Добавляя в наши курсы по Apache Kafka еще больше полезных кейсов, сегодня рассмотрим пример интеграции этой распределенной платформы потоковой передачи событий с масштабируемой key-value СУБД GridDB через JDBC-коннекторы Kafka Connect. Apache Kafka как источник данных: source-коннектор JDBC Apache Kafka часто используется в качестве источника или приемника данных для аналитической обработки...

В прошлый раз мы говорили о способе взаимодействия задач между собой в Apache Airflow. Сегодня поговорим о таких сущностях, как соединение (connections) и хуки (hooks). Читайте в этой статье: что такое хук и соединение, как создать и скачать соединение, а также как подключить базу данных в Airflow. Что такое связи...

29 сентября 2021 года вышла новая версия популярного Big Data фреймворка Apache Flink. Мы сделали краткий обзор главных улучшений свежего релиза 1.14 общедоступного дистрибутива, а также его коммерциализации в Ververica Platform 2.6. Узнайте, как потоковая обработка и аналитики больших данных с Apache Flink станет еще проще и эффективнее. Исправление ошибок...

Сегодня рассмотрим, как Uber эффективно обрабатывает миллионы запросов на поездки c помощью технологий надежного хранения и быстрой аналитики больших данных. Вас ждет краткий ликбез по системе геопространственной индексации H3 и рассказ о том, почему компания заменила NoSQL-Cassandra c компонентом Saga интеграционного фреймворка Camel на геораспределенную облачную NewSQL-СУБД Spanner от Google....
Чтобы добавить в наши курсы для дата-инженеров еще больше полезных примеров, сегодня рассмотрим, как построить конвейер преобразования CSV-файлов и загрузить данные в масштабируемую NoSQL-СУБД GridDB с помощью Apache NiFi. Краткий ликбез по GridDB и Apache NiFi в кейсе построения ML-системы для анализа данных временных рядов. Анализ данных временных рядов c...
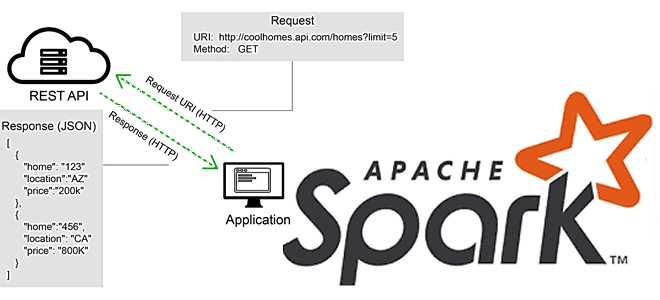
В этой статье для разработчиков Apache Spark разберем, что не так с вызовами REST API в этом фреймворке, и как решить эту проблему с помощью готовых библиотек или создания собственных UDF-функций на PySpark и не только. Для наглядности рассмотрим практический пример вызова REST API на PySpark с библиотекой Rest Data...

Постоянно обновляя наши курсы по Apache Kafka, сегодня рассмотрим еще один полезный инструмент для администраторов, дата-инженеров и разработчиков, который повышает эффективность взаимодействия с этой распределенной платформой потоковой обработки событий. Что такое Saamsa, какие проблемы Kafka она решает и как ее использовать на практике. 5 вопросов разработчика и дата-инженера к Apache...
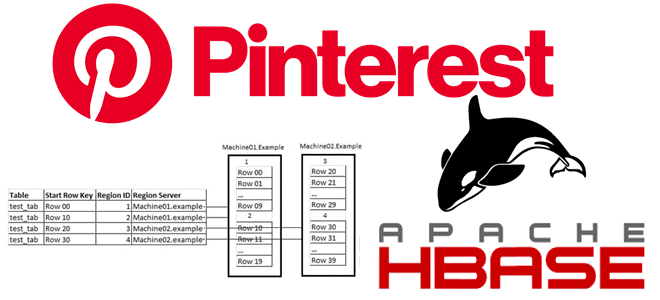
Обучая дата-инженеров и разработчиков распределенных приложений для аналитики больших данных, сегодня рассмотрим кейс компании Pinterest по построению масштабируемого решения для индексации записей в Apache HBase. Чем хранилище Ixia отличается от Lily HBase Indexer, зачем понадобился собственный аналог Solr и ElasticSearch, а также как все это работает в реальном времени с...

Рассмотрим пока еще фантастический пример из ближайшего будущего, где вся информация структурирована в виде графа знаний, доступ к сегментам которого определяется принадлежностью человека или машины к конкретной партии или корпорации. Как построить справочник организаций с помощью ИИ и графовой аналитики больших данных. Постановка задачи: построение справочника организаций Систематизация и упорядочивание...

Продвигая наш новый курс по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим работу Data Science исследователей из Пизанского университета и сотрудников крупного ритейлера H&M по анализу данных торгового ассортимента компании с помощью ML-моделей на графах. Читайте далее, как машинное обучение на графовых нейросетях автоматизирует подбор сочетаемых предметов одежды и...