 394
394 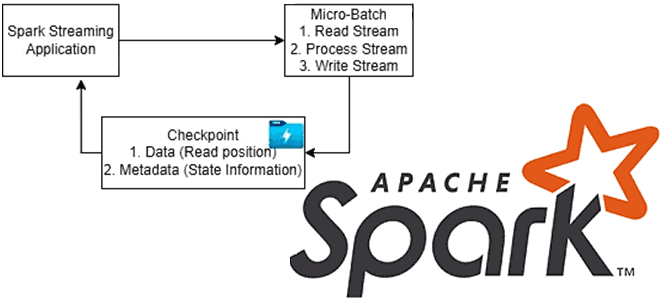
Содержание
Чтобы обеспечить отказоустойчивость потоковых приложений, Apache Spark использует механизм контрольных точек. Какие они бывают, когда их включать и как настроить для эффективной работы.
Что такое checkpoint в Apache Spark и зачем он нужен
Чтобы приложение потоковой передачи было устойчиво к сбоям по внешним причинам, например, отказ JVM, Spark Streaming сохраняет промежуточные данные в отказоустойчивой системе хранения, чтобы использовать их для восстановления приложения, т.е. перезапуска драйвера. Для этого фреймворк использует механизм контрольных точек (checkpoint), который сохраняет состояние приложения в надежном хранилище, например, в распределенной файловой системе Hadoop (HDFS).
Контрольные точки – это механизм Spark Core, ядра фреймворка, которое используется для распределенных вычислений. Он позволяет перезапустить драйвер в случае сбоя с ранее вычисленным состоянием распределенных вычислений, описанным как файл RDD. Этот подход применялся в Spark Streaming — устаревшем модуле Spark для потоковой обработки на основе RDD API. Установление контрольных точек усекает происхождение RDD, подлежащего проверке, что использует Spark MLlib в итеративных алгоритмах машинного обучения, таких как ALS. Таким образом, контрольные точки можно использовать для усечения логического плана датафрейма в итерационных алгоритмах, где план выполнения запроса растет экспоненциально. Через создание контрольной точки план разбивается на участки и сохраняется в файлах внутри каталога, установленного с помощью SparkContext.setCheckpointDir(). Контрольная точка набора данных в Spark SQL использует контрольную точку для усечения происхождения базового RDD для рассматриваемого Dataset или датафрейма.
Различают 2 вида контрольных точек в Spark:
- контрольная точка метаданных, включая конфигурации потоковой передачи, операции DStream, которые определяют приложение потоковой передачи, и неполные пакеты, задания которых находятся в очереди, но еще не завершены. Это используется для восстановления после сбоя узла, на котором работает драйвер потокового приложения.
- контрольная точка данных – RDD-структуры (Resilient Distributed Dataset) данных, сохраненные в надежном хранилище. Напомним, простая, неизменяемая, распределенная коллекция объектов является одной из базовых структур данных Apache Spark, которая предоставляет разработчику низкоуровневый API для выполнения stateful-преобразований. Если текущий RDD зависит от предыдущих, т.е. объединяет данные из нескольких пакетов, что типично для приложений с сохранением состояния, для повышения надежности обработки данных рекомендуется сохранять промежуточные результаты вычислений, чтобы сократить время восстановления после сбоя.
Таким образом, локальная установка контрольных точек использует хранилище исполнителя для записи файлов контрольных точек, поэтому жизненный цикл исполнителя считается ненадежным. Надежная контрольная точка использует надежное хранилище данных (HDFS).
Таким образом, контрольные точки метаданных необходимы для восстановления после сбоев драйверов, а контрольные точки данных нужны для stateful-приложений, где выполняются преобразования с сохранением состояния. Помимо этой классификации по объектам сохранения, контрольные точки также можно разделить по степени надежности каталога контрольных точек:
- Надежная контрольная точка, когда фактический RDD сохраняется в надежной распределенной файловой системе в каталоге, установленном с помощью метода setCheckpointDir(directory: String). При работе в кластере каталог должен быть путем HDFS, поскольку драйвер пытается восстановить RDD с контрольной точкой из локального файла, которые фактически находятся на машинах исполнителей.
- Локальная контрольная точка, когда усеченный (неполный) граф происхождения RDD сохраняется в локальном хранилище исполнителя.
Контрольные точки следует включать для stateful-приложений, если в приложении используется метод updateStateByKey() или reduceByKeyAndWindow(). Для восстановления после сбоев драйвера, на котором запущено приложение, пригодятся контрольные точки метаданных с информацией о ходе выполнения. Другие потоковые statefull-приложения без этих преобразований можно запускать без включения контрольных точек. Однако, в этом случае восстановление после сбоев драйверов будет частичным, поскольку некоторые полученные, но необработанные данные могут быть утеряны. Впрочем, для многих сценариев это приемлемо.
