
Продвигая наш новый курс по графовой аналитике больших данных в бизнес-приложениях, сегодня заглянем под капот коннектора Neo4j к Apache Spark. Сценарии использования, принципы работы, поддержка потоковой передачи Spark и другие новинки версии 4.1 для построения эффективных аналитических коннекторов с помощью алгоритмов на графах. Как работает коннектор Neo4j к Apache Spark: краткий обзор Осенью...
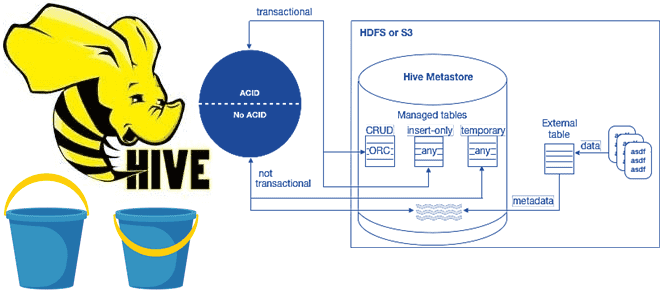
В рамках обучения аналитиков данных и дата-инженеров тонкостям работы с Apache Hive, сегодня разберем особенности ACID-транзакций в этом популярном инструменте класса SQL-on-Hadoop. Зачем и когда нужны ACID-транзакции в Apache Hive, какие параметры нужно настроить для их выполнения, при чем здесь блокировки, каковы ограничения и особенности уплотнения дельта-каталогов. Еще раз про...

Недавно мы писали, что в новой версии Apache Flink 1.14, которая вышла в конце сентября 2021 года, сделаны попытки объединения потоковой и пакетной парадигм обработки данных. Сегодня рассмотрим, как подобное стремление к унификации реализуется на практике дата-инженерами фотохостинга Pinterest, которые используют Apache Flink как универсальный инструмент аналитики больших данных в...

Apache AVRO не случайно считается очень востребованным форматом и популярной системой сериализации данных, который активно в Kafka. Сегодня рассмотрим, как сериализуются данные в AVRO, каким образом это связано со структурами JSON и при чем здесь реестр схем Confluent. Еще раз про AVRO и сериализацию данных Apache Kafka часто используется в...
В этой статье для дата-аналитиков и разработчиков распределенных приложений рассмотрим несколько распространенных ошибок, которые можно сделать в PySpark-коде. Когда PySpark-код на DataFrame DSL лучше запросов Spark SQL, как изящно решить проблему длинных строк, почему пользоваться функцией cache() надо осторожно, а также откуда появляются NULL-значения при внешних соединениях потоковых таблиц. Spark...
Чтобы сделать наши курсы для дата-инженеров еще более полезными, сегодня рассмотрим, как объединить Apache NiFi и Airflow в рамках одного ETL-конвейера обработки данных. Читайте далее, зачем совмещать эти технологии и как сделать это наиболее эффективно, обращаясь к конечным точкам REST API процессоров NiFi из задач DAG-графа AirFlow. Apache Airflow +...

В рамках продвижения нашего нового курса по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим пример анализа данных о путешествиях средствами графовой СУБД Neo4j и ее языка запросов Cypher. Читайте далее, где взять данные о путешествиях цифровых кочевников и как определить самое популярное направление. Цифровые кочевники и графы их путешествий Хотя...

В октябре 2021 года российская компания «Аренадата Софтвер» выпустила новый продукт для аналитики больших данных под брендом Arenadata. Что такое Arenadata LogSearch (ADLS), при чем здесь Elasticsearch и какие потребности закрывает эта корпоративная адаптация open-source технологии полнотекстового поиска от отечественных разработчиков. Elasticsearch, OpenSearch и Arenadata LogSearch: близнецы или тройняшки? Среди...

Сегодня разберем кейс платформы онлайн-обучения Udemy по разработке собственной системы потоковой аналитики больших данных о событиях пользовательского поведения на Apache Kafka, Hive и сервисах Amazon. Про требования к инфраструктуре отслеживания событий и их реализацию с помощью Apache Kafka, Hive, Kubernetes, AWS S3 и EMR, а также чем AVRO лучше Protobuf....

В начале сентября 2021 года вышел 3-й релиз языка программирования Scala, который разработчики называют полностью переработанным из-за модернизации системы типов и добавления новых функций. Текущая версия Apache Spark 3.2.0, выпущенная месяцем позже, поддерживает Scala 2.13 и 3.0 с ограничением некоторых возможностей. Читайте далее, как разработчикам распределенных Spark-приложений писать задания на...