 727
727 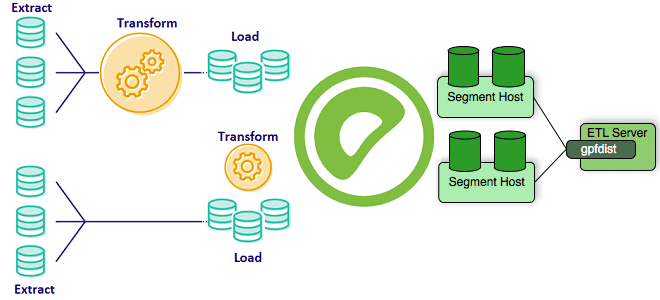
Содержание
Greenplum часто используется в качестве корпоративного хранилища или аналитического озера данных (Data Lake). Поэтому важно знать особенности реализации ETL-процессов при работе с этой MPP-СУБД, что входит в наш новый курс «Greenplum для инженеров данных». Сегодня рассмотрим способы загрузить большие данные в Greenplum, разберем отличия внешних таблиц от внутренних и отметим, какие параметры конфигурации помогут ускорить загрузку.
INSERT и COPY в Greenplum: почему вставки и копирования недостаточно для Big Data
Самыми простыми способами загрузки данных в Greenplum являются следующие:
- вставка (INSERT) со значениями столбцов — одноэлементный оператор INSERT со значениями добавит в таблицу одну строку. Данные проходят через мастер-узел и распределяются по сегменту. Это самый медленный способ загрузки, который не подходит для больших объемов данных.
- копирование (COPY) – этот оператор PostgreSQL копирует данные из внешнего файла в таблицу базы данных, делая это более эффективно, чем вышерассмотренный оператор INSERT. Но строки по-прежнему проходят через мастер-узел, а все данные копируются одной командой, т.е. это не параллельный процесс. Поэтому этот способ загрузки из файла или стандартного ввода подходит для добавления относительно небольших наборов данных, например, таблиц измерений до 10 000 строк или однократной загрузки данных. При этом, поскольку COPY является отдельной командой, при использовании этого метода для заполнения таблицы не стоит отключать автоматическую фиксацию (autocommit). Для повышения производительности можно запустить несколько команд COPY одновременно. Подробнее об этом читайте в нашей новой статье.
Для загрузки больших объем данных в Greenplum существуют специальные утилиты: gpfdist и gpload, ориентированные на так называемые внешние таблицы. Что это такое и как работают gpfdist и gpload, мы рассмотрим далее.
Что такое внешние таблицы и их роль в ETL/ELT-процессах GP
Внешние таблицы обеспечивают доступ к данным в источниках за пределами Greenplum. Доступ к ним можно получить с помощью SQL-операторов SELECT, и они обычно используются с ELT/ETL-шаблонами с быстрой параллельной загрузкой данных в эту MPP-СУБД. Напомним, в рамках ETL-процессов данные извлекаются из источника, преобразуются вне СУБД с помощью внешних инструментов преобразования, например, Informatica или Datastage, а затем загружаются в базу. С помощью ELT внешние таблицы Greenplum обеспечивают доступ к данным во внешних источниках: текстовые, CSV- или XML-файлы только для чтения, веб-серверы, файловые системы Hadoop HDFS, исполняемые программы операционной системы или файл таблицы фактов gpfdist. Внешние таблицы поддерживают различные SQL-операции: выбор, сортировка и объединение, поэтому данные можно загружать и преобразовывать одновременно или загружать в таблицу загрузки и преобразовывать в целевые таблицы СУБД.
В Greenplum внешняя таблица определяется с помощью оператора CREATE EXTERNAL TABLE с условиями LOCATION для задания местоположения данных и FORMAT для форматирования исходных данных, чтобы система могла анализировать входные данные. Файлы используют протокол file:// и должны находиться на узле сегмента в месте, доступном суперпользователю Greenplum (superuser). Данные могут быть распределены между узлами сегмента не более одного файла на основной сегмент на каждом узле. Количество файлов, перечисленных в условии LOCATION, — это количество сегментов, которые будут читать внешнюю таблицу параллельно.
