API асинхронного ввода-вывода в Apache Flink и как его использовать для асинхронной интеграции данных из внешней системы с потоком событий.
Основы асинхронной обработки в Apache Flink
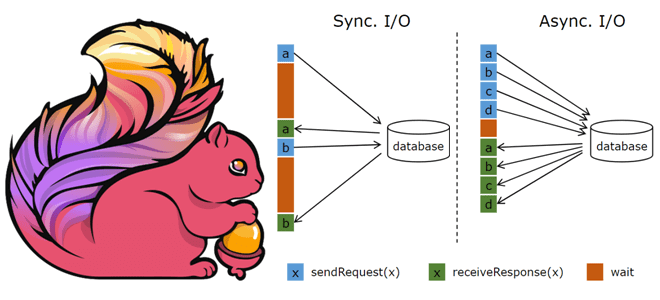
Обогащение потоков данных информацией из внешних систем является довольно сложным кейсом из-за необходимости синхронизировать скорость поступления событий с задержкой доступа к внешнему источнику. При синхронном обращении к внешней системе придется ожидать ответа, который может поступить далеко не сразу. Поэтому в таком случае лучше использовать асинхронное взаимодействие, когда один параллельный экземпляр функции может обрабатывать много запросов одновременно и получать ответы одновременно. Таким образом, вместо ожидания можно отправлять другие запросы и получать ответы. Этот прием повышает пропускную способность потоковой передачи. Однако, реализация асинхронного доступа во внешнюю систему, например, базу данных или хранилище типа key-value требует соответствующего клиента, который поддерживает асинхронные запросы. При его отсутствии придется имитировать асинхронное взаимодействие на синхронном клиенте, создав несколько экземпляров такого и обрабатывая синхронные вызовы от них с помощью пула потоков. Но это не самый простой способ.
В Apache Flink есть API асинхронного ввода-вывода, который позволяет использовать асинхронные клиенты запросов с потоками данных, включая обработку порядка, времени событий, отказоустойчивость и поддержку повторных попыток. Если для внешней системы есть асинхронный клиент, то для асинхронной интеграции ее данных с потоком событий в Apache Flink необходимы следующие компоненты:
- асинхронная функция AsyncFunction, которая отправляет запросы;
- обратный вызов, который принимает результат операции и передает его в публичный интерфейс ResultFuture. В асинхронных и параллельных вычислениях класс Future позволяет выполнять асинхронные операции и получать результаты в будущем, не блокируя основной поток выполнения. Благодаря набору состояний Future можно проверить, завершилась ли операция, получить ее результат или отменить. В Apache Flink ResultFuture собирает результаты или ошибки в пользовательском коде при обработке асинхронного ввода-вывода. Для ResultFuture метод его завершения complete() является идемпотентным: он завершается первым вызовом, а все последующие игнорируются.
- асинхронная операция ввода-вывода к DataStream в качестве преобразования данных.
Для управления асинхронными операциями в Apache Flink используются несколько параметров настройки: тайм-аут, емкость и стратегия повтора. Тайм-аут определяет, сколько времени займет асинхронная операция, прежде чем она будет окончательно считаться неудачной. Тайм-аут может включать несколько повторных запросов, если повтор включен. Этот параметр защищает от мертвых/неудачных запросов.
Емкость определяет, сколько асинхронных запросов может выполняться одновременно, позволяя повысить пропускную способность потоковой обработки. Ограничение количества одновременных запросов гарантирует, что оператор не будет накапливать постоянно растущий список ожидающих запросов, а вызовет обратное давление, чтобы избежать сбоя потоковой передачи или торможения потребителя при превышении лимита емкости.
Стратегия повтора асинхронной операции AsyncRetryStrategy определяет условия, при которых будет запущен ее отложенный повтор, а также стратегию задержки, например, фиксированная, экспоненциальная или заданная пользователем.
Когда асинхронный запрос ввода-вывода истекает по времени, по умолчанию выдается исключение и задание перезапускается. Если нужно обрабатывать тайм-ауты, можно переопределить метод асинхронной функции timeout(), вызвав ResultFuture.complete() или ResultFuture.completeExceptionally(). Это укажет Flink, что обработка этой записи ввода завершена. Когда при тайм-аутах не нужно выдавать никаких записей, можно вызвать метод complete() у интерфейса ResultFuture с пустым списком коллекций: ResultFuture.complete(Collections.emptyList()).
Особенности и ограничения Async API
Одной из сложностей параллельной обработки данных – это неопределенность порядка выполнения конкурентных запросов. Результаты AsyncFunction обычно выдаются в неопределенном порядке, в зависимости от того, какой запрос завершился первым. Чтобы управлять порядком AsyncDataStream, т.е. упорядоченностью выдачи результатов асинхронных операций в Apache Flink, надо выбрать один из двух режимов:
- неупорядоченный unorderedWait(…), когда записи результатов выдаются сразу после завершения асинхронного запроса. Порядок записей в потоке отличается после предыдущего оператора асинхронного ввода-вывода. Этот режим имеет наименьшую задержку и минимальные накладные расходы при использовании времени обработкив качестве базовой временной характеристики.
