 1163
1163 
Содержание
Продолжая разбирать кейс компании Tesla по организации централизованного управления устройствами интернета вещей (Internet of Things, IoT), сегодня разберем, как выполняется обработка сообщений в топиках Apache Kafka с помощью Confluent Schema Registry и Kafka Streams. Читайте далее, как определить потоковый процессор для парсинга данных в CSV и JSON-форматах с использованием схемы AVRO и выбрать подход к организации топиков Apache Kafka.
Не просто место сбора: логика хранения и обработки сырых данных в топиках Apache Kafka
Напомним, в компании Tesla в качестве ядра IoT-инфраструктуры, которая собирает данные от множества устройств интернета вещей, является Apache Kafka. Именно в топиках этой распределенной платформы потоковой обработки событий хранятся необработанные данные, которые далее используются различными приложениями. Чтобы обеспечить разным командам доступ к данным как к потоку событий с малой задержкой и разделить этапы логической обработки, чтобы масштабировать их независимо друг от друга и изолировать операции, было решено создать промежуточную каноническую форму данных, не зависящую от отдельных процессов. Это каноническое представление данных является единым интерфейсом для всех последующих операций. Функцию, преобразующую исходные данные в эту форму, можно назвать парсером и встроить ее как логику синтаксического анализа в инструмент обработки потока, чтобы сделать канонические данные доступными для следующих потребителей с низкой временной задержкой. Дата-инженеры Tesla решили объединить логику синтаксического анализа с логикой хранения данных в топиках Apache Kafka. Это свяжет пропускную способность обработки с пропускной способностью системы хранения (базы или озера данных), а также даст следующие преимущества [1]:
- снижение сложности всей платформы за счет сокращения взаимодействий и интерфейсов – каждый компонент имеет ограниченные задачи и четко определенные области действия;
- удобное управление операциями – к примеру, если при записи в систему хранения данных и возникли проблемы, можно повторно запустить этот этап обработки после восстановления;
- независимое выполнение — даже если система хранения данных не работает, можно продолжать этап синтаксического анализа для генерации канонических данных, делая их доступными для других потребителей и логируя пропущенные этапы, чтобы выполнить их позже;
- изоляция нагрузки и независимое масштабирование отдельных компонентов с учетом их явных и неявных ограничений. Например, если в какой-то момент СУБД не может обрабатывать пиковые объемы, достаточно уменьшить количество потребителей, снизив скорость потребляемых записей и нагрузку. После прохождения пика можно продолжить запись с нормальной скоростью и наверстать отставание, накопившееся за период пиковой нагрузки, без воздействия на другие этапы.
Этот канонический формат также очень полезен при предоставлении данных потоковой передачи событий разным командам разработчиков и дата-инженеров. Ограничение сложности позволяет обойтись без собственного анализатора необработанных данных или знаний о большом хранилище сообщений для получения нужной информации. Кроме того, так можно гарантировать, что схема в проанализированном каноническом топике Kafka сохранит обратную совместимость и не нарушит работу потребителей. Это обеспечит реестр схем Confluent Schema Registry, о которым мы писали здесь. Он выполняет роль центральной точки отслеживания схемы для каждого топика, упрощая понимание и интерпретацию канонических данных. Благодаря настраиваемой совместимостью (прямой, обратной или полной) данные остаются доступными для чтения. Наконец, можно референсную схему, чтобы упаковывать сообщения AVRO плотнее типовой сериализации.
Как написать свой парсер сообщений
В зависимости от форматов данных (JSON, CSV), которые поступают от IoT-устройств, потребуется создать несколько разных парсеров, которые будут быстро разворачиваться и сразу же решать конкретные проблемы. Причем при разработке этих функций следует случаи, когда события происходят не только на IoT-устройстве, но и на стороне сервера платформы Tesla. Чаще всего используется формат JSON, но иногда требуется создавать сообщения без объявленной схемы, такой как AVRO. В этом случае из сообщения как набора байтов создается ряд событий, который фреймворк переводит в канонические сообщения и отправляет их далее. Пользователям достаточно выбрать существующий синтаксический анализатор или создать собственный для поддержки своих пользовательских форматов. По сути, функция парсинга представляет собой инфтерфейс: parse(byte[]):: Iterator<Map<String, Object>>.
