 1080
1080 
Содержание
В рамках обучения разработчиков Apache Spark, сегодня рассмотрим еще несколько интересных особенностей этого фреймворка, ограничивающих его типовые возможности и на PySpark-примерах разберем, как с этим бороться. Читайте далее, что такое оконные функции и зачем они нужны, как сортировка влияет на фрейм окна в Spark SQL и чем опасны действия над кэшированными датафреймами.
Что такое оконные функции и зачем они нужны: основы SQL для разработчика Spark
Оконные функции (window funtion) – мощный инструмент аналитика больших данных и SQL-разработчика: они позволяют рассчитывать скользящие средние и кумулятивные суммы, не изменяя исходную выборку, а добавляя к ней дополнительную информацию. Оконные функции применяются к набору строк, связанных с текущей строкой, и чаще всего используются для агрегирования и других аналитических операций. В отличие от обычного агрегирования, window-функции не группируют несколько строк в одну, хотя аналогично агрегатным могут обращаться не только к текущей строке результата запроса. Например, при обычном запросе все множество строк обрабатывается единым объемом, для которого считаются агрегаты. А в оконных функциях, запрос делится на части (окна), для каждой из которых рассчитываются свои агрегаты. Окно – это набор строк, или отношение, предоставляемые как входные данные для этапа обработки логического запроса, это стандартный термин SQL для описания контекста, в котором работает window-функция.
В оконных функциях для каждой строки существует набор строк в её разделе — рамка окна или фрейм [1].
Таким образом, главными плюсами оконных функций можно назвать следующие [2]:
- нет группировки набора данных для расчетов, т.е. сохраняются все строки исходного набора данных с их уникальными идентификаторами, а результаты просто добавляются к результирующей выборке как еще одно поле, например, агрегированное значение добавляется к каждой строке;
- оконные функции лучше поддаются оптимизации, чем обычные агрегатные;
- лаконичность и простота SQL-запроса — сокращение кода за счет готовых конструкций разных оконных функций, которые мы рассмотрим далее.
Оконные функции в SQL начинаются с оператора OVER и настраиваются с помощью операторов PARTITION BY, ORDER BY и ROWS. ANSI-стандарт SQl поддерживает несколько типов оконных функций [1, 2]:
- агрегатные — функции агрегирования (SUM, COUNT, AVG, MIN, МАХи прочие, обычно используемые в контексте групп запросов). Эти функции работают на наборе данных, определенном групповым запросом или рамками окна, выполняют арифметические вычисления и возвращают итоговое значение.
- ранжирующие, которые ранжируют значение для каждой строки в окне (ROW_NUMBER, RANK, DENSE_RANK, NTILE). Полезны, когда, например, нужно чтобы присвоить порядковый номер строке или составить рейтинг.
- аналитические (функции распределения) – возвращают информацию о распределении данных, используются для статистического анализа данных (PERCENT_RANK, CUME_DIST, PERCENTILE_CONTи PERCENTILE_DISC);
- функции сдвига (смещения), которые позволяют перемещаться и обращаться к разным строкам в окне относительно текущей строки, а также к значениям в начале или в конце окна (LAG, LEAD, FIRST_VALUE, LAST, VALUEи NTH_VALUE).
Таким образом, оконные функции можно применять для разбиения на страницы, устранения дублей, вычисления нарастающих итогов, процентилей, режима распределения и максимального числа параллельных сеансов, возврата первых n строк в каждой группе, интервальных операций, нахождение пробелов и диапазонов [2].
Как и многие фреймворки аналитики больших данных, а также средства SQL-разработки, Apache Spark поддерживает концепцию оконных функций в API DataFrame. Официальная документация Apache Spark отмечает, что оконные функции полезны для вычисления скользящего среднего, совокупной статистики и доступа к значению строк с учетом относительного положения текущей строки [3]. Однако, с использованием window-функций в Spark SQL связан ряд особенностей, одну из которых мы рассмотрим далее.
