 711
711 
Содержание
Мы уже упоминали, что Apache Kafka не слишком хорошо обрабатывает сообщения чрезмерно большого размера. Сегодня рассмотрим, как эта проблема решается в конвейерах потоковой обработки IoT-инфраструктуры Tesla. Читайте далее про модификацию синтаксического анализатора данных от множества устройств интернета вещей с поиском компромисса между скоростью и надежностью с помощью коннектора Alpakka к Kafka и Akka Streams.
Когда данные слишком большие: проблема размера сообщений в IoT-конвейерах
Напомним, Apache Kafka предназначена для обработки множества небольших сообщений, а не огромных файлов. По умолчанию максимальный размер одного пакета сообщений, отправленных в топик, равен 1 МБ. Это задается в конфигурации max.message.bytes на стороне брокера.
В случае Tesla, когда необходимо управлять приемом сообщений от множества устройств интернета вещей, о чем мы писали здесь и здесь, эти данные могут быть разного размера. В частности, из-за случаев нестабильной работы аппаратных устройств некоторые сообщения могут быть больше, чем ожидается. Хотя разработанный дата-инженерами Tesla синтаксический анализатор может обрабатывать большие сообщения в отдельных случаях, задача поддержки потокового конвейера для этих кейсов остается актуальной.
В любом случае, способ обработки больших сообщений зависит от пользовательских требований, а также от особенностей реализации синтаксического анализа. Например, если синтаксический анализатор работает очень быстро, то обработать большое сообщение может быть достаточно просто с его резервным копированием в конвейере обработки. Это означает, что один из разделов топика Kafka будет заблокирован, занятый обработкой большого сообщения. А если таких ситуаций одновременно случается несколько, возможен сбой. Горизонтальное масштабирование не поможет, т.к. перебалансировка потребителей приведет к еще большему отставанию. Самый простой выход – ограничить размер сообщения до определенного лимита через параметр конфигурации max.message.bytes. Это сработает, если IoT-устройство неисправно и отправляет ненужные данные, на обработку и хранение которых не стоит тратить время и ресурсы.
Однако, бывают случаи, когда требуется сохранить все данные. Для этого можно попытаться распараллелить количество записей, анализируемых одновременно, чтобы снизить риски обработки больших сообщений. Например, пока идет работа над первым большим сообщением, можно параллельно работать со следующими N записями, чтобы зафиксировать их по завершении анализа крупного сообщения. Так даже при обработке сразу нескольких больших сообщений подряд, пользователь не видит замедления синтаксического анализа, благодаря распараллеливанию [1]. В Tesla для построения конвейеров потоковой передачи событий используются технологии Alpakka-Kafka и Akka Streams, о которых мы поговорим далее.
Курс Apache Kafka: администрирование кластера
Код курса
KAFKA
Ближайшая дата курса
26 января, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Потоковая обработка данных с Apache Alpakka и Kafka
Apache Alpakka – open-source проект для потоковой и реактивной интеграции конвейеров на Java и Scala. Он изначально построен на основе Akka Streams для потоковой передачи и обеспечения DSL в реактивном поточном программировании. Akka Streams – это Reactive Streams и JDK 9+ java.util.concurrent.Flow-реализация, полностью совместимая с другими реализациями. Коннектор Alpakka Kafka позволяет бесшовно подключать Apache Kafka к Akka Streams. В частности, ранее этот коннектор назывался Akka Streams Kafka и даже Reactive Kafka.
Примечательно, что поскольку клиентский протокол Kafka согласовывает версию для использования с брокером, можно использовать версию клиента, которая отличается от версии брокера.
Существуют два отдельных пакета с именами akka.kafka.scaladsl и akka.kafka.javadsl с API для Scala и Java соответственно. Эти пакеты содержат классы Producer и Consumer с фабричными методами для различных потоков Akka Streams Flow, Sink и Source, которые создают или принимают сообщения в топики Kafka или из них [2]. Пример практического использования Akka Streams для масштабирования потоковых приложений смотрите в нашей новой статье.
