 381
381 
Содержание
Продвигая наши курсы по Apache Spark для разработчиков, сегодня рассмотрим пользовательские функции и особенности работы с ними в API SQL-модуле этого фреймворка. Читайте далее про идемпотентность UDF-функций и их влияние на распределение данных в кластере Apache Spark.
Как устроены UDF в Apache Spark: краткий ликбез
Пользовательские функции (User Defined Functions, UDF) в Apache Spark SQL — это программируемые пользователем процедуры, которые работают с одной строкой. Для работы с ними фреймворк предоставляет методы класса UserDefinedFunction [1]:
- asNonNullable() – обновляет UDF до значения, не допускающего NULL;
- asNondeterministic() – обновляет UDF до недетерминированного значения;
- withName(name: String) – обновляет UDF с заданным именем.
Например, следующий участок Java-кода показывает определение и регистрацию пользовательской функции с 2-мя аргументами [1]:
UserDefinedFunction strLen = udf(
(String s, Integer x) -> s.length() + x, DataTypes.IntegerType
);
spark.udf().register("strLen", strLen);
Также Spark SQL позволяет разработчику определять агрегатные функции (User-Defined Aggregate Function, UDAF) — программируемые пользователем процедуры, которые действуют одновременно с несколькими строками и в результате возвращают одно агрегированное значение. UDAF-функции для строго типизированных наборов данных основаны на методах абстрактного класса Aggregator[-IN, BUF, OUT]. Этот базовый класс для определяемых пользователем агрегатов можно использовать в операциях с наборами данных, чтобы взять все элементы группы и уменьшить их до одного значения, задав следующие параметры [2]:
- IN — тип ввода для агрегирования;
- BUF — Тип промежуточного значения уменьшения;
- OUT — Тип конечного результата вывода;
Следующий участок Java-код показывает, что пользовательская агрегатная функция MyAverage() основана на базовом классе Aggregator<Employee, Average, Double> [2]:
public static class MyAverage extends Aggregator<Employee, Average, Double> {
…
}
Типизированные агрегаты могут быть зарегистрированы как нетипизированные агрегирующие UDF для использования с датафреймами, например, на Java это будет выглядеть так:
spark.udf().register(«myAverage», functions.udaf(new MyAverage(), Encoders.LONG()));
На Scala определение класса MyAverage и его регистрация для использования с датафреймами выглядит следующим образом [2]:
object MyAverage extends Aggregator[Long, Average, Double] {
…
}
spark.udf.register("myAverage", functions.udaf(MyAverage))
Разобравшись с основами UDF-функций в Apache Spark, далее рассмотрим, что с ними не так и почему не стоит их использовать без лишней необходимости.
Накладные расходы и идемпотентность UDF-функций
При том, что UDF позволяют расширить типовой набор возможностей API-интерфейсов Apache Spark, пользовательские функции приводят к снижению производительности, особенно при реализации кода на Python (PySpark), о чем мы рассказывали в этом материале. Кроме того, если UDF выполняется чаще, чем ожидалось, накладные расходы увеличиваются еще больше. Избежать этого поможет контроль за количеством выполнения UDF-функций, связанный с понятием детерминированности, которое мы разбирали здесь.
Напомним, в программировании функция считается детерминированной, если для одного и того же набора входных значений она возвращает одинаковый результат. Недетерминированные функции могут возвращать разные значения при одинаковых входных аргументах [3]. Таким образом, чтобы Apache Spark выполнял пользовательскую функцию только один раз, она должна быть недетерминированной, т.к. ее повторные вызовы фреймворк считает небезопасными. Разумеется, такое решение проблемы идемпотентности накладывает некоторые ограничения на оптимизатор, т.к. недетерминированные функции обрабатываются им без использования фильтра в физическом плане запроса, который сокращает объем обрабатываемых данных, чтобы ускорить вычисления [4].
От перемены мест меняется результат: распределение данных и пользовательские функции
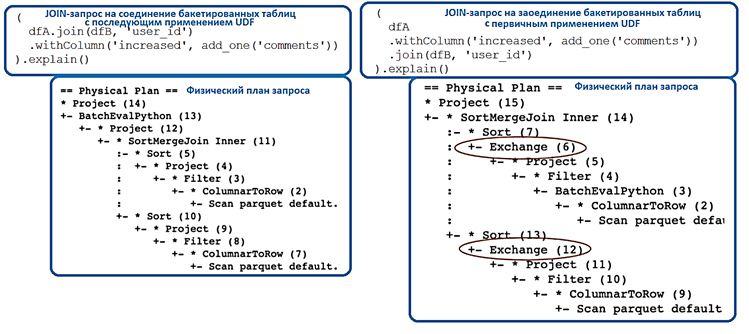
UDF может изменить характер распространения данных. К примеру, необходимо объединить две бакетированные таблицы и вызвать UDF для одного из столбцов. Подробнее о том, что такое бакетирование таблиц в Spark SQL, как оно устроено и зачем это нужно, мы писали в этой статье. Бакетирование позволит выполнить соединение без перемешивания, но нужно вызвать преобразования в правильном порядке. Рассмотрим запрос соединения 2-х таблиц dfA и dfB, бакетированных по столбцу user_id на одинаковое количество бакетов:
(
dfA.join(dfB, 'user_id')
.withColumn('increased', add_one('comments'))
).explain()
UDF (add_one) применяется к одному из столбцов из таблицы dfA. В физическом плане этого запроса нет оператора Exchange, он будет выполняться без перемешивания, т.к. Spark знает о распределении данных и может использовать их для соединения.
Однако, если сперва применить UDF к столбцу таблицы dfA, а затем выполнить соединение с таблицей таблицы dfB, физический план будет выглядеть по-другому.
(
dfA
.withColumn('increased', add_one('comments'))
.join(dfB, 'user_id')
).explain()
В физическом плане появится целых 2 оператора Exchange в плане, т.е. Spark перетасует оба датафрейма перед соединением, т.к. вызов UDF удалил информацию о распределении данных, и теперь Spark не знает, как распределены данные и перераспределяет их самостоятельно. Таким образом, хотя вызов UDF на самом деле не уничтожает распределение, он удаляет информацию о нем, поэтому фреймворк предполагает, что данные распределяются случайным образом и старается изменить это [4]. Как это может вылиться в проблему на практике и каким образом бороться с этой ситуацией, рассматривается в нашей новой статье.
Узнайте больше особенностей Apache Spark, чтобы эффективно использовать его для разработки распределенных приложений и аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источники

