Как использовать DataStream API в Apache Flink: пишем потребителя из Kafka и запускаем скрипт в Google Colab. StreamExecutionEnvironment и методы коллекций потока данных в PyFlink.
DataStream API в Apache Flink: PyFlink в Google Colab для работы с Kafka
Apache Flink предоставляет множество возможностей разработчикам на Scala и Java, а также имеет Python API, который существенно ограничен. Подробнее о том, как он устроен, читайте здесь. Тем не менее, он поддерживает табличную и потоковую обработку данных, что мы и рассмотрим сегодня. В качестве примера я написала небольшой PyFlink-скрипт работы с потоком данных, потребленным из топика Apache Kafka, развернутого в облачной бессерверной платформе Upstash. О том, как создать свой инстанс Kafka в Upstash, а также написать свой Python-продюсер и потребитель, я подробно рассказывала в статье блога нашей Школы прикладного бизнес-анализа.
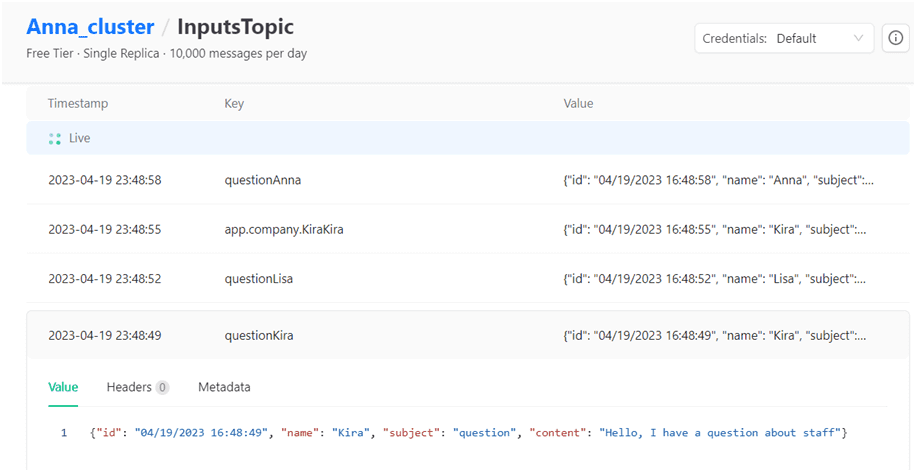
В топике с именем InputsTopic содержатся данные о клиентских заявках в виде JSON-документов, например, такие:
{
"id": "04/19/2023 16:51:04",
"name": "Anna",
"subject": "app",
"content": "cacao 40"
}
Далее напишем PyFlink-скрипт работы с данными, используя API DataStream, который включает методы преобразования потоков данных, например, фильтрацию, обновление состояния, оконные операции, агрегирование. Потоки данных создаются из различных источников (очередей сообщений, сокетов, файлов). В нашем случае источником данных будет полезная нагрузка сообщений, потребленных из Kafka. Результаты возвращаются через приемники, которые могут записывать данные в файлы или на стандартный вывод, такой как терминал командной строки или окно вывода в интерактивной среде Google Colab.
Справедливости ради стоит отметить, что в моем скрипте потребление из топика Kafka реализовано методами клиентской библиотеки kafka-python вместо FlinkKafkaConsumer из библиотеки pyflink.datastream.connectors из-за сложности с зависимостями. Поскольку я пишу и запускаю скрипты в интерактивной среде Goggle Colab, возможности по настройке путей к JAR-файлу коннектора Flink-Kafka ограничены. Как побороть это ограничение, смотрите в новой статье.
В первой ячейке блокнота установим необходимые библиотеки и импортируем нужные модули. Под капотом PyFlink использует Java для выполнения всей потоковой обработки и вычислений. Поэтому в Colab-блокнот следует установить пакет Java.
####################################ячейка в Google Colab №1 - установка и импорт библиотек########################################### #установка библиотек !pip install kafka-python !apt-get install openjdk-8-jdk-headless -qq > /dev/null !pip install apache-flink #импорт модулей import json from kafka import KafkaConsumer from json import loads from pyflink import datastream from pyflink.datastream import StreamExecutionEnvironment
В следующей ячейке создадим потребитель из Kafka, подпишем его на нужный топик, создадим потоковую среду исполнения API DataStream и в цикле потребления сообщений создадим потоковую коллекцию данных.