Как работать с внешними таблицами Greenplum: утилиты gpfdist и gpload
Самый быстрый способ загрузить большие таблицы фактов — использовать внешние таблицы с утилитой gpfdist. Эта программа файлового сервера использует протокол HTTP, чтобы параллельно обслуживать внешние файлы данных для сегментов Greenplum. Экземпляр gpfdist может обрабатывать 200 МБ/с, при этом многие процессы gpfdist выполняются одновременно, каждый из которых обслуживает часть данных, подлежащих загрузке.
При старте загрузки с помощью SQL-выражения INSERT INTO <table> SELECT * FROM <external_table>, оператор INSERT анализируется мастером и распределяется по основным сегментам. Сегменты подключаются к серверам gpfdist и получают данные параллельно, анализируя и проверяя их, вычисляют хэш из данных ключа распределения и, на основе этого хеш-ключа, отправляют строку в целевой сегмент. По умолчанию каждый экземпляр gpfdist принимает до 64 соединений от сегментов. Поскольку в нагрузке участвует множество сегментов и серверов gpfdist, данные могут загружаться с очень высокой скоростью. Чтобы повысить производительность gpfdist, можно повысить параллелизм, увеличив количество сегментов через параметр конфигурации gp_external_max_segs. Он устанавливает количество сегментов, которые будут сканировать данные внешней таблицы во время операции с ней, чтобы не перегружать систему данными сканирования и не отвлекать ресурсы от других параллельных операций. Это применимо только к внешним таблицам, которые используют протокол gpfdist:// для доступа к ее данным. По умолчанию значение параметра gp_external_max_segs равно 64 — количество сегментов, обслуживаемых каждым процессом gpfdist. Изменить эту настройку можно в файле конфигурации postgresql.conf на главном сервере. Важно задавать значение gp_external_max_segs и количество процессов gpfdist четным числом, чтобы gp_external_max_segs было кратно количеству процессов gpfdist.
Кроме того, следует распределять данные равномерно по как можно большему числу узлов ETL, разделяя очень большие файлы на равные части и записывая их в несколько файловых систем. Загрузка выполняется со скоростью самого медленного узла. Перекос при загрузке файлов приведет к тому, что общая нагрузка на этот ресурс станет узким местом.
Перед загрузкой данных в Greenplum с помощью gpfdist рекомендуется удалять индексы и создавать их заново после загрузки. Создание индекса для уже существующих данных будет быстрее, чем его постепенное обновление по мере загрузки каждой строки. Дополнительное ускорение даст отключение автоматического сбора статистики во время загрузки, задав параметру конфигурации gp_autostats_mode значение NONE. По окончании загрузки следует запустить анализ таблицы (ANALYZE) и очистку (VACUUM), чтобы освободить место от ошибок и других промежуточных данных. Подробнее о том, зачем нужен оператор ANALYZE и как он работает, читайте в нашей новой статье. А про использование утилиты gpfdist для выгрузки данных во внешние системы вы узнаете в здесь.
Наконец, следует помнить, что небольшие высокочастотных загрузки данных в партиционированные таблицы с ориентацией на столбцы может влиять на систему из-за большого количества физических файлов, к которым осуществляется доступ в локальный период времени. Поэтому для некоторых случаев подойдет gpload – утилита загрузки данных, которая действует как интерфейс для параллельной загрузки внешних таблиц Greenplum. Ее следует применять с осторожностью, т.к. она может вызвать раздувание каталога из-за создания и удаления внешних таблиц. Gpfdist обеспечивает лучшую производительность, чем gpload. Gpload выполняет загрузку, используя спецификацию, определенную в YAML-файле управления, за одну транзакцию выполняя следующие операции:
- вызов процессов gpfdist;
- определение временной внешней таблицы на основе исходных данных;
- осуществление операций INSERT, UPDATE или MERGE для загрузки исходных данных в целевую таблицу СУБД;
- удаление временной внешней таблицы;
- очистка процессов gpfdist.
Освойте администрирование и эксплуатацию Greenplum и Arenadata DB для эффективного хранения и аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Greenplum для инженеров данных
- Greenplum для инженеров данных
- Администрирование Greenplum / Arenadata DB
- Интеграция Hadoop и NoSQL
[elementor-template id=»13619″]
Источники

