 1033
1033 
Содержание
Чем DataSet API отличается от DataStream, зачем переходить с наборов на потоки данных в Apache Flink и как это сделать: эквивалентные и неподдерживаемые методы преобразования данных.
Разница между DataStream и DataSet API
Исторически в Apache Flink было 3 высокоуровневых API: DataStream/DataSet, Table и SQL. О возможностях и ограничениях каждого из них мы писали здесь. API DataSet и DataStream в Flink реализуют преобразования наборов и потоков данных: фильтрацию, отображение, соединение, группировку. Наборы и потоки данных изначально создаются из определенных источников, например, путем чтения файлов или из локальных коллекций. Для указания источников данных среда выполнения имеет несколько методов чтения из файлов с использованием различных методов: можно просто читать их построчно как файлы, из сокета, коллекции или из внешней системы (Kafka, база данных и пр.).
Результаты возвращаются через приемники, которые могут, например, записывать данные в (распределенные) файлы или в стандартный вывод, к примеру, терминал командной строки. Эти программы Flink работают в различных контекстах, автономно или встроенными в другие программы. Выполнение может происходить в локальной JVM или на кластерах из многих машин.
Начиная с версии 1.12, DataSet API считается устаревшим и будет удален в релизе Flink 2.0. Рекомендуется перейти с DataSet API на DataStream, Table или SQL. Не все методы API DataSet однозначно соответствуют API DataStream. Для одних миграция не требуется практически никаких изменений, для других нужно существенно изменить код приложения, а некоторые функции DataSet вообще не поддерживаются и не имеют эквивалента в DataStream. В любом случае, первым шагом миграции Flink-приложения с API DataSet на API DataStream является замена ExecutionEnvironment на StreamExecutionEnvironment. Например, вместо следующих методов в API DataSet, которые создают текущее (локальное или удаленное) окружение выполнения Flink-программы
- getExecutionEnvironment();
- createLocalEnvironment();
- createRemoteEnvironment(String host, int port, String… jarFiles);
в API DataStream придется использовать аналогичные эквиваленты:
- getExecutionEnvironment();
- createLocalEnvironment();
- createRemoteEnvironment(String host, int port, String… jarFiles);
А метод CollectionEnvironment() в API DataSet, который создает окружение выполнения для коллекций, чтобы запускать программы с использованием Java-коллекций, не поддерживается в API DataStream.
Обычно используется метод getExecutionEnvironment(), выполнение которого зависит от контекста: при локальном выполнении он создаст локальную среду и выполнит программу на локальной машине. Если создан JAR-файл из программы и вызван через командную строку, менеджер кластера Flink выполнит основной метод и getExecutionEnvironment() вернет среду выполнения для выполнения программы на кластере.
Возможности и ограничения DataStream API в Apache Flink
API DataStream получил свое название от специального класса DataStream, который используется для представления коллекции данных в программе Flink. Эти неизменяемые коллекции данных могут содержать дубликаты. Хотя поток данных похож на обычную Java-коллекцию с точки зрения использования, но довольно сильно отличается в некоторых ключевых аспектах. Поскольку потоки данных неизменяемы, после их создания нельзя добавлять или удалять элементы. Однако, можно не просто проверять элементы внутри, а только работать с ними, используя преобразования, т.е. операции DataStream API. Можно создать начальный поток, добавив источник данных в программу Flink. Затем можно вывести из него новые потоки и соединить их с помощью методов API, таких как map(), filter(), и пр.
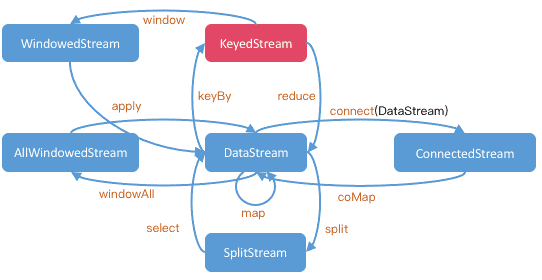
Например, следующий код берет строковый поток данных, преобразует каждую строку в целое число и возвращает новый поток данных, содержащий эти целые числа:
DataStream<Integer> parsed = input.map(new MapFunction<String, Integer>() {
@Override
public Integer map(String value) {
return Integer.parseInt(value);
}
});
Метод map() применяется к исходному потоку данных input, который содержит элементы типа String. Создается анонимный класс, который реализует интерфейс MapFunction. Этот интерфейс требует реализации метода map(), который принимает один элемент типа String и возвращает элемент типа Integer. Реализуется метод map(), который переопределяет метод из интерфейса MapFunction. Он принимает строку value и возвращает её целочисленное представление, используя метод Integer.parseInt. Получив DataStream, содержащий окончательные результаты, его можно записать его во внешнюю систему, создав соответствующий приемник. Например,
В отличие от DataSet, DataStream поддерживает обработку как ограниченных, так и неограниченных потоков данных. Поэтому для пакетной обработки разработчику необходимо явно задать соответствующий режим выполнения RuntimeExecutionMode.BATCH:
StreamExecutionEnvironment executionEnvironment = // [...]; executionEnvironment.setRuntimeMode(RuntimeExecutionMode.BATCH);
API DataStream использует DataStreamSource для чтения записей из внешней системы, тогда как API DataSet использует DataSource. Аналогичное замечание справедливо и для приемников: API DataStream используется DataStreamSink для записи записей во внешнюю систему, тогда как API DataSet использует DataSink.
Операции над полным DataSet соответствуют глобальному агрегированию окон в DataStream с пользовательским окном, которое запускается в конце входов функции EndOfStreamWindows(). В настоящее время API DataStream напрямую не поддерживает агрегации на неключевых потоках (агрегации в области подзадач). Чтобы сделать это, нужно сначала назначить идентификатор подзадачи записям, а затем превратить поток в ключевой поток с помощью функции AddSubtaskIdMapFunction(). Методы RangePartition() и GroupCombine() вообще не поддерживаются в API DataStream. Читайте в нашей новой статье про разделение результатов выходного потока API DataStream.
Узнайте больше про возможности Apache Flink для пакетной и потоковой аналитики больших данных и машинного обучения на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

