
Почему потоковый сервер Greenplum выгружает данные во внешние системы пакетно: тонкости утилиты gpfdist и YAML-файла конфигурации выгрузки. Возможности и ограничения GPSS-сервера при выгрузке данных во внешние системы из MPP-СУБД. Потоковый сервер Greenplum Ключевым отличием Greenplum от PostgreSQL является поддержка механизма массово-параллельной обработки, благодаря чему эта MPP-СУБД относится к стеку Big...
Как изменить приоритет задачи в очереди исполнителя Apache AirFlow, на что влияет метод определения весов, каким образом можно балансировать нагрузку с помощью пулов и зачем настраивать количество слотов. Как приоритизировать задачи в очереди Apache AirFlow Дата-инженеры, которые используют Apache AirFlow для оркестрации пакетных процессов, знают, что задачи скапливаются в очереди...
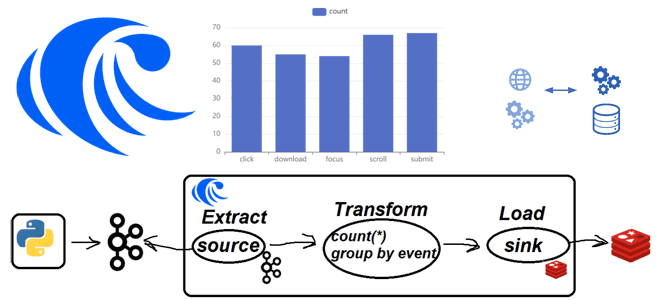
Практическая демонстрация потоковой агрегации событий пользовательского поведений из Apache Kafka с записью результатов в Redis на платформе RisingWave: примеры Python-кода и конвейера из SQL-инструкций. Постановка задачи Одной из ярких тенденций в современном стеке Big Data сегодня стали платформы данных, которые позволяют интегрировать разные системы между собой, поддерживая как пакетную, так...
Архитектура Data Lake: что не так с потоковыми обновлениями данных в Data Lake, как Apache Iceberg реализует эти операции и почему Upsolver решили улучшить этот формат Проблема потоковых обновлений в Data Lake и 2 подхода к ее решению Считается, что озеро данных (Data Lake) предлагают доступное и гибкое хранилище, позволяющее...
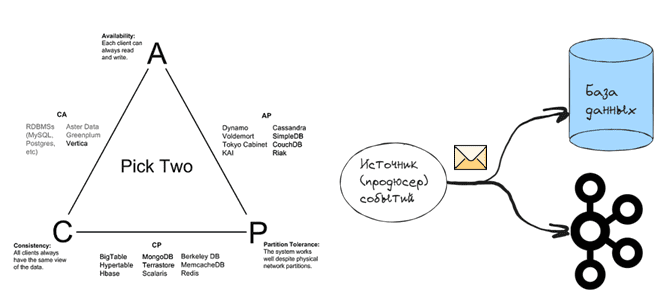
Проклятье CAP-теоремы: проблема целостности данных в распределенной системе и варианты ее решения. 3 шаблона проектирования микросервисной EDA-архитектуры на Apache Kafka: transactional outbox, Event Sourcing и listen to yourself. Что такое проблема двойной записи в распределенных гетерогенных системах Согласно CAP-теореме, распределенная система в любой момент времени обеспечивает выполнение только 2-х требований...
Что такое задачи отчетности, зачем они нужны и как с их помощью отслеживать события и системные метрики экземпляра NiFi-приложения, а также JVM. Обзор Reporting Tasks в Apache NiFi 2.0. Задачи отчетности в Apache NiFi Чтобы отслеживать события и метрики работающего экземпляра приложения Apache NiFi, этот фреймворк предоставляет специализированные инструменты, которые...
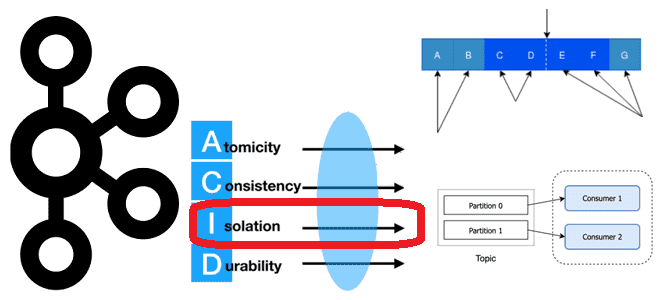
Как Apache Kafka реализует требование к изоляции потребления сообщений, опубликованных транзакционно, и где это настроить в клиентских API, зачем отслеживать LSO, для чего прерывать транзакцию, и какими методами это обеспечивается в библиотеке confluent_kafka. Транзакционое потребление: изоляция чтения сообщений в Apache Kafka При том, что Apache Kafka не является базой данных,...
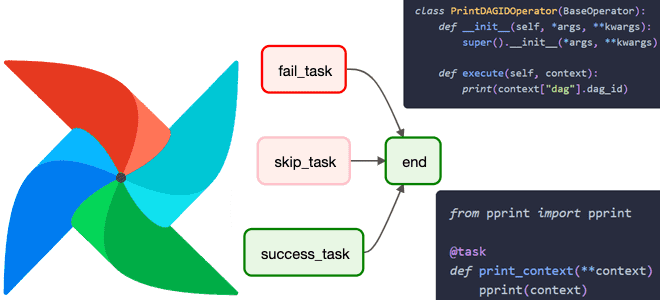
Для чего нужен контекст задачи Apache AirFlow, что он собой представляет, какие включает объекты, как получить к ним доступ и чем они полезны дата-инженеру. Что такое контекст задачи Apache AirFlow В разработке ПО контекстом называется среда, в которой существует объект. Это понятие очень важно при использовании специализированных фреймворков. Например, в...

Для чего смотреть планы выполнения запросов при работе с API pandas в Spark и как это сделать: примеры использования метода spark.explain() и его аргументов для вывода логических и физических планов. Разбираем на примере PySpark-скрипта. API pandas и физический план выполнения запроса в Apache Spark Мы уже писали, что PySpark, API-интерфейс...
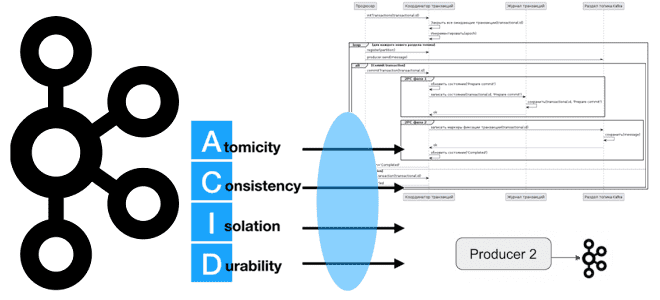
Как Apache Kafka реализует требование к атомарности транзакций с помощью координатора и журнала транзакций: принцип Atomic в ACID и его иллюстрация на UML-диаграмме последовательности публикации сообщений в раздел топика. Транзакционная публикация сообщений в Apache Kafka Хотя Apache Kafka не является базой данных, эта платформа потоковой передачи событий все же хранит...