 944
944 
Содержание
Являясь лидером отрасли, IoT-устройства Tesla обрабатывают триллионы событий в день, чтобы повысить эффективность своих электроавтомобилей. Однако, такая производительность была получена не сразу: чтобы достичь ее, инженерам компании пришлось решить множество проблем из области интернета вещей (Internet of Things, IoT). Сегодня рассмотрим, как часть из них была решена с помощью Apache Kafka.
Сложности IoT-устройств и их решение с помощью Apache Kafka
На первый взгляд, потоки данных IoT похожи на обычные события журнала веб-сервера, которые генерируются в больших объемах. Их необходимо обработать и сделать доступными для следующих потребителей или сохранить в СУБД. Однако, в действительно вместо веб-серверов, которые можно полностью контролировать, в IoT-системах имеется множество устройств с разными версиями прошивки и огромным количеством форматов данных. Причем некоторые из этих устройств могут «сойти с ума», отправляя свои данные в общую инфраструктуру слишком часто и/или много. Это выглядит как DoS-атака, которую следует предусмотреть и предупредить заранее.
Кроме того, интернет вещей включает устройства, связанные с медициной, здоровьем и безопасностью. Такие кейсы имеют высочайший приоритет и требуют минимальной задержки обработки данных. Разделяя их от потоков Big Data, которые нужны аналитикам для мониторинга, исследований и оценки состояния парка IoT-устройств, мы приходим к разным уровням обслуживания в одной среде. Дополнительную сложность вносит многообразие форматов данных, которые отличаются от относительно легко обрабатываемых Apache AVRO или Protobuf из-за требований к процессору и сетям передачи информации.
Также в IoT-системе должны присутствовать базовые функции управления парком устройство, включая мониторинг их исправности и корректности отправляемых данных. При этом следует активно отслеживать и нетривиальные ошибки, которые возникают очень редко. На практике для этого используются микросервисный подход к построению архитектуры, где на конечных устройствах работают свои группы программ, которые отправляют данные на сервер, где ведется их обработка. Поэтому для компаний, чей бизнес построен на Internet of Things, очень актуален вопрос создания инфраструктуры для поддержки миллионов устройств и триллионов точек данных в день за приемлемую цену.
Прежде чем принять решение о технологиях, следует определить базовые возможности такой IoT-системы:
- надежное хранение данных;
- горизонтальная масштабируемость;
- высокая пропускная способность;
- низкая задержка обработки информации.
Проблема не в том, как получить данные с конечных устройств, а в том, как обработать их быстро, сделав доступными для последующих пользователей и сервисов. Для решения всех этих задач инженеры компании Tesla используют Apache Kafka, которая обеспечивает надежное хранилище и может горизонтально масштабироваться без увеличения сложности в эксплуатации и значительных операционных издержек. Наконец, система на базе Kafka может быть невероятно быстрой, сохраняя высокую пропускную способность и стабильность. Поэтому именно Apache Kafka была выбрана Tesla в качестве ядра IoT- инфраструктуры, о дальнейшем развитии которой мы поговорим далее.
Размер имеет значение: обработка больших сообщений
Итак, чтобы передать данные с конечных устройств в Apache Kafka, необходимо реализовать потоковую обработку, чтобы сделать эти необработанные данные пригодными для использования и доступными для следующих пользователей и сервисов дата-конвейера. Эта потоковая обработка должна быть гибкой, масштабируемой и поддерживаемой, т.к. данные могут быть представлены множеством потоков в различных форматах, ежедневно генерируя триллионы событий. Поэтому прежде всего следует определить шаблонов, достаточно гибкие для повторного использования во всех сценариях, сохраняя масштабирование. Такие паттерны должны легко адаптироваться к новым потокам данных и устройствам, не увеличивая операционную нагрузку на команды разработки.
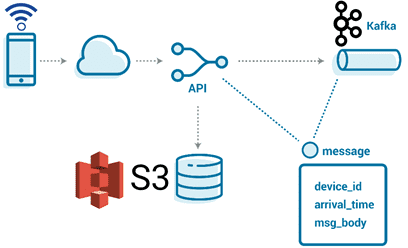
Таким образом, необходим посредник для абстракции клиентов Kafka от IoT-устройств, ограниченных по вычислительной мощности и пропускной способности передачи данных. Также здесь должна быть возможность быстрого изменения маршрутизации данных, т.е. топика Apache Kafka, где собираются данные от конечного устройства, чтобы оперативно внедрять изменения на стороне сервера без изменения прошивки.
Таким посредником может быть веб-сервер на REST API или конечная точка MQTT-протокола. Веб-сервер позволяет IoT-устройствам использовать более примитивную среду выполнения, а не расширенную клиентскую библиотеку Kafka. Однако, некоторые полезные данные могут быть большими, например, историческое накопление важной информации, а другие должны быть долговечными, доступными и быстро обрабатываемыми. Некоторые сообщения приходят с опозданием, но являются критичными и их нельзя терять. Другие более опциональны, т.е. без них можно обойтись, но они обеспечивают дополнительную ценность, управляя нагрузкой и/или снижая стоимость репликации. Поэтому нужны разные механизмы хранения и обработки каждого типа сообщений.