Клиентская библиотека Kafka Streams довольно легко создать оболочку вокруг интерфейса парсера, который поддерживает вышеописанную семантику:
StreamsBuilder builder = new StreamsBuilder();
builder.stream(conf.getSource(),…)
.transformValues(new ParserRunner())
// we get an iterable out, so we need to flatten them to single events
// exception here stop the processing
.flatMapValues(t -> t)
class ParserRunner {
private Parser parser = …
public Iterable transform(byte[] value) {
try{
return parser.parse(value)
} catch(Exception e){
// its OK for the parser to fail when generating the iterator, we just
// skip the record. It would also be a nice place for metrics/monitoring
return Iterators.empty();
}
}}
Благодаря этому интерфейсу управление потоковой обработкой и генерацией событий стало намного проще. В частности, теперь разработчики микропрограмм могут изменять форматы данных и добавлять новые потоки, не ожидая, пока команда обработки событий напишет и развернет новый код. Разумеется, остается актуальным вопрос, должен ли код поддерживать старые версии или проще развернуть новый топик и заново написать синтаксический анализатор для измененного формата данных. Из-за множества устройств в IoT-инфраструктуре Tesla нужно иметь возможность обработки старых форматов данных, т.к. обновления прошивки не всегда происходят регулярно.
Таким образом, необходимо соблюсти баланс, выбирая между сложностью кода и накладными расходами на дифференциацию форматов или операционной нагрузкой, связанную с управлением новыми топиками и конвейерами анализа данных. При этом необходимо привлекать команды потоковой обработки к участию в процессе развертывания, особенно для крупных изменений, т.к. это может повлиять не только на масштабируемый поток, но и на существующие конвейеры, а также все данные, которые приходят от IoT-устройств.
Управление множеством типов данных
С учетом контекста IoT-платформы Tesla, куда постоянно приходят новые потоки данных, добавляются типы устройств, расширяются существующие линейки продуктов или собираются новые данные с ранее существующих устройств, необходимо адаптировать решение к этим кейсам. для этого есть несколько подходов к проектированию топиков Kafka:
- один топик для каждого типа потока данных;
- один топик для всех типов с парсингом сообщений «на лету»;
- один топик для каждого типа устройства.
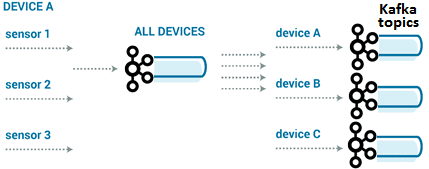
В действительности возможны все эти варианты. В случае общего формата данных можно записать все данные со всех устройств в один поток, чтобы уравновесить любые различия за счет огромного количества сообщений для достижения равномерного распределения. Но это не позволит регулировать пропускную способность отдельного потока, перекрывая его движение. Поэтому целесообразно выделить особо важные потоки в отдельные топики Kafka, возможно, сгруппировав их по устройствам.
Можно также разделить группы устройств, например, отделить оборудование корпоративных клиентов от потребительских приборов, т.к. предприятия обычно имеют гораздо более строгие SLA и другие показатели эксплуатационной надежности. Или необходимо отделить потоки устройств разработки от рабочих устройств, т.к. при разработке может генерироваться больше данных из-за отладки и тестирования микропрограмм, искажая равномерное распределение данных и устойчивость состояний.
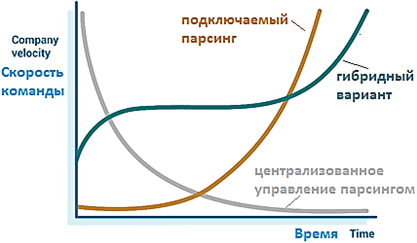
Наконец, кроме организации потоков необработанных данных, необходимо учесть право собственности на сам синтаксический анализ: команда потоковой передачи может попытаться поддерживать все возможные форматы или их ограниченное количество. Также можно сделать синтаксический анализ подключаемым. При единичном праве на синтаксический анализ и управлении всеми возможными форматами, есть риск того, что команда станет узким местом при создании новых типов данных. С другой стороны, подключаемые парсеры дают пользователям больше самостоятельности, но требуют от команды потоковой передачи больше затрат, чтобы сделать конвейер устойчивым к этим настраиваемым синтаксическим анализаторам.
Таким образом, здесь также необходимо найти баланс между централизованным или подключаемым управлением парсингом. В большинстве случаев централизованное управление будет начальной точкой, но это сложно масштабируется по мере роста количества типов данных. Переход к подключаемой модели парсинга позволит масштабировать IoT-инфраструктуру и устранить узкое место в потоковой передаче событий, передавая ответственность команде, заинтересованной в конкретном кейсе синтаксического анализа данных из топика Apache Kafka.
В следующей статье мы продолжим разбирать построение IoT-системы Tesla на базе Apache Kafka и рассмотрим проблемы обработки больших сообщений в этом data pipeline. А практически освоить тонкости администрирования и эксплуатации Apache Kafka для потоковой аналитики больших данных вам помогут специализированные курсы в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

