
Как устроен потоковый запрос Spark Structured Streaming на уровне кода: интерфейсы, их методы и как их настроить, создание и запуск StreamingQuery.
Создание потокового запроса в Spark Structured Streaming
Хотя структурированная потоковая передача Spark основана на SQL-движке этого фреймворка, в ней гораздо больше сложных абстракций. Например, с точки зрения программирования потоковый запрос в Structured Streaming – это не просто набор SQL-операторов над таблицей, которая непрерывно дополняется, а абстракция дескриптора потоковых запросов, которые выполняются непрерывно и параллельно в отдельном потоке.
Публичный интерфейс StreamingQuery представляет собой дескриптор запроса, который выполняется непрерывно в фоновом режиме по мере поступления новых данных. Все его методы потокобезопасны, т.е. код функционирует исправно при использовании его из нескольких потоков одновременно, обеспечивая корректный доступ нескольких потоков к разделяемым данным.
StreamingQuery создается при запуске потокового запроса с помощью оператора DataStreamWriter.start, который передает содержимое потокового датафрейма в источник данных. StreamingQuery может быть активным или неактивным, т.е. остановленным, в т.ч. из-за возникшего исключения.
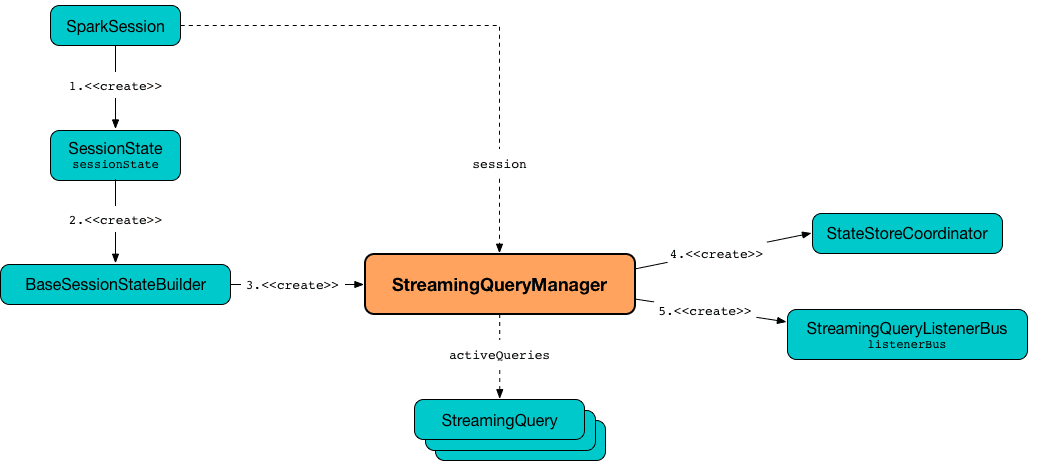
Для управления активными потоковыми запросами используется интерфейс StreamingQueryManager. Он позволяет получить доступ к одному экземпляру StreamingQuery по его идентификатору или всем активным запросам, используя операторы StreamingQueryManager.get или StreamingQueryManager.active соответственно.
При создании потокового запроса метод createQuery() создает StreamingQueryWrapper – сериализуемый интерфейс StreamExecution в соответствии с входными пользовательскими свойствами. StreamingQueryWrapper имеет тот же API, что и StreamExecution и просто передает все вызовы методов базовому StreamExecution.
При этом createQuery() сначала находит имя каталога контрольной точки запроса, т. е. ее местоположение в следующем порядке:
- проверяет точно указанные входные данные userSpecifiedCheckpointLocation, если они определены;
- смотрит значение свойства sql.streaming.checkpointLocation, если оно определено для родительского каталога с подкаталогом по необязательному параметру userSpecifiedName или случайно сгенерированному UUID;
- если свойство useTempCheckpointLocation включено, проверяется временный каталог, заданный в свойстве JVM io.tmpdir с подкаталогом и префиксом temporary. При этом свойство userSpecifiedCheckpointLocation может быть любым путем, приемлемым для путей Hadoop.
Если имя каталога для расположения контрольной точки не найдено, метод createQuery() выводит сообщение об ошибке AnalysisException:
checkpointLocation must be specified either through option("checkpointLocation", ...) or SparkSession.conf.set("spark.sql.streaming.checkpointLocation", ...)
Это означает, что флаг ввода recoverFromCheckpointLocation отключен, но в месте расположения контрольной точки есть каталог смещений. Метод createQuery() обеспечивает анализ логического плана запроса Spark Structured Streaming. Если свойство конфигурации spark.sql.streaming.unsupportedOperationCheck не включено, createQuery() проверяет логический план потокового запроса на наличие неподдерживаемых операций. При обнаружении таких и включенном свойстве spark.sql.adaptive.enabled метод createQuery() запишет в лог предупреждение:
spark.sql.adaptive.enabled is not supported in streaming DataFrames/Datasets and will be disabled.