В случае Tesla это используется следующим образом, например, реализуя парсер синтаксического анализа больших сообщений с помощью такого Scala-кода [1]:
val (parserParallelism, producerParallelism) = (5, 10) // constants
val producer = new KafkaProducer(…) // create a re-used producer
val parser = Parser(config) // create the parser
val stream = Source(kafka) // a stream of messages from kafka
// each parse happens in parallel
.mapAsync(parserParallelism)(message => Future {
val iterator = parser.parse(message.value())
Source(iterator)
.map(toCanonicalAvroRecord)
// each message can produce records in parallel to a destination topic
.mapAsync(producerParallelism)(producer.produce)
}).forEach(record => record.commit())
Здесь сообщения анализируются параллельно, создавая итератор событий, которые записываются в топик Kafka параллельно, а затем окончательно фиксируются. Оператор mapAsync в Akka-Streams обеспечивает упорядочение, а также параллелизм внутри раздела и записи. Это позволяет анализировать несколько сообщений параллельно, а затем одновременно создавать канонические записи в формате AVRO.
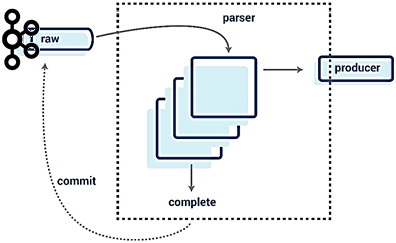
Однако, здесь есть риск при сбое потребителя или перебалансировке в случае параллельного анализа большого количества записей: теперь необходимо повторно анализировать те записи, успех по которым не был зафиксирован. Возможно, потребуется какое-то распределенное состояние, чтобы отслеживать, было ли сообщение проанализировано, даже если оно не было зафиксировано. Это усложняет систему и требует больше ресурсов, в частности, памяти. Альтернативой является буферизация прогресса в памяти, а не отправку событий далее по потоку конвейера. Это также увеличивает объем памяти потребителей, особенно в случае распараллеливания и обработки больших сообщений. Буферизация также означает, что небольшие сообщения, попавшие в эту очередь, не продвигаются далее по потоковому конвейеру, что может быть критично в некоторых бизнес-сценариях с низкой задержкой обработки данных.
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
2 февраля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
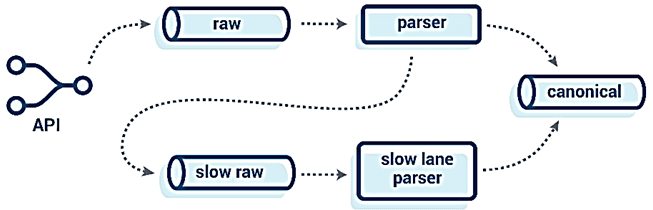
Поэтому дата-инженеры Tesla рассматривали вариант с отделением процессов обработки больших сообщений от единого потокового конвейера, перенаправляя их по другому маршруту в API, чтобы запустить там отдельный набор потребителей с менее строгими SLA по временной задержке. А, чтобы обеспечить стабильную и быструю передачу данных без усложнения API, было решено реализовать это на стороне самого синтаксического анализатора. Парсеру дается ограничение по времени для анализа всех канонических событий из сообщения. Если парсинг не завершается вовремя, попытки синтаксического анализа сообщения прекращаются, а оно само направляется в топик для «медленной обработки» (slow raw). Это помогает упростить API и переносит нагрузку на backend, более толерантному к проблемам повторных попыток и больших сообщений [1]. Сама специфика обработки этих больших и медленных сообщений зависит от конкретного варианта использования и требований, что мы рассмотрим в следующий раз.
Все подробности практического использования Apache Kafka для в потоковых конвейерах и разработке распределенных приложений аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

