
Реклама является одним из наиболее крупных сегментов практического применения технологий Big Data. Поэтому сегодня рассмотрим, как Flink SQL реализует потоковую аналитику больших данных в AdTech-кейсах. Разбираем пример JOIN-соединения двух потоков событий - показов и кликов, чтобы вычислить конверсию рекламной кампании средствами Apache Flink или Spark. Потоки Big Data за фасадом...
В этой статье для разработчиков распределенных приложений Apache Spark, администраторов SQL-on-Hadoop и дата-аналитиков рассмотрим особенности аутентификации удаленного пользователя, а также отслеживание измененных данных в таблицах Apache Hive. Читайте далее, зачем ограничивать доступ к keytab-файлу в кластерах с поддержкой защищенного протокола Kerberos, а также как реализовать отслеживание медленно меняющихся измерений в...
В поддержку курсов по администрированию Apache Kafka, сегодня рассмотрим особенности масштабирования кластера и связанное с этим переназначение разделов. Читайте далее, чем горизонтальное масштабирование лучше вертикального, как переназначить разделы между брокерами Kafka с целью перебалансировки нагрузки и зачем ограничивать полосу пропускания для перемещения реплик между узлами кластера. Проблемы масштабирования кластера Apache...

В этой статье мы поговорим про функции группировки и сортировки в распределенной СУБД Apache Impala. Читайте далее про особенности работы механизма группировки и сортировки Big Data, которые позволяют Impala-разработчику обрабатывать большие массивы данных любых типов с минимальными временными затратами. Как работает механизм группировки и сортировки данных: особенности обработки Big Data...

В рамках обучения разработчиков Spark-приложений, сегодня рассмотрим, как сохранить датафрейм в памяти вне кучи исполнителя и зачем это нужно. Вас ждет краткий ликбез по управлению памятью в Apache Spark с описанием настраиваемых конфигураций. Также на простом практическом примере разберем, как это сделать и где в пользовательском веб-интерфейсе фреймворка посмотреть результаты...

Сегодня рассмотрим, как построить конвейер потоковой обработки событий на Apache Kafka, Flink и SQL Stream Builder с визуализацией результатов в Grafana. Далее вас ждет практический кейс применения технологий Big Data в реальном производстве на примере телеметрии процессов ферментации продуктов в небольшой частной пивоварне. Постановка задачи: бизнес-контекст и используемые технологии В...
Завершая серию статей по IoT-платформе компании Tesla на базе Apache Kafka, сегодня рассмотрим проблемы пиковой загрузки системы и особенности обработки высокоприоритетных событий. Читайте далее, как оптимально определить ключ раздела, чтобы снизить затраты на передачу данных, избежать перегрузки в пиковые моменты и отделить пользователей данных от разработчиков и дата-инженеров. Тонкости обработки...

В этой статье для дата-инженеров мы собрали лучшие практики построения масштабируемых конвейеров обработки данных, а также популярные рекомендации по проектированию ETL/ELT-процессов с Apache Spark, AirFlow и другими технологиями Big Data. Читайте далее, когда ELT лучше ETL и наоборот, чем хорош Apache Spark в конвейерах обработки Big Data, зачем нужен AirFlow,...
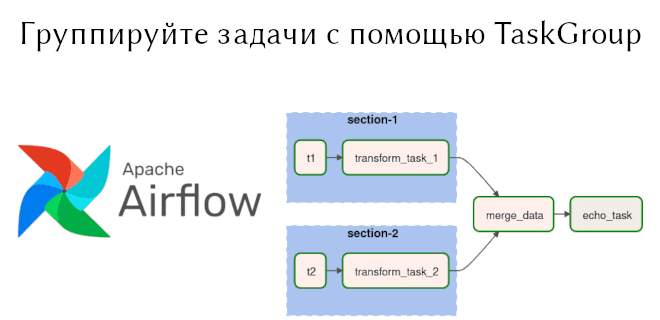
В предыдущей статье мы рассмотрели TaskFlow API, появившийся в Apache Airflow 2.0. Сегодня поговорим о способах задания операторов, отличных от PythonOperator, а также о способе группировки задач TaskGroup. Читайте далее: как сформировать BashOperator, используя TaskFlow API, когда следует использовать TaskGroup, в чем преимущества TaskGroup перед SubDag. Используем Bash Operator в...
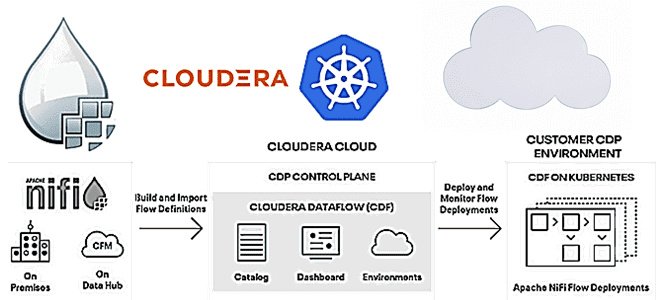
Чтобы сделать наши курсы по Apache NiFi для дата-инженеров еще более полезными, сегодня рассмотрим новые возможности последнего релиза Cloudera Flow Management 2.1.1 на базе этого фреймворка. Выпущенная в апреле 2021 года, платформа Cloudera Flow Management в составе публичного и частного облака предоставляет Apache NiFi версии 1.13.2, включая дополнительные компоненты, а...