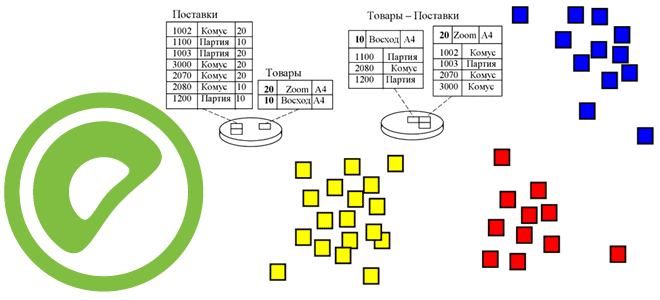
Что означает кластеризация таблиц в PostgreSQL, как это связано с индексацией и очисткой данных, чем полезно применение команды CLUSTER для AO/CO-таблиц в Greenplum 7, а также какой SQL-запрос поможет найти все кластеризованные таблицы в текущей базе данных. Как работает кластеризация таблиц в PostgreSQL Будучи основанной на объектно-реляционной базе данных PostgreSQL,...

Чем задание в Spark-приложениях отличается от задачи, зачем нужны этапы и при чем здесь драйверы с исполнителями. Разбираемся с основами разработки в самом популярном движке для распределенных вычислений: ликбез для дата-инженеров. Основные концепции Spark-приложений Приложение Spark — это программа, созданная с помощью Spark API и работающая в совместимом с этим...

Политики хранения, сжатия и очистки данных в топиках Apache Kafka: какие конфигурации нужно настроить, чтобы работать с файлами распределенных логов наиболее эффективно. Ликбез для администратора кластера Kafka и дата-инженера. Хранение данных в Apache Kafka Мы уже писали, что топик в Apache Kafka представляет собой не физическое, а логическое хранение данных....
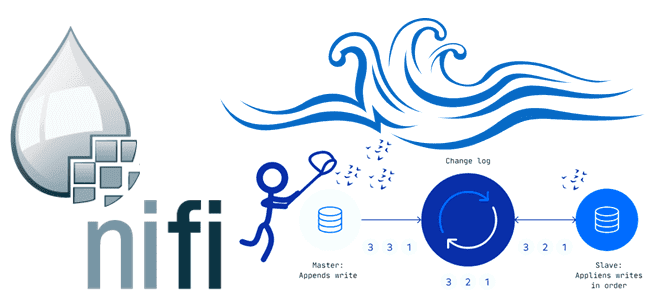
В этой статье для обучения дата-инженеров рассмотрим, как организовать сбор измененных данных из реляционных СУБД, построив CDC-конвейер с помощью Apache NiFi. А также разберем, зачем процессоры этого потокового ETL-маршрутизатора используют технологию веб-хуков. ETL-конвейер для DWH и Data Lake В общем случае сбор данных из реляционных и нереляционных источников и построение...

Интерактивные блокноты Jupyter стали фактически стандартом де-факто для Data Scientist’ов, использующих Python. Многие дата-инженеры и разработчики Spark тоже используют этот легковесный, но очень удобный инструмент. Однако, чтобы применять его для промышленной разработки Big Data приложений, нужно подключить сервер Jupyter к кластеру Spark. Читайте, как это сделать, если кластер Apache Spark...
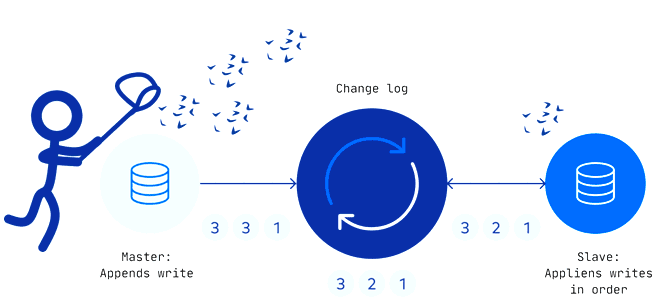
Захват измененных данных считается довольно известным паттерном организации ETL-процессов для корпоративных хранилищ и озер данных. Как реализуется CDC-технология, по каким шаблонам, что их ограничивает и чем опасен дрейф изменений в Change Data Capture. Паттерны и принципы реализации захвата измененных данных Эффективность эксплуатации озера данных зависит от ETL-процессов, поскольку объемы данных...

В этой статье рассмотрим настройку инфраструктуры Kubernetes для потоковой платформы комплексных мобильных приложений на основе Apache Kafka. Что поможет добиться оптимальной масштабируемости приложений-потребителей и высокой доступности всей Big Data системы. Проблемы масштабирования платформы Grab из приложений-потребителей Apache Kafka Grab считается ведущей платформой суперприложений в 8 странах Юго-Восточной Азии, которая предоставляет...
Мы уже писали о важности резервного копирования данных в Apache HBase на примере ИТ-компании Clairvoyant. Сегодня рассмотрим опыт индийской компании Myntra, которая предложила простую методику создания инкрементных бэкапов для Apache HBase 2.1.4 и Hadoop 2.7.3, а также восстановления нужных данных из этих резервных копий в BLOB-хранилищах по требованию пользователя. 5...

Что такое SQL-оператор VACUUM, зачем эта команда нужна в Greenplum и как она работает. Разбираемся с таблицами системного каталога и тонкостями ускорения SQL-запросов в самой популярной MPP-СУБД. Что такое сборка мусора в Greenplum и PostgreSQL Напомним, в объектно-реляционной базе данных PostgreSQL, на которой основана MPP-СУБД Greenplum, о чем мы писали...
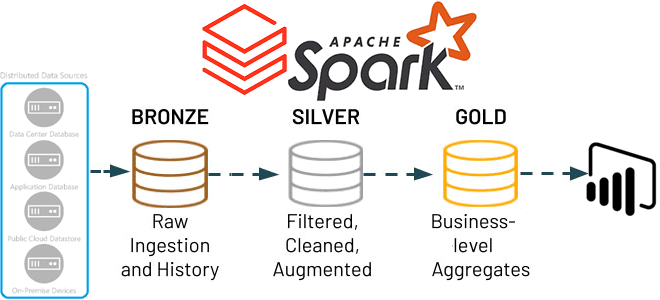
В этой статье для обучения дата-инженеров и ИТ-архитекторов рассмотрим, как Apache Spark Structured Streaming помогает реализовать самообслуживаемый сервис потоковой передачи данных в Delta Lake. А также вспомним каноническую 3-хслойную модель этого уровня хранения от Databricks. Много потоковых сценариев в одном приложении Apache Spark Structured Streaming Мы недавно писали, что архитектуры,...