997
997 
Содержание
В предыдущей статье мы говорили о том, как начать работать с Apache Airflow. Сегодня пойдет речь о новом инструменте, появившемся в Airflow 2, — TaskFlow API. Он обеспечивает кросс-коммуникацию между задачами с помощью обычных функций Python. На примере ETL-конвейера мы объясним, как соорудить DAG на основе TaskFlow API, а также обсудим, как делать DAG’и не нужно.
Все дело в декораторах Python
Допустим, есть 3 задачи, которые нужно выполнить один за другим:
- Задача извлечения (Extract): взять из JSON данные, которые содержат сумму заказов, и вернуть их в виде словаря.
- Задача преобразования (Transform): просуммировать эти суммы заказов из данного словаря.
- Задача загрузки (Load): взять полученную сумму и загрузить в файл
sums.txt.
Данные задачи можно сформировать в виде Python-функций, которые задекорированы функцией task. Причем сами эти Python-функции должны находиться внутри другой функции, которая в свою очередь задекорирована функцией dag. Такая конструкция реализует TaskFlow API.
Итак, наш ETL-конвейер в Apache Airflow будет выглядеть следующим образом:
import json
from airflow.decorators import dag, task
from airflow.utils.dates import days_ago
args = { 'owner': 'romank', }
@dag(default_args=args, schedule_interval=None, start_date=days_ago(2))
def taskflow_api_etl():
@task()
def extract():
data_string = '{"1": 100.0, "2": 200.0, "3": 300.0}'
order_data_dict = json.loads(data_string)
return order_data_dict
@task(multiple_outputs=True)
def transform(order_data_dict: dict):
total_order_value = 0
for value in order_data_dict.values():
total_order_value += value
return {"total_order_value": total_order_value}
@task()
def load(total_order_value: float):
with open("sums.txt", "a") as f:
f.write(str(total_order_value) + "\n")
order_data = extract()
order_summary = transform(order_data)
load(order_summary["total_order_value"])
taskflow_api_etl()
В декораторе dag указывается ровно то, что мы указываем в контекстном менеджере DAG. В функции extract переменная data_string имитирует JSON-данные, которые конвертируются в словарь с помощью метода json.loads. Аргумент multiple_outputs в функции преобразования необходим для возможности обращения к записям словаря за пределами самих задач. Если бы не было этого аргумента, то order_summary["total_order_value"] возвратил бы None. Функция преобразования могла бы возвращать не словарь, а просто вещественное значение, тогда аргумент multiple_outputs можно было бы опустить; либо обращаться к записи словаря внутри функции загрузки, тогда бы она принимала в качестве аргумента словарь, а не float.
DAG имеет id задекорированной функции, т.е. taskflow_api_etl. Запустим DAG и посмотрим результаты записи файла:
$ cat sums.txt 600.0
— как видим, все работает. Одно важно замечание: функции должны быть вызваны, иначе задачи получат статус failed. В целом, можно даже не создавать переменные под задачи, а просто вызвать их друг за другом, но такой код становится менее читаемым:
load( transform(extract())["total_order_value"] )
Здесь мы даже поставили пробелы около первых скобок, чтобы не запутаться.
Apache Airflow для инженеров данных
Код курса
AIRF
Ближайшая дата курса
2 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
А за кулисами TaskFlow API лежит XCom
Так в чем же преимущество использования TaskFlow API? Код, написанный с его помощью, больше соответствует Python style и занимает меньше места [1]. Более того, в таком коде происходит явная передача сообщений между задачами за счет обычного использования функций, которые принимают какие-то аргументы и возвращают какие-то значения.
