wikipedia.org/wiki/WebSocket