Анализ данных с помощью современного Apache Spark
Код курса
SPARK
Ближайшая дата курса
1 июня, 2026
Продолжительность
32 ак.часов
Стоимость обучения
102 400
Сортировка и размер фрейма оконных функций в Apache Spark SQL
Общий синтаксис оконной функции в Spark SQL выглядит так [3]:
window_function OVER
( [ { PARTITION | DISTRIBUTE } BY partition_col_name = partition_col_val ( [ , ... ] ) ]
{ ORDER | SORT } BY expression [ ASC | DESC ] [ NULLS { FIRST | LAST } ] [ , ... ]
[ window_frame ] )
Фрейм окна задается через RANGE или ROWS и может быть ограничен или смещаться по мере продвижения по строкам таблицы. Если конец фрейма не указан явно, то он ограничивается текущей строкой по умолчанию [3].
В Spark SQL окно определяется следующим образом [4]:
w = Window().partitionBy(key)
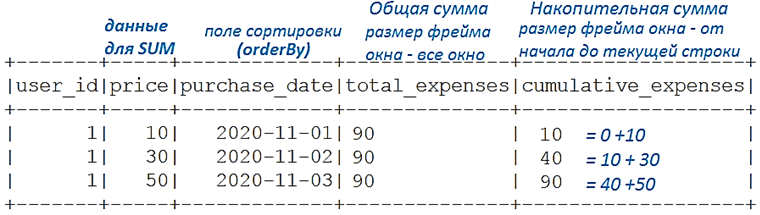
Это окно можно отсортировать, вызвав orderBy(key), а указать фрейм с помощью rowsBetween или rangeBetween. Фрейм определяет, в каких строках будет вызываться оконная функция внутри окна. Некоторые функции, например, row_count, требуют сортировки окна, а для каких-то это не обязательно. Но сортировка может изменить фрейм, что на первый взгляд неочевидно. Рассмотрим пример на PySpark для вычисления суммы покупок пользователя (user_id) в один день (purchase_date):
from pyspark.sql import Window
from pyspark.sql.functions import suml = [
(1, 10, '2020-11-01'),
(1, 30, '2020-11-02'),
(1, 50, '2020-11-03')
]df = spark.createDataFrame(l,['user_id', 'price',
'purchase_date'])w1 = Window().partitionBy('user_id')
w2 = Window().partitionBy('user_id').orderBy('purchase_date')(
df
.withColumn('total_expenses', sum('price').over(w1))
.withColumn('cumulative_expenses', sum('price').over(w2))
).show()
Таким образом, сортировка окна изменила фрейм от начала до текущей строки, и при суммировании получена кумулятивная сумма (накопительный итог), а не общая. Если не использовать сортировку, то фреймом по умолчанию будет все окно, и операция SUM даст общую сумму.
Изменение кэшированных данных
Кэширование данных в Apache Spark – отличный способ повысить производительность приложения за счет повторного использования некоторых вычислений. Но этот подход имеет ряд особенностей, о чем мы подробно рассказывали здесь. Само по себе кэширование является ленивым (отложенным) преобразованием, т.е. оно выполняется не сразу, а только после вызова какого-то действия. О том, чем действия над датафреймами в Apache Spark отличаются от преобразований, читайте в этой статье.
Дополнительно отметим еще одну неочевидную особенность Spark SQL, связанную с кэшированием записей в таблицах, куда добавляются данные. В частности, если кэш основан на таблице, где только что добавлены или перезаписаны данные, то они будут сканироваться и снова кэшироваться, при вызове другого действия.
Рассмотрим пример на PySpark, когда в кэшированную таблицу А (tableA) добавляются новые данные и она снова помещается в кэш-память, хотя ее содержимое было изменено.
df = spark.table(tableA)
df.cache()
df.count()
dx.write.mode('append').option('path', path).saveAsTable(tableA)
df.count()
Таким образом, вызов того же вычисления (действие count() – вычисление количества строк) для кэшированного DataFrame потенциально может привести к другому результату, если данные этого датафрейма были изменены [4]. Удалить данные из кэша поможет инструкция spark.sql(«uncache table table_name»).
Смотрите в нашей новой статье возможности и ограничения сеансовых окон в Apache Spark Structured Streaming.
Core Spark - основы для разработчиков
Код курса
CORS
Ближайшая дата курса
1 июня, 2026
Продолжительность
16 ак.часов
Стоимость обучения
51 200
Больше деталей про возможности и ограничения Apache Spark, а также способы их эффективного использования для разработки распределенных приложений и аналитики больших данных, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
[elementor-template id=»13619″]
Источники