Airflow 1 не имеет такой особенности. Для кросс-коммуникаций используется механизм XCom, но его выполнение скрыто внутри оператора [2]. В Airflow 2 эту проблему решили с помощью вышеупомянутых декораторов, тем не менее “под капотом” реализуется пресловутый XCom. Например, задача преобразования могла быть переписана с использованием XCom следующим образом:
with DAG(default_args=args, schedule_interval=None, start_date=days_ago(2)):
...
def transform(**kwargs):
ti = kwargs['ti']
extract_data_string = ti.xcom_pull(task_ids='extract', key='order_data')
order_data = json.loads(extract_data_string)
total_order_value = 0
for value in order_data.values():
total_order_value += value
total_value = {"total_order_value": total_order_value}
total_value_json_string = json.dumps(total_value)
ti.xcom_push('total_order_value', total_value_json_string)
transform_task = PythonOperator(
task_id='transform',
python_callable=transform,
)
...
extract_task >> transform_task >> load_task
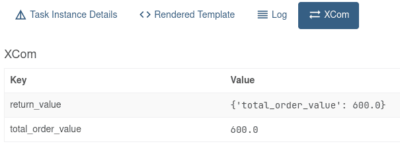
Для получения и передачи сообщения используются методы xcom_pull и xcom_push. Через TaskFlow API мы это делаем через аргументы функции и возвращаемые значения. На рисунке ниже можно увидеть вкладку XCom задачи преобразования на веб-сервере.
Создание шаблонов через обычный комментарий в TaskFlow API
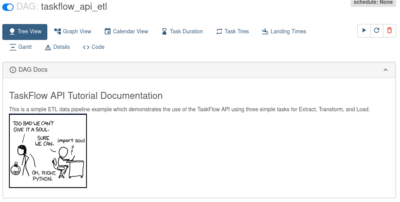
Через TaskFlow удобно создавать документацию к графу и его задачам. Делается это просто — с помощью многострочного комментария. Их нужно ставить сразу после описания графа и/или задачи. Шаблоны Apache Airflow поддерживают разметку Markdown, поэтому можете даже вставлять картинки и ссылки.
@dag(default_args=default_args, schedule_interval=None, start_date=days_ago(2))
def taskflow_api_etl():
"""
### TaskFlow API Tutorial Documentation
This is a simple ETL data pipeline example which demonstrates the use of
the TaskFlow API using three simple tasks for Extract, Transform, and Load.

"""
@task(multiple_outputs=True)
def transform(order_data_dict: dict):
"""
#### Transform task
A simple Transform task which takes in the collection of order data and
computes the total order value.
"""
total_order_value = 0
for value in order_data_dict.values():
total_order_value += value
return {"total_order_value": total_order_value}
Ниже можно увидеть, как отображается полученные комментарии к графу и задаче на веб-сервере Apache Airflow.

Не передавайте данные большого размера через XCOM
Apache Airflow — это оркестратор, а не ETL-инструмент, т.е. он предназначен для управления задачами, а не для передачи данных. Поэтому не используйте встроенный инструмент XCom, если данные имеют большой размер (Big data). Пример выше служит для иллюстрации работы TaskFlow API, но в этом примере задача преобразования мало того, что принимает данные, так ещё их передает. Было бы намного лучше и безопаснее ограничиться двумя задачами:
- Первая задача читает из базы данных, хранилища данных или даже обычного диска и сразу передает результат преобразования (в данном случае суммы заказов) следующей задаче.
- Вторая задача принимает через XCom результат и сохраняет его. Поскольку значение
float— небольшое (не больше 64 байт), то в этом случае мы можем даже воспользоваться XCom.
Иными словами, мы объединили задачи extract и transform в одну и воспользовались внешними инструментами чтения данных, а не положились на ресурсы самого Airflow, который сохраняет промежуточные данные у себя в SQLite, MySQL или PostgreSQL, смотря какие настройки стоят.
В следующей статье расскажем о других операторах, которые можно использовать в связки с TaskFlow API. Ещё больше подробностей о работе с TaskFlow API, о том, как применять его для решения собственных задач, вы узнаете на наших образовательных курсах в лицензированном учебном центре обучения и повышения квалификации руководителей и ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве:
[elementor-template id=»13619″]
Источники