
Сегодня рассмотрим, как написать и запустить в Google Colab свое Python-приложение считывания данных из топика Kafka с помощью коннектора FlinkKafkaConsumer из библиотеки pyflink.datastream.connectors и почему заставить его работать оказалось не так просто.
Использование FlinkKafkaConsumer для доступа к Kafka из Flink приложения
Недавно я показывала, как написать PyFlink-скрипт считывания данных из топика Apache Kafka, развернутого в облачной бессерверной платформе Upstash. Подробнее о том, как устроен Python API Apache Flink, читайте здесь. Однако, в тот раз вместо FlinkKafkaConsumer из библиотеки pyflink.datastream.connectors я использовала класс Consumer библиотеки kafka-python, поскольку не загрузила JAR-файл коннектора Flink-Kafka. Загрузить этот пакет поможет инструкция
!wget https://repo.maven.apache.org/maven2/org/apache/flink/flink-sql-connector-kafka/1.17.1/flink-sql-connector-kafka-1.17.1.jar
При работе в интерактивной среде Google Colab файл коннектора загружается в текущую рабочую директорию, которая по умолчанию находится в папке /content/. Помимо этого, для работы с коннектором Flink к Kafka также необходимо установить целый ряд библиотек и импортировать некоторые их модули:
####################################ячейка в Google Colab №1 - установка и импорт библиотек########### #установка библиотек !pip install kafka-python !apt-get install openjdk-8-jdk-headless -qq > /dev/null !pip install apache-flink #импорт модулей from kafka import KafkaConsumer from pyflink import datastream from pyflink.datastream import StreamExecutionEnvironment from pyflink.datastream.connectors import FlinkKafkaConsumer from pyflink.common.typeinfo import Types from pyflink.datastream.formats.json import JsonRowDeserializationSchema !wget https://repo.maven.apache.org/maven2/org/apache/flink/flink-sql-connector-kafka/1.17.1/flink-sql-connector-kafka-1.17.1.jar
Чтобы запустить Flink-приложение необходимо сперва создать StreamExecutionEnvironment – контекст, в котором выполняется программа потоковой передачи. Причем в Colab мне пришлось явно задавать JAR-пакет коннектора, ранее установленного с помощью команды !wget:
env = StreamExecutionEnvironment.get_execution_environment()
env.add_jars("file:////content/flink-sql-connector-kafka-1.17.1.jar")
После этого можно создать объект класса FlinkKafkaConsumer, передав в параметрах название топика, учетные данные для подключения к серверу Kafka и схему десериализации сообщений:
kafka_consumer = FlinkKafkaConsumer(
topic,
deserialization_schema=json_format,
properties=kafka_properties
)
Схема десериализации определена с помощью строк
row_type_info = Types.ROW_NAMED(['id', 'name', 'subject', 'content'],[Types.STRING(), Types.STRING(), Types.STRING(), Types.STRING()]) json_schema = JsonRowDeserializationSchema.builder().type_info(row_type_info).build()
Flink поддерживает чтение/запись записей JSON с помощью класса JsonRowDeserializationSchema, который находится в пакете pyflink.datastream.formats.json – именно поэтому ранее понадобился импорт этого модуля.
Весь код PyFlink-приложения выглядит так:
####################################ячейка в Google Colab №2 - код PyFlink-приложения#####################
#Создание словаря с настройками для подключения к серверу Kafka
kafka_properties = {
"bootstrap.servers": kafkaserver, # адрес сервера Kafka
"sasl.mechanism": "SCRAM-SHA-256", # механизм аутентификации
"security.protocol": "SASL_SSL", # протокол безопасности
"sasl.jaas.config": f'org.apache.kafka.common.security.scram.ScramLoginModule required username="{user_name}" password="{user_pass}";' # параметры аутентификации
}
#Получение среды выполнения PyFlink
env = StreamExecutionEnvironment.get_execution_environment()
#Добавление в среду выполнения JAR-файла с коннектором Flink для Kafka
env.add_jars("file:////content/flink-sql-connector-kafka-1.17.1.jar")
#Создание объекта схемы данных для десериализации JSON-строк
row_type_info = Types.ROW_NAMED(['id', 'name', 'subject', 'content'], [Types.STRING(), Types.STRING(), Types.STRING(), Types.STRING()])
json_schema = JsonRowDeserializationSchema.builder().type_info(row_type_info).build()
#Создание источника данных, который будет считывать сообщения из Kafka
source = FlinkKafkaConsumer(
topic, # название топика
deserialization_schema=json_schema, # схема десериализации
properties=kafka_properties # настройки для подключения к серверу Kafka
)
#Начало чтения сообщений с самого начала топика
source.set_start_from_earliest()
#Добавление источника данных в среду выполнения
data_stream = env.add_source(source)
print('source_type ', data_stream.get_name()) #Вывод типа источника данных
print('data_types ', data_stream.get_type()) # Вывод типа элементов источника данных
data_stream \
.map(lambda x: x, output_type=row_type_info) \ #Операция map, которая просто выводит элементы на консоль
.print()
#Запуск выполнения программы
env.execute("Kafka to Upstash")
Однако, при выполнении этого кода у меня возникли ошибки, отладить которые мне пока не удалось.