####################################ячейка в Google Colab №2 – потребление и обработка данных###########################################
#создание потребителя Kafka
consumer = KafkaConsumer(
bootstrap_servers=['название вашего экземпляра Kafka:номер порта, обычно 9092'],
sasl_mechanism='SCRAM-SHA-256',
security_protocol='SASL_SSL',
sasl_plain_username='имя вашего пользователя',
sasl_plain_password='пароль вашего пользователя',
group_id='gr1',
auto_offset_reset='earliest',
enable_auto_commit=True
)
# создание Streaming Environment
environment = StreamExecutionEnvironment.get_execution_environment()
#подписка на топик Kafka
consumer.subscribe(['InputsTopic'])
for message in consumer:
print (message)
payload=message.value.decode("utf-8")
data=json.loads(payload)
#создание потока данных со списком
data_stream = environment.from_collection(
collection = data.values()
)
#сбор данных из потока
with data_stream.execute_and_collect() as results:
for result in results:
print(result)
Поскольку в этом скрипте задан бесконечный цикл потребления, останавливать его будем вручную. А отписку потребителя от топика и закрытие соединения выполним в отдельной ячейке:
####################################ячейка в Google Colab №3 - закрытие соединения########################################### #Закрываем соединения consumer.unsubscribe() consumer.close()
Ядром программы API DataStream является StreamExecutionEnvironment – контекст, в котором выполняется программа потоковой передачи. Локальная среда исполнения потоковой обработки (LocalStreamEnvironment) предполагает выполнение программы в текущей JVM, а удаленная (RemoteStreamEnvironment) вызывает выполнение на удаленной установке. Эта среда исполнения предоставляет методы управления выполнением задания (установка параметров параллелизма, контрольных точек, точек сохранения) и взаимодействия с внешним миром (доступ к данным). Однако, как уже было отмечено ранее, возможности Python APi сильно ограничены по сравнению со Scala и Java. Например, мне не удалось вручную задать директорию хранения контрольных точек из-за отсутствия этих методов в Python API.
DataStream похож на обычную коллекцию Python с точки зрения использования, но потоковые коллекции Flink являются неизменяемыми. Это означает, что после их создания нельзя добавлять или удалять элементы. Также нельзя просто инспектировать элементы внутри – можно лишь работать с ними с помощью операций DataStream API, которые называются трансформациями.
Создать исходный поток данных, можно добавив источник в PyFlink, чтобы получить из него новые потоки и обработать их с помощью методов API, таких как map(), filter() и пр. Например, метод execute_and_collect(), используемый в ранее приведенном скрипте, собирает данные DataStream в память клиента. Поэтому при работе с этим методом рекомендуется ограничить количество собираемых строк.
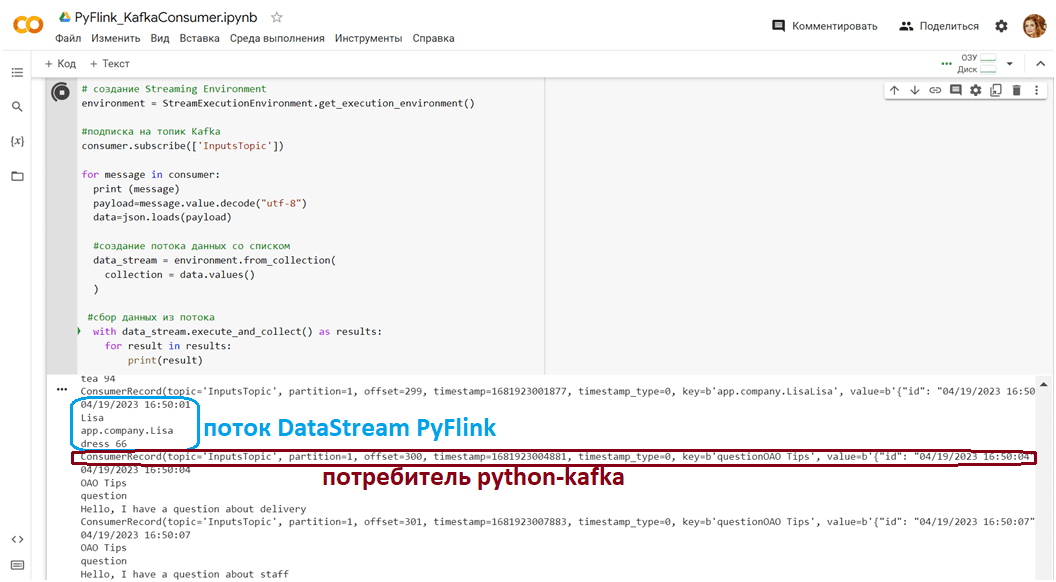
Визуально потребленные из Kafka данные и поток DataStream API Flink показываются в области вывода Goggle Colab.
Также динамика работы с топиком видна в GUI платформы Upstash.
Разумеется, рассмотренный пример не показывает всех возможностей DataStream API Apache Flink. В частности, поток данных можно трансформировать в таблицу, чтобы использовать функции Table API, соединять потоки друг с другом или с табличными данными, создавать новые потоки и т.д. Однако, надеюсь, что этот небольшой скрипт поможет познакомиться с основными понятиями потоковой обработки в Apache Flink и понять, как запустить PyFlink-программу в интерактивном блокноте Google Colab.
Узнайте больше про применение Apache Flink и Kafka для потоковой обработки событий в распределенных приложениях аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Потоковая обработка данных с помощью Apache Flink
- Apache Kafka для инженеров данных
- Администрирование Arenadata Streaming Kafka
Источники