- упорядоченныйorderedWait(…), когда порядок потока сохраняется. Записи результатов выдаются в том же порядке, в котором запускаются асинхронные запросы, т.е. соответствует порядку ввода записей операторов. Чтобы добиться этого, оператор буферизует запись результата до тех пор, пока не будут выданы все его предыдущие записи или не истечет время ожидания. Это вносит некоторую дополнительную задержку и накладные расходы при контрольной точке, поскольку записи или результаты сохраняются в состоянии контрольной точки в течение более длительного времени по сравнению с неупорядоченным режимом.
Когда потоковое Flink-приложение работает со временем события, водяные знаки будут обрабатываться асинхронным оператором ввода-вывода с учетом режима их упорядоченности. При неупорядоченном режиме водяные знаки не обгоняют записи и наоборот. Это значит, что водяные знаки устанавливают границу порядка. Записи выдаются неупорядоченными только между водяными знаками. Запись, появляющаяся после определенного watermark, будет выдана только после того, как был выдан этот водяной знак. Водяной знак, в свою очередь, будет выдан только после того, как будут выданы все записи результатов из входов до этого водяного знака. Это означает, что при наличии водяных знаков неупорядоченный режим вносит задержки и накладные расходы, аналогичные упорядоченному режиму. Величина этих накладных расходов зависит от частоты водяных знаков.
При упорядоченном режиме порядок водяных знаков и записей сохраняется, как и порядок между записями. Нет существенных изменений в накладных расходах по сравнению с работой со временем обработки. Время загрузки — это особый случай времени события с автоматически генерируемыми водяными знаками, которые основаны на времени обработки источников.
Асинхронный оператор ввода-вывода обеспечивает полную отказоустойчивость строго однократной доставки. Он на лету сохраняет записи для асинхронных запросов в контрольных точках и повторно запускает эти запросы при восстановлении после сбоя.
Поддержка повторных попыток представляет собой встроенный механизм для асинхронного оператора. Стратегия AsyncRetryStrategy содержит определение условия повтора асинхронного предиката AsyncRetryPredicate, интерфейсы для определения того, продолжать ли повтор, и интервал повтора на основе текущего номера попытки. После выполнения условия повтора триггера можно отказаться от повтора, поскольку текущий номер попытки превышает заданный предел, или принудительно завершить повтор в конце задачи. В этом случае система принимает последний результат выполнения или исключение в качестве конечного состояния. При стратегии AsyncRetryPredicate условие повтора может быть вызвано на основе возвращаемого результата или исключения выполнения.
Для реализаций обратных вызовов Futures, которые имеют Executor в Java или ExecutionContext в Scala, лучше использовать DirectExecutor, который позволяет избежать дополнительных накладных расходов на передачу данных между потоками. Обратный вызов обычно передает результат только ResultFuture, который добавляет его в выходной буфер. Из выходного буфера любая, даже тяжеловесная логика, которая включает в себя выпуск записей и взаимодействие с ведением учета контрольных точек, в любом случае происходит в выделенном пуле потоков. DirectExecutor можно получить через org.apache.flink.util.concurrent.Executors.directExecutor() или com.google.common.util.concurrent.MoreExecutors.directExecutor().
В заключение отметим, что AsyncFunction не вызывается многопоточным способом: существует только один экземпляр асинхронной функции, и он вызывается последовательно для каждой записи в соответствующем разделе потока. Если метод asyncInvoke(…) не возвращает быстро и не полагается на обратный вызов клиента, он не приведет к асинхронному вводу-выводу. Например, следующие шаблоны приводят к блокировке функций asyncInvoke(…) и аннулируют асинхронное поведение:
- использование клиента базы данных, вызов метода поиска/запроса которого блокируется до тех пор, пока не будет получен результат;
- блокировка/ожидание объектов типа Future, возвращаемых асинхронным клиентом внутри метода asyncInvoke(…).
AsyncFunction(AsyncWaitOperator) можно использовать в любом месте графа заданий Apache Flink, кроме присоединения к SourceFunction или SourceStreamTask.
Если включена функция повтора, может потребоваться большая емкость очереди. При этом добавление дополнительных единиц емкости в очередь работ может не влиять на пропускную способность в неупорядоченном режиме вывода. А в случае упорядоченного режима ключевым моментом является головной элемент. Чем дольше он остается незавершенным, тем больше задержка обработки, предоставляемая оператором. Поэтому функция повтора может увеличить время незавершенности головного элемента, если на самом деле получено больше повторных попыток с тем же ограничением времени ожидания. Когда емкость очереди растет, что является обычным способом ослабить обратное давление, увеличивается риск нехватки памяти. Поэтому рекомендуется увеличивать параллелизм задач Apache Flink вместо повышения емкости асинхронных операций. Читайте в нашей новой статье про асинхронные операторы в Apache AirFlow.
Научитесь использовать Apache Flink для потоковой обработки событий в распределенных приложениях аналитики больших данных и машинного обучения на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://nightlies.apache.org/flink/flink-docs-release-1.19/docs/dev/datastream/operators/asyncio/
- https://www.waitingforcode.com/apache-flink/data-enrichment-strategies-apache-flink/read

