В рамках обучения разработчиков Spark-приложений и дата-инженеров, сегодня рассмотрим, что такое локальность данных и как это влияет на производительность заданий. А также разберем, где в UI Apache Spark посмотреть нахождение данных для распределенных вычислений и какие параметры конфигурации следует настроить, чтобы повысить скорость их выполнения.
Что такое локальность данных в распределенной среде
Поскольку Apache Spark является кластерной средой с распределением данных по узлам. Изначально задачи обработки данных будут выполняться как можно ближе к тому месту, где находятся эти самые данные, чтобы сократить их передачу по сети. Локальность данных сильно влияет на производительность заданий Spark. Локальность данных помогает планировщику фреймворка запускать задачи вычисления или кэширования на узлах с доступными данными. Эта концепция пришла из Hadoop MapReduce, где данные в HDFS будут использоваться для размещения Map-операций, чтобы избежать перемещения данных по сети в HDFS. Поэтому всякий раз, при подключении Spark к HDFS, S3 и пр, фиксируется расположение файлов.
Если данные и код их обработки находятся вместе, вычисления будут быстрыми. Но если код и данные разделены, т.е. находятся на разных узлах кластера, сперва их следует объединить. Обычно сериализованный код переместить быстрее, чем данные, т.е. размер программных инструкций намного меньше, чем размер данных. Именно на основе этого принципа локальности данных фреймворк планирует распределенные вычисления.
Локальность данных (Data Locality) — это близость данных к обрабатывающему их коду. В зависимости от текущего местоположения данных выделяют несколько уровней этой локальности:
- Данные локального процесса (PROCESS_LOCAL Data), которые находятся в той же JVM, что и работающий код – это максимальная близость из возможных;
- Данные локального узла (NODE_LOCAL Data), которые находятся на том же узле в HDFS или в другом исполнителе. Это чуть медленнее, чем PROCESS_LOCAL, т.к. данные нужно переместить между процессами.
- Данные без предпочтений (NO_PREF Data), которые одинаково быстро доступны из любого места и не имеют предпочтений по локальности;
- Данные локальной стойки (RACK_LOCAL Data), что находятся на одной стойке серверов. Данные на другом сервере в той же стойке передаются по сети обычно через один коммутатор.
- Любые данные (ANY), которые находятся в другом месте сети, а не в той же стойке.
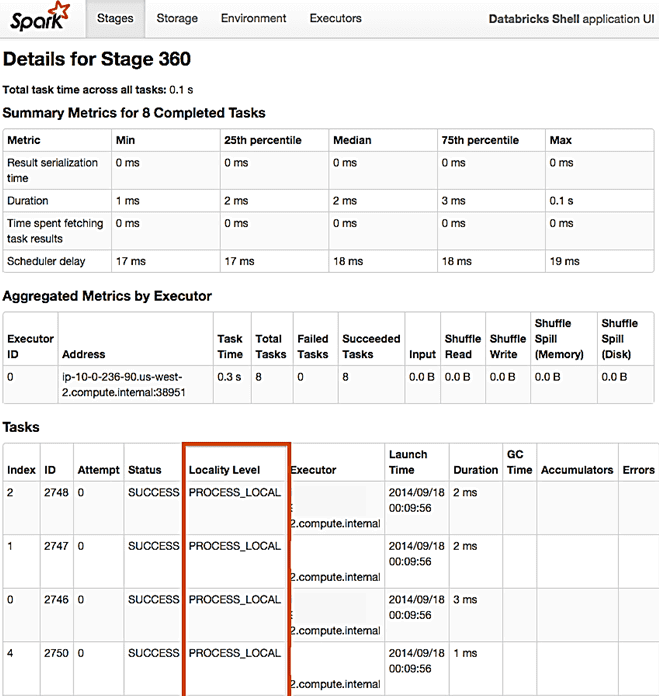
Самый простой способ проверить, выполняется ли задача локально, — это посмотреть сведения об этапе в пользовательском интерфейсе фреймворка. На вкладке «Этапы» (Stages) есть таблица с задачами, в которой имеется столбец «Уровень локальности» (Locality Level), где и отображается местоположение выполнения задачи.
Как локальность данных влияет на скорость Spark-заданий
Хотя Spark старается планировать все задачи на оптимальном уровне локальности, это не всегда удается. Если нет необработанных данных ни на одном незанятом исполнителе, фреймворк переключается на более низкие уровни локальности. В этом случае можно подождать, пока занятый ЦП освободится, чтобы запустить задачу с данными на том же сервере, или немедленно запустить новую задачу в более отдаленном месте, которое требует перемещения данных туда.
