В этой статье для дата-аналитиков и разработчиков распределенных приложений рассмотрим несколько распространенных ошибок, которые можно сделать в PySpark-коде. Когда PySpark-код на DataFrame DSL лучше запросов Spark SQL, как изящно решить проблему длинных строк, почему пользоваться функцией cache() надо осторожно, а также откуда появляются NULL-значения при внешних соединениях потоковых таблиц.
Spark SQL vs Dataframe DSL
PySpark позволяет создать запрос к датафрейму с помощью Spark SQL или DSL-язка этого фреймворка. Например, создадим представление из датафрейма, определим SQL-запрос как строку и выполним ее средствами Spark SQL:
sdf.gud.createOrReplaceTempView(‘sdf_view’)
sql_string = “select * from sdf_view”
result_df = spark.sql(sqlQuery = sql_string)
С Dataframe DSL можно запрашивать данные без создания представлений, аналогично работе с библиотекой Pandas, которой пользуется каждый Data Scientist в Jupiter Notebook или Google Colab.
result = sdf.select(“colomn1″,”column2”)
Однако, если требуется создать функцию, которая будет принимать список пар параметров для динамического запроса данных, количество строк условий в предложении where будет расти, т.к. логическое выражение не определено до тех пор, пока не будут переданы реальные параметры. В частности, на Spark SQL для динамической фильтрации, следует сперва создать шаблон:
sql_string = “””
select * from sdf_view
where 1 = 1
<sub_conditions>
“””
Вместо под-условий (<sub_conditions>) можно использовать цикл Python на основе входных параметров, таких как объект словаря:
for k,v in input_dict.items():
sql_string = sql_string + \
” and array_contains(array_column,'”+k+”:”+v+”‘)”
Например, если входной параметр является набор пар ключ-значение типа следующего:
{
“tag_key1″:”tag_val1″,
“tag_key2″:”tag_val2″
}
Шаблон Spark SQL будет выглядеть так:
select * from sdf_view
where 1 = 1
and array_contains(array_column,’tag_key1:tag_val1′)
and array_contains(array_column,’tag_key2:tag_val2′)
Однако, в реальной жизни по мере разрастания кода он становится нечитабельным, поскольку замена и конкатенация строк превращают его в хаос, который сложно отлаживать и поддерживать. В Dataframe DSL аналогичный код будет выглядеть намного понятнее и лаконичнее [1]:
from pyspark.sql import functions as F
temp_sdf = sdf.select(“col1″,”col2”)
for k,v in input_dict.items):
temp_p = k+”:”+”v”
temp_sdf = temp_sdf\
.where(F.array_contains(temp_sdf.array_column,temp_p))
Изящное решение проблемы длинных строк для PySpark
При работе с DataFrame код запроса часто пишется в одной длинной строке, например,
spark_df=sdf.select(“Date”.filter((rec[“Date”]>=date_day)&(rec[“Date”]<run_date)).distinct().orderBy([“UsageDate”],ascending=[1])
Это не очень понятно, поэтому рекомендуется разбивать подобные длинные инструкции на несколько строк. Это можно сделать с помощью \, что приведет код к следующему виду:
spark_df =sdf.select(“Date”)\
.filter((rec[“Date”]>=date_day) & (rec[“Date”]<run_date))\
.distinct().orderBy([“UsageDate”],ascending=[1])\
.limit(1000)
Обратный слеш решает проблему длинных строк, но не слишком прибавляет коду красоты и ясности. Вместо обратной косой черты лучше использовать символы (…), и код уже будет выглядеть в питоническом стиле [1]:
result_df = (
spark_df.select(‘col1′,’col2’)
.groupBy(…)
.withColumn(…)
.where(…)
.select(…)
)
Напомним, официальная документация по лексике Python 3.1 отмечает, что выражения в круглых скобках, квадратных скобках или фигурных скобках можно разделить на более чем одну физическую строку без использования обратного слеша. При этом неявно продолженные строки могут содержать комментарии, а отступ линий продолжения не важен. Допускаются пустые строки продолжения. Между неявными строками продолжения нет токена NEWLINE [2].
