 1071
1071 
Содержание
Продвигая наш новый курс по графовой аналитике больших данных в бизнес-приложениях, сегодня заглянем под капот коннектора Neo4j к Apache Spark. Сценарии использования, принципы работы, поддержка потоковой передачи Spark и другие новинки версии 4.1 для построения эффективных аналитических коннекторов с помощью алгоритмов на графах.
Как работает коннектор Neo4j к Apache Spark: краткий обзор
Осенью 2021 года Neo4j выпустил новую версию коннектора к Apache Spark, основными новинками которой стала доступность потоковой передачи Spark, как источника, так и приемника. Этот коннектор работает с Neo4j 3.5 и всей серией 4+, независимо от того, запускается ли он как отдельный экземпляр, в режиме кластера или как управляемая служба в облачном решении AuraDB. Neo4j Connector для Apache Spark версии 4.1 поддерживает Spark 2.4.5+ с Scala 2.11 и Scala 2.12 и Spark 3.0+ с Scala 2.12. В зависимости от комбинации версий Spark и Scala могут понадобиться разные файлы JAR-пакетов, которые имеют вид neo4j-connector-apache-spark _ $ {scala.version} _ $ {spark.version} _ $ {connector.version}.
Коннектор позволяет создавать или потреблять данные в Neo4j AuraDB и из него с любым источником, совместимым с Apache Spark. Коннектор Neo4j для Apache Spark упрощает интеграцию графов со Spark, позволяя считывать любой набор узлов или отношений как датафрейм в Spark или, наоборот, записывать любой DataFrame в Neo4j как набор узлов или отношений. Можно также использовать операторы языка запросов Cypher для обработки записей в датафрейм в выбранном пользователем шаблоне графа.
Примечательно, что этот коннектор не основан на Cypher для Apache Spark/Morpheus, предусматривающий предоставление интерпретатора, выполняющий запросы Cypher в среде Spark. Коннектор предоставляет собственное графовое представление для Spark и выполняет роль средства интеграции между Neo4j и Spark, фокусируясь на чтении и записи. Через этот коннектор весь код Cypher выполняется строго внутри Neo4j, а среда Spark работает как обычно, с датафреймами, причем коннектор не предоставляет примитивы графового API для Spark.
Поскольку коннектор основан на новом Spark DataSource API, другие интерпретаторы для Python и R, также будут работать: API остается прежним, потребуются лишь незначительные изменения синтаксиса, чтобы учесть различия между Python и Scala.
Изначально коннектор Spark записывал данные в Neo4j пакетами. Поскольку Neo4j является транзакционной СУБД, все изменения производятся внутри транзакции, которые имеют накладные расходы. Уменьшить эти накладные расходы и повысить производительность можно следующими способами:
- увеличить размер пакета (size) — чем больше пакет, тем меньше транзакций выполняется для записи всех данных и тем меньше накладных расходов на транзакции;
- установить в экземпляре Neo4j достаточный размер свободной кучи и кэша страниц, т.к. недостаток памяти не позволят зафиксировать большие пакеты, замедляя импорт.
Ранее коннектор Neo4j для Apache Spark позволял выполняться пакетную загрузку и перемещение данных из таких систем, как BigQuery, Snowflake, Azure Synapse и других в графы этой NoSQL-СУБД. Коннектор позволяет проектировать конвейеры графовой аналитики больших данных для многих вариантов использования. Однако, пакетные операции не работают с другими источниками потоковой передачи, такими как AWS Kinesis, Google Pubsub, Apache Kafka, Flume и пр. Поэтому в новой версии поддерживается потоковая передача Spark, которая пригодится для множества бизнес-сценариев. О них мы поговорим далее.
Поддержка потоковой передачи Spark в новой версии
Двунаправленная потоковая передача с помощью Spark актуальна для следующих бизнес-сценариев:
- потоковый ETL, когда необходимо непрерывно собирать данные, очищать, агрегировать их и помещать в граф знаний Neo4j, чтобы обнаружить аномальное поведение почти в реальном времени;
- обогащение данных – потоковая передача Spark может обогатить живые данные и связать их с другими статическими датасетами, добавляя нужные значения к графу с помощью Cypher;
- обнаружение триггерных событий – Spark Streaming позволяет быстро обнаруживать редкие или необычные («триггерные») события, которые могут указывать на потенциально серьезную проблему, и быстро реагировать на них. Например, банки используют триггеры для обнаружения мошеннических транзакций и предотвращения их, а в производстве часто приходится отправлять автоматические предупреждения, чтобы предотвратить поломки оборудования. Подробнее о применении графовых алгоритмах в бизнес-приложениях мы писали здесь.