Обычно Spark ожидает освобождения загруженного процессора, а по истечении этого тайм-аута данные перемещаются на узел со свободным ЦП. Тайм-аут ожидания для возврата между уровнями локальности можно настроить с помощью параметров конфигурации, указав, как долго Spark будет ожидать освобождения ЦП на каждом уровне локальности данных: data local —> process local —> node local —> rack local —> Any. Для этого настраиваются значения следующих параметров конфигурации:
- locality.wait – время ожидания запуска локальной задачи до отказа и запуска на другом узле. Одно и то же ожидание будет использоваться для перехода через несколько уровней локальности (локальный процесс, локальный узел, локальный для стойки и любой другой). Также можно настроить время ожидания для каждого уровня, установив spark.locality.wait.node и пр. По умолчанию значение параметра spark.locality.wait равно 3 секунды. Это подходит для большинства случаев, но можно увеличить это число для длительных задач или снижения производительности Spark-приложения из-за локализации данных.
- locality.wait.node – время ожидания запуска локальной задачи на локальном узле. По умолчанию значение этого параметра равно spark.locality.wait. Можно установить значение 0, чтобы пропустить локальный узел и сразу перейти на уровень стойки, если в Spark-кластере есть информация об этом.
- spark.locality.wait.process – время ожидания локального процесса, влияет на задачи, которые пытаются получить доступ к кэшированным данным в конкретном процессе-исполнителе. По умолчанию значение этого параметра равно locality.wait.
- locality.wait.rack – время ожидания на уровне локальной стойки. По умолчанию значение этого параметра равно spark.locality.wait.
Практический смысл этой настройки зависит от размера обрабатываемых данных. Например, для больших наборов данных, если задания выполняются слишком долго, выполнение задач на нелокальных узлах кластера сильно снижает скорость обработки. Это происходит из-за того, что большой объем данных передается на удаленные узлы как при shuffle-операциях и приводит к задержкам в обработке. Затраты на передачу больших объемов данных по сети могут быть большими. Здесь следует учитывать локальность данных, поэтому рекомендуется увеличить время ожидания (параметры spark.locality.wait), чтобы задачи ожидали запуска на узлах, локальных для данных.
Для маленьких наборов данных локальность их обработки тоже важна. В частности, скорость обработки маленьких датасетов будет низкой, если на локальных узлах выполняется только несколько задач, а остальная часть кластера простаивает. В этом случае стоимость перетасовки данных по кластеру относительно невысока, в отличие от простаивающих узлов в кластере. Поэтому здесь можно снизить время ожидания, чтобы задачи равномерно распределялись по кластеру, обеспечивая более высокую степень распараллеливания.
Обычно долго выполняющиеся задания выигрывают от более длительного времени ожидания, т.к. стоимость ожидания меньше влияет на общее время завершения задания. Для быстро выполняющихся заданий (до 2 секунд) лучше задать небольшое значение параметра spark.locality.wait. Иногда даже установить нулевое время ожидания, чтобы они немедленно выполнялись на следующем доступном узле. Таким образом, опытным путем можно определить наилучшее время ожидания, добившись компромисса между стоимостью перетасовки данных по узлам и распараллеливанием задач по кластеру.
В потоковых приложениях значение параметра spark.locality.wait можно установить равным 0, чтобы все задачи выполнялись немедленно. По умолчанию пакетное окно в 5 секунд делает ожидание продолжительностью 3 секунды. Ожидание 60% времени обработки пакета перед началом работы скорей всего, будет неэффективным.
Если Spark совмещен с хранилищем, например, Hadoop HDFS, в одном кластере, локальность данных полезна для планировщика запуска задач на узлах так, чтобы исключить или сделать минимальным перемещение данных по сети. Для этого следует знать расположение HDFS-блоков для каждого файла. Если Spark-кластер отделен от хранилища в случае облачного объектного хранилища или удаленного кластера HDFS, локальность данных становится неактуальной, т.к. данные все равно необходимо перемещать. Здесь следует использовать разделяемые форматы файлов и соответствующее партиционирование для достижения необходимой производительности, чтобы Spark не тратил время на выборку локальных блоков для каждого файла. В 3-ей версии фреймворка есть возможность отключить эту локализацию данных, установив параметру конфигурации spark.sql.sources.ignoreDataLocality значение False, как это задано по умолчанию. Если установить значение true, фреймворк не будет извлекать расположение блоков для каждого файла в списке файлов. Это ускорит получение списка файлов, но планировщик не сможет планировать задачи, чтобы воспользоваться преимуществами локальности данных. Однако, такой прием пригодится, если данные считываются из удаленного кластера, когда планировщик в любом случае не сможет воспользоваться преимуществами локальности.
Узнайте больше про администрирование и использование Apache Spark для разработки распределенных приложений и аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
- https://spark.apache.org/docs/latest/tuning.html#data-locality
- https://medium.com/@sarveshdave1/data-locality-in-spark-faca16fd8633
- https://databricks.gitbooks.io/databricks-spark-knowledge-base/content/performance_optimization/data_locality.html
- https://spark.apache.org/docs/latest/configuration.html#scheduling
- http://blog.madhukaraphatak.com/spark-3-introduction-part-10/
- https://jaceklaskowski.github.io/mastering-spark-sql-book/configuration-properties/#sparksqlsourcesignoredatalocality