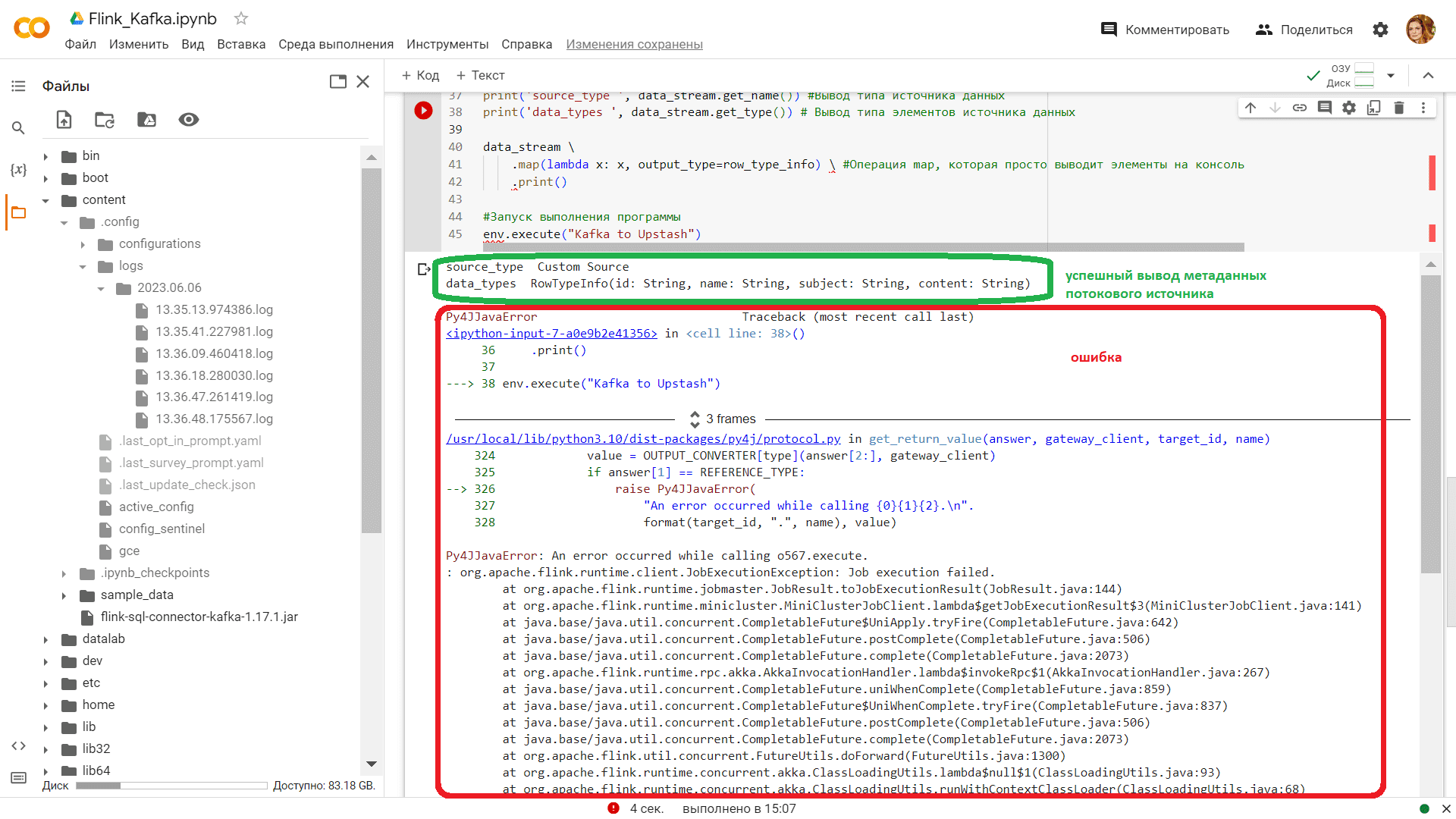
Скорей всего, эти ошибки связаны с некорректной установкой зависимостей между различными модулями и классами фреймворка Flink, Python и внешнего сервера Kafka. Также, необходимо полностью использовать возможности потоковой обработки в Apache Flink, включая точки сохранения и водяные знаки, что отсутствует в моем коде. А интерактивная среда Google Colab добавляет сложности, не позволяя посмотреть логи, которые лежат в скрытой папке .config. Как побороть эти трудности, я покажу в другой раз. А в заключение напомню, что все эти и другие подробности использования Apache Flink для потоковой обработки событий в распределенных приложениях аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:

