 433
433 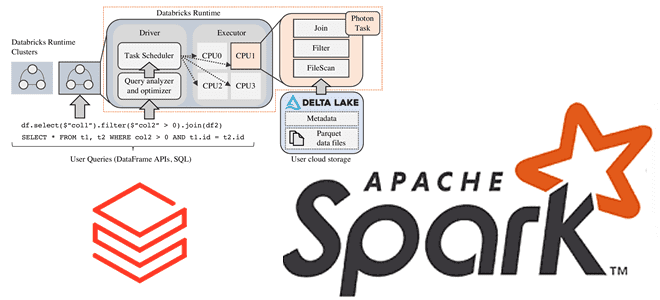
Содержание
Зачем Databricks выпустила новый движок выполнения запросов Spark SQL для ML-приложений, как он работает и где его настроить: возможности и ограничения Photon Engine.
Преимущества Photon Engine для ML-нагрузок Spark-приложений
Чтобы сделать Apache Apark еще быстрее, разработчики Databricks выпустили новый движок выполнения запросов — Photon Engine. Это высокопроизводительный механизм запросов, который может быстрее запускать Spark SQL и выполнят вычисления над датафреймами, снижая общую стоимость рабочей нагрузки. Под капотом Photon реализован на C++, а некоторые исполнительные блоки Spark заменены собственной реализацией движка Photon. По сравнению с Java, C++ более эффективен при работе с памятью: этот язык разработки предоставляет явный контроль над конвейеризацией памяти и инструкциями SIMD. Также в программах C++ нет очистки мусора, что характерно для Java. Несмотря на то, что Photon написан на C++, он напрямую интегрируется с Databricks Runtime и Spark, написанными на Java и Scala. Поэтому для использования Photon не требуется никаких изменений кода.
Ключевыми преимуществами Photon считаются следующие:
- поддержка SQL и эквивалентных операций DataFrame с таблицами Delta и Parquet;
- ускоренные запросы, которые быстрее обрабатывают данные, включая агрегации и соединения;
- повышенная производительность при многократном доступе к данным из кэша диска;
- быстрое сканирование таблиц с большим количеством столбцов и множества небольших файлов;
- ускоренная мутация данных в таблицах Delta и Parquet с использованием операторов UPDATE, MERGE, INSERT, CREATETABLE AS SELECT и DELETE, включая широкие таблицы с тысячами столбцов;
- автоматическая замена соединения типа сортировка-слияние на хеш-соединения, которые быстрее;
Таким образом, для рабочих нагрузок, связанных с ИИ и машинным обучением, Photon повышает производительность приложений, использующих Spark SQL и API DataFrame, а также GraphFrames и xgboost4j. Выгоды от включения Photon Engine особенно заметны при работы с большими таблицами, что часто встречается в задачах машинного обучения. В частности, обучение высококачественной ML-модели требует тщательной подготовки данных и признаков. Для полного использования необработанных данных, хранящихся в виде таблиц, может потребоваться запуск конвейеров ETL и преобразование необработанных данных в полезные таблицы признаков. Если таблица большая, этот шаг может занять очень много времени. Поэтому в среде исполнения ML-нагрузок Databricks Machine Learning Runtime можно сразу включить Photon Engine, способный ускорить задания Spark и рабочие нагрузки по проектированию признаков в 2 раза и более. Для более эффективного выделения признаков (фичей) обучения ML-модели в библиотеке Databricks Feature Engineering реализована новая версию соединения по точкам времени для данных временных рядов. Эта реализация использует нативный Spark вместо библиотеки Tempo, улучшая ее масштабируемость и надежность по сравнению с предыдущей версией. Более того, нативная реализация Spark получает преимущества от использования Photon Engine:
- при соединении таблицы признаков из 10 млн строк (10 тысяч уникальных идентификаторов с 1000 временными метками на идентификатор) с таблицей меток (100 тысяч уникальных идентификаторов с 100 временными метками на идентификатор) Photon ускоряет соединение в 2 раза;
- при соединении таблицы признаков из 100 млн строк (100 тысяч уникальных идентификаторов) Photon ускоряет JOIN-операцию в 2 раза;
- при соединении таблицы признаков из 1 млрд строк (1 млн уникальных идентификаторов) Photon ускоряет соединение почти в 2,5 раз.
Познакомившись с преимуществами Photon Engine, далее рассмотрим, как он работает.
Принципы работы и ограничения нового движка
Когда клиент отправляет заданный запрос или команду драйверу Spark, он анализируется, а оптимизатор Catalyst выполняет анализ, планирование и оптимизацию. Эти процессы с механизмом Photon происходят также, как и при его отсутствии. Единственное отличие заключается в том, что Photon-движок выполняет обход по физическому плану и определяет, какие части могут выполниться этим быстрым механизмом. В план для Photon могут быть внесены незначительные изменения, например, изменение соединения сортировки слиянием на хэш-соединение. Общая структура плана, включая порядок соединения, останется прежней. Поскольку Photon пока не поддерживает все функции Spark, один запрос может выполняться частично в Photon и частично в Spark. Эта гибридная модель выполнения полностью прозрачна для пользователя.
Затем план запроса разбивается на атомарные единицы распределенного выполнения, называемые задачами для запуска в потоках на рабочих узлах, которые работают с определенным разделом данных. Именно на этом уровне движок Photon выполняет свою работу. Это похоже на замену всего этапа кодогенерации Spark на собственную реализацию движка. Библиотека Photon загружается в JVM, а Spark и Photon взаимодействуют через JNI (Java Native Interface), передавая указатели данных в память вне кучи. Photon также интегрируется с менеджером памяти Spark для скоординированного сброса в смешанных планах. И Spark, и Photon настроены на использование памяти вне кучи и координацию в условиях нехватки памяти.
Будучи векторизованным движком, Photon работает с пакетной столбцовой структурой данных. Для каждого вектора столбцов есть буфер значений и байтовый вектор, содержащий NULL-ность каждого значения. Список позиций хранит индексы строк в пакете, которые являются активными. Например, строки фильтруются из операции Filter путем удаления индексов из списка позиций. В большинстве случаев это дополнительное отслеживание указателей снижает производительность кэша. Но объем активных строк обычно намного меньше размера пакета, поэтому такой дополнительный уровень обходится дешевле, чем итерация по всем строкам с SIMD. Наличие отдельного вектора байтов NULL и списка позиций позволяет наиболее интенсивным циклам в Photon быть адаптивными и оптимизированными.
Ядро Photon — это небольшая повторно используемая единица высокооптимизированного шаблона C++, иногда с вручную созданными встроенными функциями SIMD. Работа, выполняемая в ядрах Photon, является функцией данных, независимой от формы запроса, координации и т. д. Эти ядра имеют очень оптимизированы, поскольку большая часть интенсивной работы ЦП выполняется в узких циклах. С помощью шаблонов ядра могут быть специализированы, а определенный код может быть исключен для высокой производительности.
Выполнение Photon происходит снизу вверх: оно начинается с оператора сканирования таблицы и продолжается вверх по DAG, пока не встретится с неподдерживаемой операцией. В этот момент выполнение передается классическому механизму Spark: остальные операции будут выполняться без Photon.
Поскольку данные в LakeHouse могут иметь различную структуру, чтобы справиться с этой неопределенностью, Photon во время выполнения создает метаданные о пакете столбцов и использует их для оптимизации своего выбора ядер. Каждое ядро может адаптироваться как минимум к двум переменным: NULL-ness и activity. Другие специализации включают ASCII вместо unicode, UUID и пр. Дизайн довольно гибкий, поскольку каждое ядро Photon может принимать локализованные решения, что хорошо адаптируется с учетом неопределенности рабочей нагрузки.
Движок Photon по умолчанию включен на кластерах, работающих под управлением Databricks Runtime 9.1 LTS и выше. Также Photon доступен на кластерах, работающих под управлением Databricks Runtime 15.2 for Machine Learning и выше. Чтобы вручную отключить или включить Photon на кластере, надо указать использование ускорения Photon при создании или редактировании кластера. В случае создания кластера с помощью API кластеров, надо установить параметру runtime_engine значение PHOTON.
Несмотря на все преимущества нового исполнительного механизма для ML-нагрузок Spark-приложения, он имеет следующие ограничения:
- Spark Structured Streaming с использованием Photon пока поддерживает только stateless-нагрузки с данными в форматах Delta, Parquet, CSV и JSON. Для потоковых источников Kafka и Kinesis потоковая передача возможна также без сохранения состояния и поддерживается при потреблении данных в приемник Delta или Parquet.
- пользовательские функции (UDF) и RDD API не поддерживаются;
- включение Photon не влияет на довольно быстрые запросы, которые сами по себе обычно выполняются менее чем за две секунды.
Тем не менее, несмотря на эти ограничения, можно сделать вывод, что новая разработка Databrics существенно повышает эффективность Spark-приложений, выполняющих вычисления над большими и широкими таблицами, что часто встречается в ML-нагрузках. Поэтому в сценариях, связанных с использованием ИИ, этот новый движок выполнения может быть очень полезным.
Больше подробностей про Apache Spark и его применение для разработки приложений машинного обучения и аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Потоковая обработка в Apache Spark
- Анализ данных с Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источники

