 533
533 
Содержание
Сегодня разберем кейс компании Renault по масштабированию своей цифровой платформы и снижению затрат с помощью BigQuery и Apache Spark на Google Dataproc. Цифровизация в автомобильной промышленности: конвейер сбора и аналитики больших данных с производства средствами Google сервисов и снижение затрат на облако в 2 раза через изменение конфигурации Spark SQL.
Цифровизация автомобильной промышленности: IDM 4.0 в Renault Group
Цифровизация в корпорации Renault Group активно внедряется на всех уровнях автомобильного производства и логистики: компания собирает свои промышленные данные и отправляет их в облачные сервисы Google для анализа и создания безопасной, надежной, масштабируемой и экономичной платформы управления. Renault Group производит автомобили с 1898 года. Сегодня это международная группа с пятью брендами, которая в 2020 году продала почти 3 миллиона автомобилей по всему миру, имеет 40 производственных площадок и более 170 000 сотрудников.
В 2016 году Renault запустила стратегию цифровой трансформации, чтобы повысить эффективность производства за счет использования промышленных данных со своих производственных площадок. В 2019 отдельные инициативы цифровизации были объединены программу под названием Industry Data Management 4.0 (IDM 4.0), чтобы разработать и создать уникальную платформу и структуру для всех промышленных данных компании. Ожидается, что IDM 4.0 позволит специалистам Renault по производству и логистике быстро разрабатывать приложения аналитики и прогнозирования с помощью машинного обучения и других методов искусственного интеллекта на основе единой промышленной платформы сбора и обработки данных.
В рамках IDM 4.0 команда цифровой трансформации Renault смогла снизить затраты на хранение данных более чем на 50% благодаря переходу на Google Cloud. При этом ключевыми бизнес-требованиями были надежность данных, их долгосрочное хранение и невозможность подделки [1]. Достичь этого позволило применение Apache Spark на полностью управляемом сервисе Dataproc для обработки данных и геораспределенной СУБД Spanner, также разработанной Google, которая позиционируется как развитие системы BigTable. СУБД Spanner относят к категории NewSQL: она поддерживается язык SQL, но не является чисто реляционной, в частности, каждая таблица должна обязательно иметь первичный ключ. Поддерживая согласованность распределенных транзакций, Spanner отлично масштабируется и используется внутри инфраструктуры Google как часть ее облачной платформы (GCP, Google Cloud Platform), а также доступен в виде сервиса [2]. О том, как Spanner используется в компании Uber для поиска ближайшей к пользователю машины, читайте в нашей новой статье.
Возвращаясь к цифровизации Renault, отметим необходимость масштабирования и развертывания большего числа бизнес-сценариев в рамках IDM 4.0 при сохранении рентабельности платформы, максимальной производительности и надежности. Это требовало пересмотра архитектуры, поскольку ранее существовавшая система не смогла бы обеспечить глобальный рост без превышения бюджетов проекта. Как это было сделано с помощью облачных сервисов Google Cloud, включая BigQuery и Apache Spark на Dataproc, мы рассмотрим далее.
Сокращение затрат на облачные сервисы Google через настройку конфигурации Apache Spark
Сбор промышленных данных – не самая простая задача. Для этого дата-инженеры Renault организовали собственный процесс, основанный на стандартных моделях данных, разработанных с помощью OPC-UA, открытого межмашинного протокола связи. В новой архитектуре Google Cloud эта модель данных реализована в BigQuery, поэтому большинство операций записи выполняется только для добавления. Теперь нет необходимости выполнять множество операций соединения для получения необходимой информации. BigQuery дополнен кэшем в Memorystore, чтобы всегда получать актуальные состояния. Напомним, Memorystore – это масштабируемый, безопасный и высокодоступный In-Memory сервис от Google для СУБД Redis и Memcached. Он позволяет создавать кэши приложений, обеспечивающие доступ к данным за доли миллисекунды.