При успешном парсинге потокового запроса, т.е. отсутствии исключений, createQuery() создает StreamingQueryWrapper с новым микропакетным исполнением (MicroBatchExecution). Для восстановления данных из контрольной точки нужно задать флаг recoverFromCheckpointLocation, который StreamingQueryManager используется для запуска потокового запроса. Он включен по умолчанию. Сигнатура метода создания потокового запроса выглядит так:
createQuery( userSpecifiedName: Option[String], userSpecifiedCheckpointLocation: Option[String], df: DataFrame, extraOptions: Map[String, String], sink: BaseStreamingSink, outputMode: OutputMode, useTempCheckpointLocation: Boolean, recoverFromCheckpointLocation: Boolean, trigger: Trigger, triggerClock: Clock): StreamingQueryWrapper )
Запуск потокового запроса
После создания потокового запроса его нужно запустить, используя метод startQuery(). Этот метод запускает потоковый запрос и возвращает его дескриптор. При этом startQuery() сначала создает StreamingQueryWrapper , регистрирует его идентификатор во внутреннем реестре активных запросов activeQueries, запрашивает его для базового StreamExecution и запускает его. В итоге startQuery возвращает StreamingQueryWrapper, позволяя объединять операторы в цепочку или выдает исключение в случае ошибки.
Сигнатура метода выглядит так:
startQuery( userSpecifiedName: Option[String], userSpecifiedCheckpointLocation: Option[String], df: DataFrame, extraOptions: Map[String, String], sink: BaseStreamingSink, outputMode: OutputMode, useTempCheckpointLocation: Boolean = false, recoverFromCheckpointLocation: Boolean = true, trigger: Trigger = ProcessingTime(0), triggerClock: Clock = new SystemClock()): StreamingQuery )
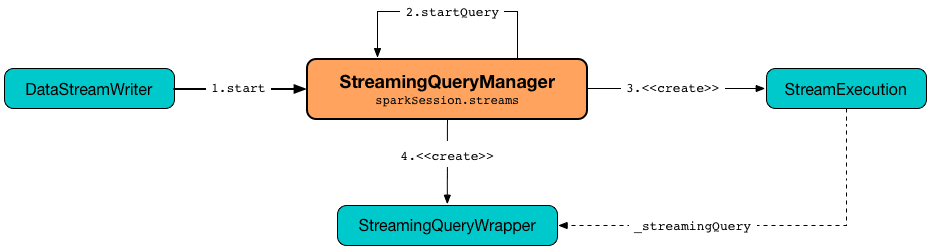
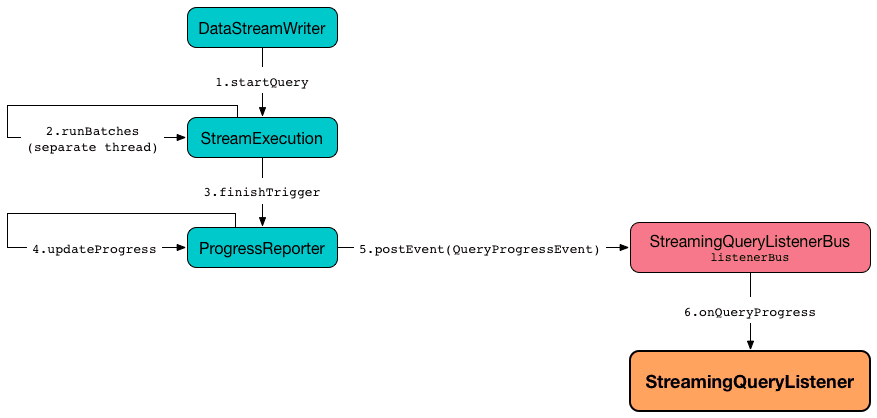
Интерфейс StreamingQueryManager используется для создания StreamingQuery и его исполнения StreamExecution. StreamingQueryManager создается в рамках сеанса, когда создан SessionState. Этот интерфейс уведомляется об изменениях состояния потокового запроса Spark Structured Streaming и передает их далее зарегистрированным слушателям через шину событий StreamingQueryListenerBus. С шиной событий взаимодействует StreamingQueryListener – контракт слушателей, которые хотят получать уведомления о событиях жизненного цикла потоковых запросов, т. е. об их старте, ходе и завершении.
Узнайте больше про использование Apache Spark для разработки приложений аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Потоковая обработка в Apache Spark
- Анализ данных с Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
- Архитектура данных с Apache Spark
Источники

