
Интерактивные блокноты Jupyter стали фактически стандартом де-факто для Data Scientist’ов, использующих Python. Многие дата-инженеры и разработчики Spark тоже используют этот легковесный, но очень удобный инструмент. Однако, чтобы применять его для промышленной разработки Big Data приложений, нужно подключить сервер Jupyter к кластеру Spark. Читайте, как это сделать, если кластер Apache Spark работает под управлением Hadoop YARN и защищен протоколом Kerberos.
Как подключить Jupyter к кластеру Spark
Можно выделить несколько способов подключения интерактивных блокнотов Jupyter к защищенному кластеру Spark на Hadoop YARN:
- написать скрипт с интерпретатором PySpark для запуска экземпляра Jupyter;
- использовать библиотеку Sparkmagic;
- использовать проект Lighter на основе REST API Livy.
Первый способ требует доступ к узлу кластера Spark, а также наличие среды (Conda, Mamba, virtualenv и пр.) с пакетом jupyter. Надо написать скрипт в каталоге /home, который определяет драйвер IPython, сокет серверного приложения, т.е. IP-адрес и порт, а также конфигурацию Spark:
pyspark \ --master yarn \ --conf spark.shuffle.service.enabled=true \ --conf spark.dynamicAllocation.enabled=false \ --driver-cores 2 --driver-memory 11136m \ --executor-cores 3 --executor-memory 7424m --num-executors 10
Запуск этого скрипта создает сервер Jupyter, который можно использовать для разработки заданий Spark. Это решение можно реализовать очень быстро без изменения конфигурации кластера. Также оно дает выделенную среду для каждого пользователя, снижая нагрузку на сервер. Однако, возможны сбои в настройке, например, использование слишком большого количества ресурсов или задание неправильной конфигурации. Кроме того, необходим доступ к узлу кластера и есть еще пара ограничений в использовании:
- только интерпретатор Python (PySpark);
- для каждого сервера доступна только одна среда (например, Conda, Mamba или virtualenv).
Вместо этого способа можно использовать 2 других на основе Apache Livy – службы, которая обеспечивает простое взаимодействие с кластером Spark через REST API, включая отправку заданий или фрагментов кода, синхронное или асинхронное получение результатов, а также управление контекстом. Как это сделать, рассмотрим далее.
Применение Sparkmagic
Sparkmagic — это расширение Jupyter, позволяющее запускать процессы Spark через Livy. Это набор инструментов для интерактивной работы с удаленными кластерами Spark в блокнотах Jupyter. Sparkmagic взаимодействует с удаленными кластерами через сервер REST, реализованный как Livy для запуска интерактивных сеансов на YARN или Lighter для взаимодействия с распределенными приложениями в Kubernetes или Hadoop YARN.
Sparkmagic включает набор инструментов для интерактивного запуска кода Spark на нескольких языках, а также несколько ядер, которые можно использовать для превращения Jupyter в интегрированную среду Spark. Lighter поддерживает интерактивные сеансы Python через ядро Sparkmagic и пакетную отправку приложений через REST API.
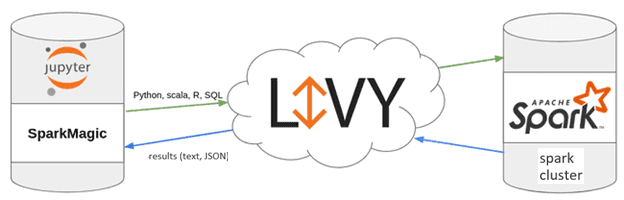
Эта архитектура имеет несколько важных преимуществ:
- отправка локальных файлов или датафреймов в удаленный кластер Spark, например, можно отправить предварительно обученную локальную модель машинного обучения;
- полностью удаленный запуск кода Spark без необходимости устанавливать компоненты фреймворка на сервер Jupyter;
- многоязычная поддержка (Python, Scala, R, SQL);
- автовизуализация (без кода, в GUI) результатов выполнения SQL-запросов в ядрах PySpark, Scala и R;
- автоматическое создание SparkContext и HiveContext (sqlContext);
- поддержка нескольких конечных точек – можно использовать один блокнот для запуска нескольких заданий Spark на разных языках и для разных удаленных кластеров;
- интеграция с любой Python-библиотекой для обработки данных или визуализации, например Pandas или Plotly, включая возможность захвата вывода SQL-запросов в виде датафреймов Pandas для взаимодействия с другими библиотеками (matplotlib и пр.)
- аутентификация с помощью аутентификации Basic Access или через Kerberos;
- доступ к информации и журналам приложений Spark через %%info.
Sparkmagic поддерживает базовую аутентификацию и защищенный протокол Kerberos, а также позволяет работать без всякого механизма аутентификации. Поддержка Kerberos реализована через тикеты Kerberos, забираемые запросами Kerberos из файла кэша. Для доступности тикета Kerberos пользователь должен запустить команду kinit.
Однако, архитектура Sparkmagic имеет следует следующие недостатки:
- добавляет накладные расходы за счет отправки всего кода и вывода через Livy;
- из-за запуска кода на удаленном драйвере через Livy, все структурированные данные должны быть сериализованы в JSON и проанализированы библиотекой Sparkmagic, чтобы ими можно было манипулировать и визуализировать на стороне клиента. На практике это означает необходимость использования Python для обработки данных на стороне клиента в локальном режиме (%%local).
Есть несколько способов использовать Sparkmagic:
- Через ядро IPython для простого запуска кода в удаленном кластере Spark из обычного блокнота IPython;
- через ядра Scala и Python, которые позволяют автоматически подключаться к удаленному кластеру Spark, выполнять код и SQL-запросы, управлять сервером Livy и конфигурацией заданий Spark, а также создавать автоматические визуализации
- наконец, можно отправлять локальные данные в ядро Spark.
Sparkmagic, как способ подключения интерактивных блокнотов Jupyter к защищенному кластеру Spark на Hadoop YARN, имеет следующие преимущества этого решения:
- 3 интерпретатора (Python, Scala и R);
- централизованная настройка ресурсов Spark через файл config.json;
- отсутствие необходимости в физическом доступе к кластеру для пользователей;
- возможность иметь несколько доступных сред Python;
- подключение JupyterHub к LDAP.
К недостаткам этого решения относятся возможные сбои в настройке из-за потребления слишком большого количества ресурсов или неправильной конфигурации и более сложное развертывание. Именно поэтому MLOps-инженеры компании Udemy решили использовать вместо SparkMagic инструменты облачной платформы Amazon SageMaker, что мы рассказываем в нашей новой статье.
Использование Lighter
В заключение рассмотрим, что представляет собой проект Lighter, тоже основанный на Apache Livy. Он поддерживает два типа Spark-приложений: пакетные и интерактивные сеансы. Когда клиент отправляет пакетное приложение с помощью REST API, Lighter сохраняет предоставленное приложение во внутренней памяти для последующего выполнения. Процесс выполнения периодически проверяет наличие новых приложений и отправляет их на настроенный бэкенд (YARN или Kubernetes). Процесс отслеживания периодически проверяет состояние запущенных приложений и синхронизирует его с внутренней памятью Lighter.
Интерактивные сеансы работают аналогичным образом, но в этом случае Lighter отправляет специальное приложение PySpark, которое содержит бесконечный цикл и принимает операторы команд от Lighter через Py4J Gateway – мост между Python и Java, который позволяет программам, работающим в интерпретаторе Python, динамически обращаться к объектам Java внутри JVM.
Освойте администрирование и эксплуатацию Apache Spark для разработки приложений аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источники