Поскольку контрольная точка сохраняет данные на диске, усекая план выполнения запроса, ее можно применять для увеличения скорости его выполнения. Когда план запроса становится огромным, производительность резко снижается, поэтому можно добавить контрольные точки в некоторых стратегических точках конвейера данных. Например, при выполнении JOIN-операций: HashAggregate, ShuffleHashJoin, BroadcastHashJoin и SortMergeJoin.
Контрольная точка может быть активной или отложенной в зависимости от флага оператора eager. По умолчанию контрольная точка является активной и выполняется немедленно по запросу. Отложенная контрольная точка выполняется только при вызове действия.
Для использования контрольных точек необходимо указать ее каталог с помощью команды SparkContext.setCheckpointDir.
Как настроить контрольную точку и эффективно ее использовать
Для потокового Spark-приложения создание контрольных точек активируется через указание каталога, где они будут храниться, с помощью метода streamingContext.checkpoint(checkpointDirectory). Когда приложение запускается в первый раз, оно создает новый StreamingContext, настраивает все потоки и затем вызывает метод start(). Если программа перезапускается после сбоя, она заново создает StreamingContext из данных контрольной точки, считывая их из каталога. При разработке потокового приложения это указывается в методе StreamingContext.getOrCreate():
# Function to create and setup a new StreamingContext
def functionToCreateContext():
sc = SparkContext(...) # new context
ssc = StreamingContext(...)
lines = ssc.socketTextStream(...) # create DStreams
...
ssc.checkpoint(checkpointDirectory) # set checkpoint directory
return ssc
# Get StreamingContext from checkpoint data or create a new one
context = StreamingContext.getOrCreate(checkpointDirectory, functionToCreateContext)
# Do additional setup on context that needs to be done,
# irrespective of whether it is being started or restarted
context. ...
# Start the context
context.start()
context.awaitTermination()
Если каталог контрольных точек (checkpointDirectory) существует, то контекст будет воссоздан из данных контрольной точки. Если каталог не существует, то будет вызвана функция functionToCreateContext для создания нового контекста и настройки DStreams. Также разработчик может явно создать объект StreamingContext на основе данных контрольной точки и начать вычисления, используя StreamingContext.getOrCreate(checkpointDirectory, None).
Помимо использования функции getOrCreate() также необходимо обеспечить автоматический перезапуск процесса драйвера в случае сбоя. Это может быть сделано только с помощью инфраструктуры развертывания, которая используется для запуска приложения.
Поскольку установка контрольных точек RDD требует затрат на сохранение в надежном хранилище, это может увеличить временя обработки тех пакетов, где RDD получают контрольную точку. Поэтому необходимо оптимально выбрать интервал между контрольными точками:
- при небольших размерах пакетов, например, 1 секунда, установка контрольных точек для каждого пакета может сильно снизить производительность операции;
- слишком редкое установление контрольных точек приводит к увеличению размера наследования и задач, что снижает надежность системы.
Для преобразований с отслеживанием состояния, требующих контрольных точек RDD, интервал по умолчанию кратен интервалу пакета, который составляет не менее 10 секунд. Его можно установить с помощью dstream.checkpoint(checkpointInterval). Обычно интервал контрольной точки в 5–10 скользящих интервалов DStream является хорошей настройкой.
Поскольку RDD можно восстановить из файлов контрольных точек с помощью метода SparkContext.checkpointFile(). А метод SparkSession.internalCreateDataFrame поможет воссоздать DataFrame из RDD. Однако, поскольку метод SparkContext.checkpointFile(directory: String) является защищенным, код для доступа к нему должен находиться в пакете org.apache.spark.
Чтобы увидеть, что происходит, когда RDD находится в контрольной точке, надо включить логирование событий типа INFO в org.apache.spark.rdd.ReliableRDDCheckpointData, добавив следующую строку в файл conf/log4j.properties:
log4j.logger.org.apache.spark.rdd.ReliableRDDCheckpointData=INFO.
В заключение отметим, что аккумуляторы и широковещательные переменные, о которых мы писали здесь, не могут быть восстановлены из контрольной точки в Spark Streaming. Поэтому, если включены контрольные точки и используются аккумуляторы или широковещательные переменные, разработчику Spark-приложения придется создавать для них отложенные одноэлементные экземпляры, чтобы переиспользовать их после перезапуска драйвера в случае сбоя.
Освойте возможности Apache Spark для разработки приложений аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Потоковая обработка в Apache Spark
- Анализ данных с Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
[elementor-template id=»13619″]
Источники
- https://spark.apache.org/docs/latest/streaming-programming-guide/#checkpointing
- https://sparkbyexamples.com/kafka/spark-streaming-checkpoint/
- https://data-flair.training/blog/spark-streaming-checkpoint/
- https://jaceklaskowski.gitbooks.io/mastering-spark-sql/content/spark-sql-checkpointing/
- https://umbertogriffo.gitbook.io/apache-spark-best-practices-and-tuning/storage/which_storage_level_to_choose