Кроме того, перед обработкой данных важно убедиться в их достоверности и надежности. Поэтому у сервера API появляется еще одна задача, помимо маршрутизации: понять, что данные являются надежными, прежде чем подтвердить их успешное получение для клиента и последующий прием сообщений. Но для устройств с небольшой емкостью хранения данных или отправляющих последние сигналы перед полной разрядкой батареи есть только один шанс получить эту информацию, причем бывает жизненно важно сделать это с первого раза.
Ключевой частью обеспечения первой попытки отправки сообщения в Kafka как единственной, является равномерная нагрузка записи в данных в топики: выделена достаточная емкость и любое сообщение может храниться в течение длительного времени. Для этого в Tesla используется стратегия разделения для назначения сообщений по разделам топика с миллисекундой эпохи, в которой получено сообщение. Это обеспечивает равномерное распределение данных даже в рамках пары секунд, позволяя размещать данные как можно быстрее. Также это снижает операционную нагрузку и разрастание системы, т.к. можно просто добавить больше разделов и продолжить горизонтальное масштабирование.
В инфраструктуре интернета вещей встречается еще одна нетривиальная проблема обработки потоков данных с конечных устройств, отличная от журналов веб-сервера. IoT-устройства часто отключаются на долгое время, а при возобновлении соединения отправляют огромное количество данных. В зависимости от прошивки, это может означать отправку множества мелких сообщений, что неэффективно с точки зрения хранилища и пропускной способности, или их объединение в одно большое сообщение. Если просто записывать их в топики Kafka, это вызовет перегрузку кластера, поскольку эта платформа потоковой обработки событий не предназначена для огромных файлов [1]. Размер сообщения, записываемого в топик Kafka, ограничен лимитом, заданный в конфигурации max.message.bytes на стороне брокера. По умолчанию максимальный размер одного пакета сообщений, отправленных в Kafka, равен 1 МБ [2]. Подробнее об этом мы рассказывали здесь.
Чтобы не писать собственный сериализатор-десериализатор для регулярной обработки огромных сообщений с обеспечением минимальной задержки и высокой производительности, можно разделить кластеры Kafka по типу рабочей нагрузки: один для небольших сообщений, а другой для более крупных. Однако, в этом случае придется управлять множеством кластеров Kafka и сценариями их использования. Поэтому дата-инженеры Tesla рассматривали два альтернативных подхода для обработки больших сообщений в одном кластере Kafka:
- разбить большое сообщение на более мелкие части;
- сохранить ссылку на сообщение Kafka во внешнем хранилище, например, AWS S
Какой из этих вариантов был выбран и почему, мы рассмотрим далее.
AWS S3 как внешнее хранилище для Apache Kafka
Разбиение большого сообщения на множество мелких не очень подходит для IoT-системы с множеством устройств, использующих множество форматов данных, в т.ч. те, которые не просто фрагментировать, т.к. придется сохранять состояние между фрагментами, чтобы понимать очередность происхождения данных. Еще к этому придется добавлять логику, определяющую начало и конец сообщения, а также обрабатывать случаи, когда один из этих фрагментов отсутствует или не корректен. API становится более сложным, т.к. необходимо обеспечить, чтобы фрагменты попадали в один и тот же раздел. А это уже может нарушить равномерное распределение, в котором разделы топика Kafka назначаются сообщениям на основе текущей временной метки. Это увеличит задержку между поступлением данных и их обработкой, а также имеет риск не получить данные или снизить их надежность.
Поэтому дата-инженеры Tesla выбрали 2-ой вариант, воплощение которого облегчало наличие API для приема данных. Этот API позволил реализовать собственную логику определения места хранения сообщения в зависимости от размера полезной нагрузки. Небольшие сообщения хранятся непосредственно в топиках Apache Kafka, а большие – доступны по ссылке во внешнем хранилище. Это также дает гибкость распределения данных по разделам для поддержки различных сценариев использования без дополнительных затрат, связанных с запоминанием обработки фрагментов. Все потоки данных могут выглядеть одинаково, независимо от приоритета, размера сообщения или объема. Поэтому даже с учетом дополнительных накладных расходов, связанных с несколькими backend’ами, внешнее хранилище для крупных сообщений – вполне жизнеспособная идея. К примеру, популярное объектное хранилище Amazon S3 известно своей надежностью и долговечностью с небольшими операционными издержками. Поскольку S3 — это не файловая система POSIX, необходимо просто место для хранения сообщения и ссылка, чтобы получить его позже.
А благодаря распространенности S3 и совместимости со множеством платформ, можно перенести реализацию собственного API приема к другому поставщику или использовать локально. Наконец, S3 позволяет устанавливать время жизни (TTL) для корзины, чтобы автоматически очищать сообщения, которые не доставляются в случае сбоя. Итак, используя внешнее хранилище API компании Tesla записывает сообщения в топики Kafka в следующем виде:
Message {
string device_id;
optional string reference;
optional bytes body;
}
Ключом события для распределения сообщений по разделам топика Apache Kafka является arrival_time_millis – время поступления события. Небольшие сообщения отправляются в топик Kafka сразу, а для больших сообщений записываются только ссылки на S3 [1]. Далее выполняется парсинг полученного потока данных, что мы рассмотрим в следующей раз.
Больше полезных кейсов использования Apache Kafka для разработки распределенных приложений потоковой аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

