
Новая логика дедупликации данных, ограничения работы с матпредставлениями, дополнительные SQL-функции и улучшения производительности ClickHouse 24.7: краткий обзор ключевых особенностей июльского выпуска. Несовместимые изменения и новые фичи 30 июля 2024 года вышел очередной релиз ClickHouse, в котором довольно много изменений, несовместимых с прошлыми версиями. В частности, в реплицированных базах данных теперь...
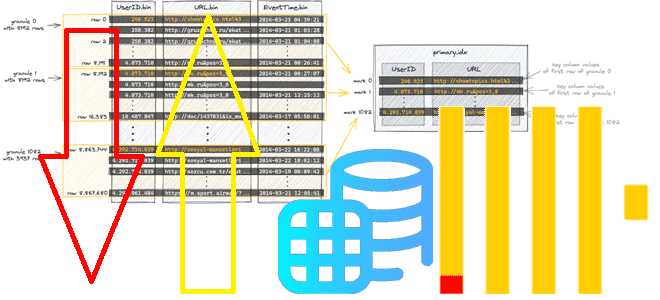
Зачем в ClickHouse 24.6 добавлена настройка optimize_row_order для оптимизации порядка строк MergeTree-таблиц, как она работает и где ее применять. Как связаны индексация и сортировка таблиц в ClickHouse Даже не будучи классической реляционной СУБД, ClickHouse поддерживает индексацию, насколько это возможно в его колоночной природе, индексируя первичным ключом целую группу строк (гранулу)...
Что такое rich-функции в Apache Flink, зачем они нужны, чем отличаются от обыкновенных UDF и как с ними работать: простой пример на PyFlink с запуском в Google Colab. Rich-функции в Apache Flink Будучи очень мощным фреймворком для разработки распределенных потоковых приложений, Apache Flink не только предоставляет широкий набор stateful-функций, но...

20 июня 2024 года вышел очередной релиз Greenplum. Разбираемся с ключевыми новинками выпуска 7.2: сканирование индекса в AO-таблицах, изменения в оптимизаторе GPORCA, улучшенная обработка геопространственных данных и новая служба централизованного управления сегментами Postmaster. Новинки Greenplum 7.2 для дата-инженера Начнем с изменений, повышающих производительность Greenplum. Одним из них стало сканирование индекса...
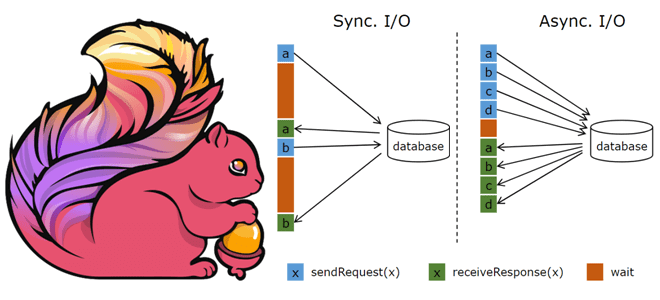
API асинхронного ввода-вывода в Apache Flink и как его использовать для асинхронной интеграции данных из внешней системы с потоком событий. Основы асинхронной обработки в Apache Flink Обогащение потоков данных информацией из внешних систем является довольно сложным кейсом из-за необходимости синхронизировать скорость поступления событий с задержкой доступа к внешнему источнику. При...

Как устроен потоковый запрос Spark Structured Streaming на уровне кода: интерфейсы, их методы и как их настроить, создание и запуск StreamingQuery. Создание потокового запроса в Spark Structured Streaming Хотя структурированная потоковая передача Spark основана на SQL-движке этого фреймворка, в ней гораздо больше сложных абстракций. Например, с точки зрения программирования потоковый...
Почему параллельное выполнение заданий в Apache Spark зависит от языка программирования и как можно обойти однопоточную природу Python в PySpark. Что не так с параллельным выполнением заданий PySpark и как это исправить? Apache Spark позволяет писать распределенные приложения благодаря инструментам для распределения ресурсов между вычислительными процессами. В режиме кластера каждое...
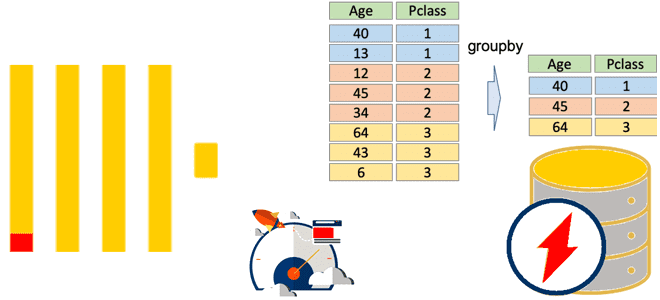
Как работают агрегатные функции в ClickHouse, почему SQL-запросы с GROUP BY потребляют много памяти и что поможет сделать их быстрее и эффективнее: лайфхаки многопоточной агрегации в колоночной базе данных. Особенности выполнения оператора GROUP BY в ClickHouse Агрегатные функции позволяют вычислить экстремум (минимум/максимум), среднее значение, количество, сумму или другое результирующее значение...

Как размер пакета, режим вывода и интервал срабатывания триггера потоковой обработки влияют на скорость вычислений в приложении Apache Spark Structured Streaming и как настроить эти параметры. Размер пакета при потоковой обработке данных в Spark Streaming Хотя скорость обработки данных средствами Apache Spark Streaming зависит от многих факторов, включая саму структуру...
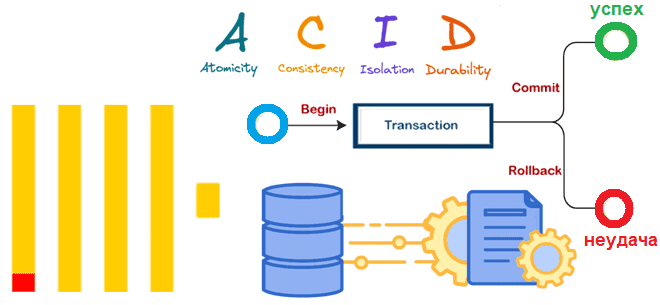
Почему в ClickHouse нет полноценных транзакций, но введена экспериментальная поддержка ACID для операций вставки в таблицы движка MergeTree, как это реализуется и чем синхронная вставка отличается от асинхронной. Особенности операций вставки в ClickHouse В ClickHouse нет полноценных транзакций, поскольку это колоночное хранилище в первую очередь ориентировано на чтение большого объема...