- машинное обучение — для ML-процессов, реализованных в Spark, потоковая передача изменений данных из графа знаний поможет в развертывании моделей онлайн-прогнозирования.
Поскольку потоковая передача работает в обоих направлениях, можно использовать поддержку Spark Streaming, чтобы добавить возможности графа в любой поток потоковых данных. Достаточно передать данные в Neo4j, обогатить их или преобразовать с помощью Cypher и других подходов, а затем быстро передать в нужное место назначения.
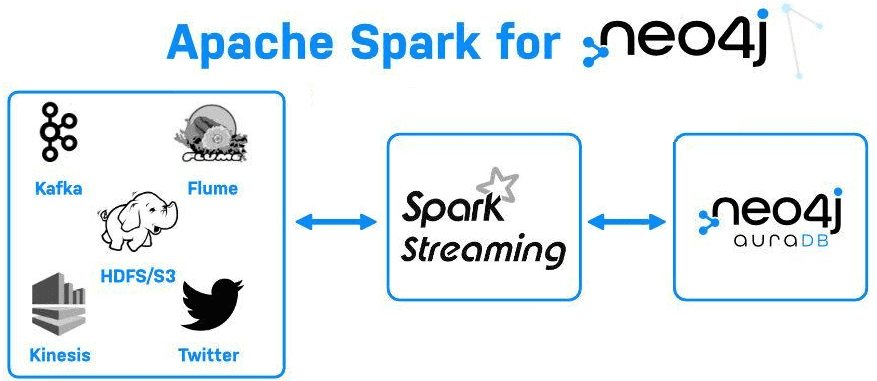
Коннектор просто повторно использует API Spark Streaming, рассматривая Neo4j как источник потоковой передачи. При наличии опыта работы с коннектором чтения/записи данных из/в Neo4j с помощью пакетного API, разработчик может использовать функции Apache Spark Structured Streaming, добавив несколько дополнительных параметров, например, указав момент считывания потока.
Например, следующий код на Scala показывает чтение данных о событиях пользовательского поведения из Neo4j и их запись в Spark датафрейм. Сперва создается поток, к которому запускается запрос, а результат его выполнения записывается во временную таблицу в памяти под названием «testReadStream». Далее идет запрос к этой таблице, чтобы увидеть, какие данные возвращаются.
graph_stream = (
spark.readStream
.format(«org.neo4j.spark.DataSource»)
.option(«authentication.type», «basic»)
.option(«url», url)
.option(«authentication.basic.username», user)
.option(«authentication.basic.password», password)
.option(«streaming.property.name», «lastUpdated»)
.option(«streaming.from», «ALL»)
.option(«labels», «Person»)
.load()
)
query = (graph_stream.writeStream
.format(«memory»)
.queryName(«testReadStream»)
.start())
spark.sql(«select * from testReadStream»).show(1000, False)
А запись потока данных о событиях пользовательского поведения из AWS Kinesis в Neo4j с помощью Apache Spark Structured Streaming следующим Scala-кодом:
val kinesisQuery = kinesisStream
.writeStream
.format(«org.neo4j.spark.DataSource»)
// Neo4j Aura connection options
.option(«url», «neo4j+s://abcd.databases.neo4j.io»)
.option(«authentication.type», «basic»)
.option(«authentication.basic.username», «neo4j»)
.option(«authentication.basic.password», «password»)
.option(«checkpointLocation», «/tmp/kinesis2Neo4jCheckpoint»)
// end connection options
.option(«save.mode», «Append»)
.option(«relationship», «CHECKED_IN»)
.option(«relationship.save.strategy», «keys»)
.option(«relationship.properties», «user_checkin_time:at»)
.option(«relationship.source.labels», «:Attendee»)
.option(«relationship.source.save.mode», «Overwrite»)
.option(«relationship.source.node.keys», «user_name:name»)
.option(«relationship.target.labels», «:Event»)
.option(«relationship.target.save.mode», «Overwrite»)
.option(«relationship.target.node.keys», «event_name:name»)
.start()
Завтра мы продолжим разговор про интеграции этой NoSQL-СУБД с другими системами и рассмотрим, как связать ее с Apache Kafka. А о том, как разработчики Cypher хотели внедрить его в Spark, но так и не реализовали эту идею до конца, читайте в нашей новой статье.
Еще больше интересных примеров графовой аналитики больших данных в бизнес-приложениях вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков больших данных в Москве:
Источники

