
29 июля 2024 года вышло очередное обновление Apache Kafka. Разбираемся с главными новинками релизе 3.8: поддержка JBOD в многоуровневом хранилище, детальная настройка уровня сжатия, улучшение безопасности и удаление неоднозначных конфигураций. ТОП-7 новинок Apache Kafka 3.8 Многоуровневое хранилище (Tiered Storage) для надежного долговременного хранения данных, опубликованных в Kafka, без ущерба высокой...

Какие процессоры Apache NiFi позволяют принимать и обрабатывать данные из различных источников по разным протоколам, и как избежать сбоев при их использовании с удержанием открытых соединений и порты. Listen-процессоры Apache NiFi В Apache NiFi есть целый набор процессов-слушателей, которые принимают и обрабатывают входящие данные из различных источников по разным протоколам....
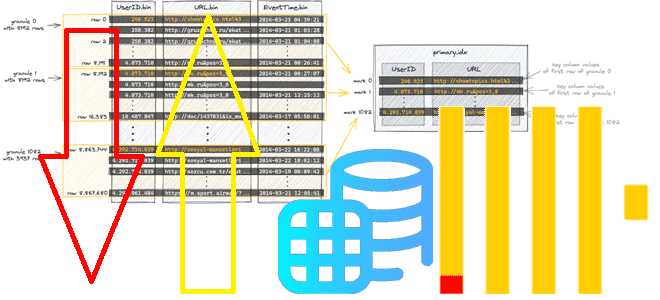
Зачем в ClickHouse 24.6 добавлена настройка optimize_row_order для оптимизации порядка строк MergeTree-таблиц, как она работает и где ее применять. Как связаны индексация и сортировка таблиц в ClickHouse Даже не будучи классической реляционной СУБД, ClickHouse поддерживает индексацию, насколько это возможно в его колоночной природе, индексируя первичным ключом целую группу строк (гранулу)...
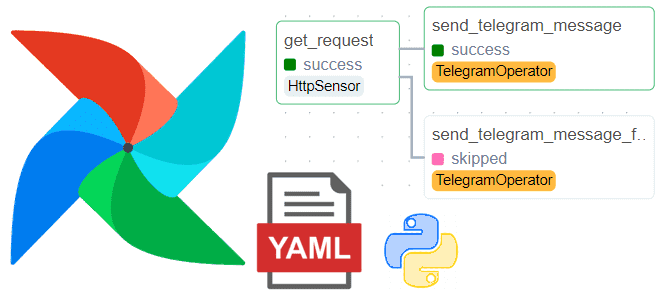
Как написать DAG в Apache AirFlow без программирования, определив его конфигурацию в YAML-файле, и автоматически получить пакетный конвейер обработки данных с помощью Python-библиотеки DAG Factory. Демократизация разработки ETL-конвейеров или что такое DAG Factory в Apache AirFlow Хотя Apache AirFlow и так считается довольно простым фреймворком для оркестрации пакетных процессов и...
Как SQL-запросами соединить потоки из разных топиков Apache Kafka и отправить результаты в Redis: демонстрация ETL-конвейера на материализованных представлениях в RisingWave. Постановка задачи и проектирование потоковой системы Продолжая недавний пример потоковой агрегации данных из разных топиков Kafka с помощью SQL-запросов, сегодня расширим потоковый конвейер в RisingWave, добавив приемник данных –...
Как соединить данные из разных топиков Apache Kafka с помощью пары SQL-запросов: коннекторы, материализованные представления и потоковая база данных вместо полноценного потребителя. Подробная демонстрация запросов в RisingWave. Проектирование и реализация потоковой агрегации данных из Kafka в RisingWave Вчера я показывала пример потоковой агрегации данных из разных топиков Kafka с помощью...
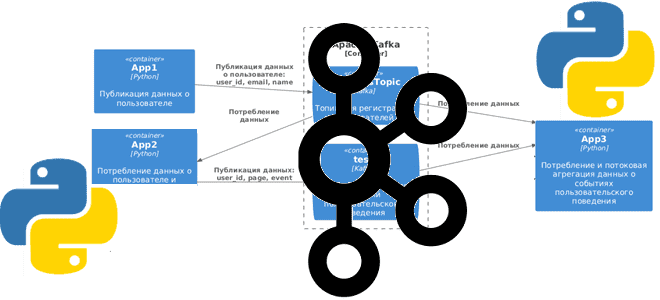
Сегодня я покажу простую демонстрацию потоковой агрегации данных из разных топиков Apache Kafka на примере Python-приложений для соединения событий пользовательского поведения с информацией о самом пользователе. Постановка задачи Рассмотрим примере кликстрима, т.е. потокового поступления данных о событиях пользовательского поведения на страницах сайта. Предположим, данные о самом пользователе: его идентификаторе, электронном...
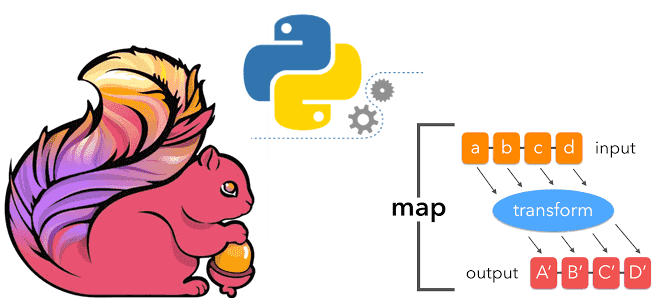
Что такое rich-функции в Apache Flink, зачем они нужны, чем отличаются от обыкновенных UDF и как с ними работать: простой пример на PyFlink с запуском в Google Colab. Rich-функции в Apache Flink Будучи очень мощным фреймворком для разработки распределенных потоковых приложений, Apache Flink не только предоставляет широкий набор stateful-функций, но...

20 июня 2024 года вышел очередной релиз Greenplum. Разбираемся с ключевыми новинками выпуска 7.2: сканирование индекса в AO-таблицах, изменения в оптимизаторе GPORCA, улучшенная обработка геопространственных данных и новая служба централизованного управления сегментами Postmaster. Новинки Greenplum 7.2 для дата-инженера Начнем с изменений, повышающих производительность Greenplum. Одним из них стало сканирование индекса...
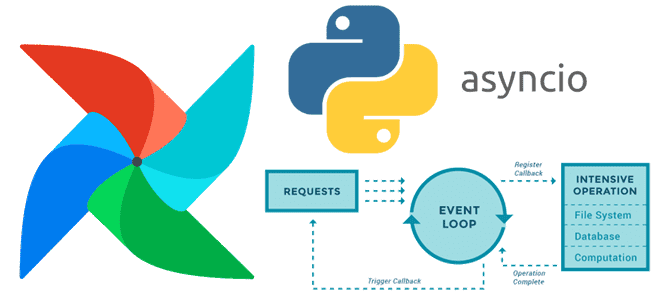
Почему триггеры отсроченных операторов Apache AirFlow не могут быть блокирующими и как сделать их асинхронными с помощью Python-библиотеки asyncio. Создание своего отсроченного оператора в Apache AirFlow О том, что такое отсроченные операторы, как они связаны с триггерами и асинхронными Python-вызовами в Apache AirFlow, мы недавно говорили здесь. Помимо использования существующих...