
Чтобы сделать наши курсы по Greenplum и аналитике больших данных еще более полезными, сегодня рассмотрим особенности выполнения SQL-запросов в этой MPP-СУБД. Читайте далее, зачем и когда запускать оператор анализа табличной статистики ANALYZE, как он связан с планом выполнения SQL-запроса и какие инструменты помогут дата-инженеру, аналитику или разработчику повысить их производительность....
Продвигая наши курсы по Apache Spark для разработчиков, сегодня рассмотрим пользовательские функции и особенности работы с ними в API SQL-модуле этого фреймворка. Читайте далее про идемпотентность UDF-функций и их влияние на распределение данных в кластере Apache Spark. Как устроены UDF в Apache Spark: краткий ликбез Пользовательские функции (User Defined Functions,...

В сферу ответственности дата-инженера входит не только проектирование быстрых и производительных конвейеров обработки данных, но обеспечение их надежности, в т.ч. с точки зрения информационной безопасности. Сегодня рассмотрим, как управлять чувствительной информацией (секретами) в Apache AirFlow, каких видов они бывают, где хранятся и что нужно сделать, чтобы не отображать их в...
Сегодня рассмотрим 2 важных понятия архитектуры распределенных систем для хранения и аналитики больших данных на примере платформы потоковой обработки событий Apache Kafka.Читайте далее, что такое согласованность и полнота, а также в чем преимущества строго однократной доставки сообщений на основе транзакционной записи и фиксации смещений в журналах, и как все это...
В рамках обучения разработчиков Apache Spark, сегодня рассмотрим еще несколько интересных особенностей этого фреймворка, ограничивающих его типовые возможности и на PySpark-примерах разберем, как с этим бороться. Читайте далее, что такое оконные функции и зачем они нужны, как сортировка влияет на фрейм окна в Spark SQL и чем опасны действия над...
Чтобы сделать наши курсы по Apache Spark еще более полезными, мы рассказываем о неочевидных тонкостях этого фреймворка, знание которых позволит разработчику распределенных приложений использовать возможности этой технологии более эффективно. Сегодня на практических примерах PySpark в API DataFrame рассмотрим разницу между функциями сортировки массивов и особенности объединения контенкации, а также разберемся...
Продолжая разговор про вычислительные операции над датафреймами в Apache Spark, сегодня рассмотрим, какие преобразования (transformations) и действия (actions) чаще всего используются при разработке распределенных приложений и аналитике больших данных. Читайте далее, про виды столбцовых преобразования и отличия действия collect() от take(). Преобразования в Apache Spark: виды и особенности реализации Напомним,...
Apache Spark предоставляет для разработчика распределенных приложений множество возможностей, позволяя достигать одной целей разными способами. Чтобы проиллюстрировать это, сегодня рассмотрим бенчмаркинговое сравнение 9 методов обработки массивов в Spark 3.1, обращая внимание на их производительность и особенности использования. Также разберем важные для обучения разработчиков Spark темы про отличия преобразований от действий...
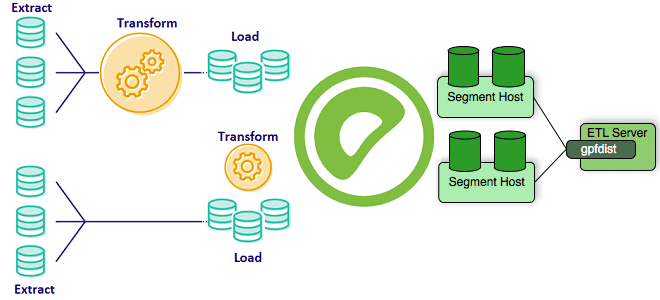
Greenplum часто используется в качестве корпоративного хранилища или аналитического озера данных (Data Lake). Поэтому важно знать особенности реализации ETL-процессов при работе с этой MPP-СУБД, что входит в наш новый курс «Greenplum для инженеров данных». Сегодня рассмотрим способы загрузить большие данные в Greenplum, разберем отличия внешних таблиц от внутренних и отметим,...

Сегодня рассмотрим пример построения системы потоковой аналитики больших данных на базе Apache Kafka, Spark, Flink, NoSQL-СУБД, BI-системой Tableau или визуализацией в Kibana. Читайте далее, кому и зачем исследовать Twitter-посты в реальном времени, как это реализовать технически, визуализировать в наглядных BI-дэшбордах для принятия data-driven решений и при чем здесь Kappa-архитектура. Еще...