Такая архитектура обеспечила высокопроизводительные и экономичные операции чтения и записи. Также дата-инженеры Renault решили использовать Apache Beam – унифицированную модель определения пакетных и потоковых конвейеров для параллельной обработки данных, а также набор специфических SDK для построения конвейеров и вычислительных процессов в бэкэндах для их выполнения на серверах распределенной обработки, включая Apache Spark и Google Cloud Dataflow [3]. Использование Apache Beam обеспечило следующие преимущества [1]:
- унифицированная модель для пакетной и потоковой обработки сократила разнообразие программного кода, увеличив гибкость в выборе типов обработки заданий в зависимости от потребностей и целевых затрат;
- множество доступных коннекторов (PubsubIO, BigQueryIO, JMSIO и пр.) позволяет расширять систему и дополнять ее новыми возможностями;
- упрощение операций сопровождения и обслуживания – эффективное автомасштабирование, более плавное обновление, точное отслеживание затрат, простой мониторинг, сквозное тестирование и управление ошибками.
Таким образом, Dataflow стал основным инструментом для решения большинства задач по обработке данных на платформе, дополняясь другими управляемыми сервисами Google Cloud: Kubernetes Engine, Composer и Memorystore. Благодаря легкости масштабирования в 1-м квартале 2021 года команда IDM 4.0 подключила более 4900 промышленных устройств с помощью внутреннего решения Renault для сбора данных, ежедневно передавая более 1 миллиарда сообщений в Google Cloud!
Анализ данных с помощью современного Apache Spark
Код курса
SPARK
Ближайшая дата курса
16 марта, 2026
Продолжительность
32 ак.часов
Стоимость обучения
96 000
Чтобы еще более повысить эффективность новой архитектуры, было решено оптимизировать ее с точки зрения экономических затрат. Проанализировав производительность каждого из компонентов системы, дата-инженеры Renault обнаружили, что один кластер Apache Spark непрерывно выполняет операции классов A и B, обращаясь к облачному хранилищу примерно раз в 10-30 миллисекунд. Это несовместимо с большинством входящих потоков, которые имеют часовую или дневную периодичность. Исправить это помогло увеличение интервала опроса файловой системы в конфигурации Spark – параметр spark.sql.streaming.pollingDelay. Это свойство отвечает за период времени в миллисекундах, в течение которого выполнение StreamExecution перед опросом новых данных будет задерживаться, если партия данных из предыдущего пакета еще не доступна. По умолчанию значение spark.sql.streaming.pollingDelay составляет 10 миллисекунд. Это несложное изменение помогло в 100 раз снизить количество обращений к облачному хранилищу класса A и значительно сократить количество вызовов класса B, в общем итоге сэкономив затраты на 50%.
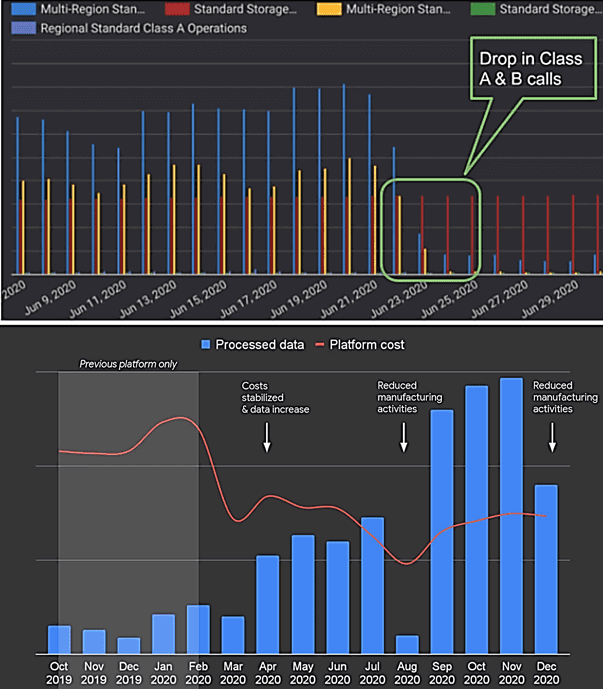
Renault использует Dataflow для приема и преобразования данных с заводов-производителей, а также из других связанных СУБД. BigQuery применяется для хранения и аналитики больших данных, отслеживание посылок, транспортных средств и пр. В перспективе Renault ожидает 10-кратное увеличение объема промышленных данных в ближайшие 2 года с расчетом, что IDM 4.0 сохранит производительность и надежность их обработки в рамках оптимальных затрат.
Core Spark - основы для разработчиков
Код курса
CORS
Ближайшая дата курса
16 марта, 2026
Продолжительность
16 ак.часов
Стоимость обучения
48 000
Больше подробностей эксплуатации Apache Spark в цифровизации промышленности, разработке распределенных приложений и аналитике больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Аналитика больших данных для руководителей
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источники

