
В рамках курсов по Apache Hadoop для дата-аналитиков и инженеров данных сегодня рассмотрим пару практических примеров работы с популярным SQL-on-Hadoop инструментом этой экосистемы. Читайте далее, как настроить соединение удаленного сервера Apache Hive к Spark-приложению через JDBC и решить проблему запроса таблицы HBase в Hive вместо повторной репликации данных. Подключение удаленного...

Мы уже упоминали, что Apache Kafka не слишком хорошо обрабатывает сообщения чрезмерно большого размера. Сегодня рассмотрим, как эта проблема решается в конвейерах потоковой обработки IoT-инфраструктуры Tesla. Читайте далее про модификацию синтаксического анализатора данных от множества устройств интернета вещей с поиском компромисса между скоростью и надежностью с помощью коннектора Alpakka к...

При том, что Apache Spark является одной из главных технологий стека Big Data, этот фреймворк не очень хорошо работает с множеством файлов небольшого размера. Поэтому в рамках обучения дата-инженеров и разработчиков распределенных приложений, сегодня рассмотрим, почему это происходит, зачем динамически сжимать файлы в Apache Spark и как это делает платформа...

В рамках обучения разработчиков распределенных приложений, сегодня рассмотрим, как упростить тестирование и отладку заданий Apache Flink с помощью Byteman. Читайте далее, как внедрить Java-код в JVM, чтобы извлечь нужные сведения о выполнении Flink-приложения на платформе Veverica и ускорить разработку. Разработка и отладка приложений Apache Flink: ежедневные сложности В рассматриваемом примере...

В предыдущей статье мы говорили о том, как начать работать с Apache Airflow. Сегодня пойдет речь о новом инструменте, появившемся в Airflow 2, — TaskFlow API. Он обеспечивает кросс-коммуникацию между задачами с помощью обычных функций Python. На примере ETL-конвейера мы объясним, как соорудить DAG на основе TaskFlow API, а также...
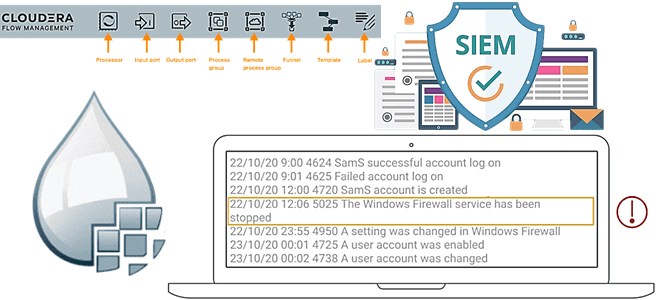
В этой статье для дата-инженеров рассмотрим, что такое Cloudera Flow Management и как это позволяет ускорить аналитику больших данных в кейсах информационной безопасности. Читайте далее о преимуществах SIEM-анализа, преобразования и распределения security-событий с помощью Apache NiFi и его легковесного агента MiNiFi для устройств интернета вещей (Internet Of Things, IoT). Что...

Продолжая разбирать кейс компании Tesla по организации централизованного управления устройствами интернета вещей (Internet of Things, IoT), сегодня разберем, как выполняется обработка сообщений в топиках Apache Kafka с помощью Confluent Schema Registry и Kafka Streams. Читайте далее, как определить потоковый процессор для парсинга данных в CSV и JSON-форматах с использованием схемы...

Сегодня разберем кейс компании Renault по масштабированию своей цифровой платформы и снижению затрат с помощью BigQuery и Apache Spark на Google Dataproc. Цифровизация в автомобильной промышленности: конвейер сбора и аналитики больших данных с производства средствами Google сервисов и снижение затрат на облако в 2 раза через изменение конфигурации Spark SQL....

В рамках курсов для дата-инженеров и разработчиков распределенных приложений, сегодня рассмотрим пример построения системы потоковой передачи для аналитики больших данных на базе Apache Kafka, Spark и Google BigQuery. Читайте далее про Proof of Concept для конвейера продуктовой аналитики, который обрабатывает 50 миллиардов событий каждый день, и какие важные уроки ИТ-архитектор...

Являясь лидером отрасли, IoT-устройства Tesla обрабатывают триллионы событий в день, чтобы повысить эффективность своих электроавтомобилей. Однако, такая производительность была получена не сразу: чтобы достичь ее, инженерам компании пришлось решить множество проблем из области интернета вещей (Internet of Things, IoT). Сегодня рассмотрим, как часть из них была решена с помощью Apache...