Снова про cache() и persist()
API DataFrame в Apache Spark предоставляет 2 функции для кэширования данных, т.е. временного сохранения датафреймов для ускоренного доступа к ним: cache() и persist(). Они различаются уровнем хранения: persist() может принимать необязательный аргумент storageLevel, с помощью можно указать, где именно данные будут сохраняться: в памяти, на диске или в обоих местах. По умолчанию значение storageLevel для обеих функций – MEMORY_AND_DISK, т.е. данные будут храниться в памяти, если там есть для них есть место. Иначе данные будут сохранены на диске.
Однако, из-за того, что cache() хранит данные в памяти, могут возникнуть ошибки по причине ее нехватки. Например, если результирующий набор данных больше, чем размер доступной памяти, функция cache() не сможет кэшировать их. Поэтому перед тем, как пользоваться методами кэширования, следует учесть размер данных и объем доступных ресурсов, чтобы в попытке оптимизации не снизить производительность Spark-приложения [1]. Подробнее про лучшие практики кэширования в Apache Spark мы писали здесь.
Тонкости Outer Join: внешнее соединение потоков в Spark SQL
Когда нужно обогатить данные, например, о пользовательском поведении, можно написать UDF для вызова внешнего API на основе уникального идентификатора пользователя для извлечения данных или их подготовки в виде таблицы для JOIN-соединения. В втором случае есть два варианта:
- сделать статическую таблицу, которая предварительно вычисляется и загружается при запуске приложения. Однако, если потребуется добавить в эту таблицу новые данные, задание придется перезапускать, т.к. Apache Spark автоматически кэширует датафреймы, которые используются более двух раз.
- сделать потоковую таблицу и маркировать новые записи водяными знаками, чтобы Spark выбирал их из потока. Соединения потоковых таблиц с помощью JOIN почти аналогичны обычным таблицам, но в случае внешнего соединения результаты могут удивить.
Например, некоторые записи будут отсутствовать там, где ожидались NULL-значения. Например, есть левая таблица A с ключами 1, 2, 3, 4, 5 и 6, и правая таблица B- с ключами 1, 2 и 3, с корректными водяными знаками и метками времени [3].
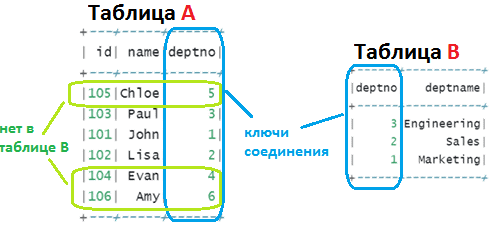
Из-за отсутствия ключей 4, 5 и 6 в правой таблице в результате SQL-запроса
SELECT id, name, A.deptno, deptname
FROM A LEFT JOIN B ON A.deptno = B.deptno;
ожидается следующий результат с NULL-значениями в некоторых строках [4]:
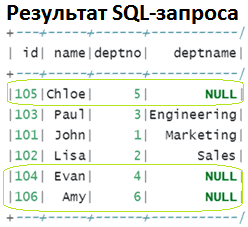
Однако, в случае потоковых таблиц эти строки с NULL-значениями не будут видны до тех пор, пока не появится один или несколько микропакетов, т.к. Spark Streaming работает с данными в микропакетном режиме и будет ждать как можно дольше до достижения временного порога передачи этой строки следующему потоку. Это затрудняет тестирование Spark-приложения, т.к. в ожидании левого соединения нужно создать несколько микропакетов данных [3]. О том, какие механизмы использует Apache Spark для выполнения операций соединения, мы писали в этой статье.
Больше подробностей эксплуатации Apache Spark для разработки распределенных приложений и аналитики больших данных вам помогут узнать специализированные курсы в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источники
- https://medium.com/codex/three-mistakes-i-made-with-pyspark-ea5d0077aeb4
- https://docs.python.org/3/reference/lexical_analysis.html#implicit-line-joining
- https://medium.com/swlh/demystifying-sparks-stream-stream-outer-join-8fcbcd4a9e59
- https://spark.apache.org/docs/latest/sql-ref-syntax-qry-select-join.html

