
15 июня 2023 года опубликован очередной выпуск самой популярной распределенной платформы потоковой передачи событий. Разбираемся с новинками Apache Kafka 3.5.0, особенно важными для разработчиков, дата-инженеров и администраторов кластера. Обновления брокеров, контроллеров, продюсеров и потребителей Релиз Apache Kafka 3.5.0 богат на новинки: в нем 50 улучшений и почти 80 исправленных ошибок....

Формат данных в озере или гибридном хранилище типа Data LakeHouse сильно влияет на скорость выполнения аналитических запросов. Сегодня рассмотрим, как Apache CarbonData делает аналитику больших данных в реальном времени еще быстрее. Что такое Apache CarbonData Традиционные форматы данных, часто используемые в проектах Big Data, такие как CSV и AVRO, имеют...
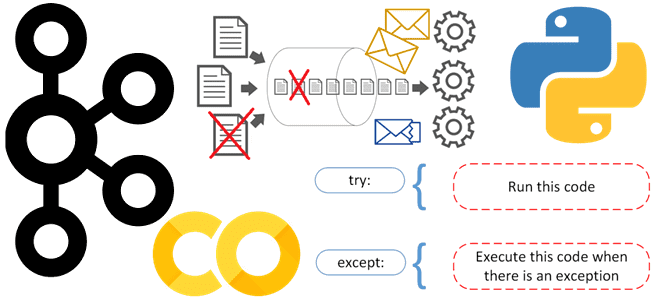
Самый простой способ организовать обработку и логирование ошибок в приложении-потребителе, чтобы продолжать считывание из Apache Kafka, даже если продюсер изменил структуру полезной нагрузки сообщения. Публикация данных в Kafka Напомним, Apache Kafka, в отличие от RabbitMQ, не позволяет организовать очередь недоставленных сообщений (DLQ, Dead Letter Queue) средствами самой платформы, о чем мы...
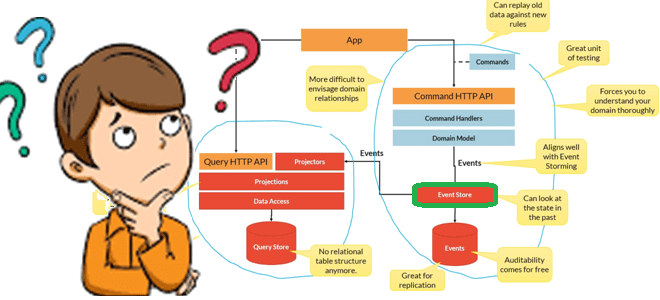
Что представляет собой паттерн проектирования микросервисов под названием источник событий (Event Sourcing) и как его реализовать в реляционных базах данных и NoSQL-системах. Разбираемся с архитектурой данных и архитектурой ПО на практических примерах. Архитектурный шаблон Event Sourcing Многие архитектурные шаблоны рассматривают сущности (entity) как основную концепцию, описывая способы их сохранения и...

Недавно мы писали про группы общего доступа в Apache Kafka, которые планируется реализовать в KIP-932. Сегодня рассмотрим, как именно это предполагается сделать. Принципы работы группы общего доступа Предложение по улучшению Kafka (KIP, Kafka Improvement Proposal) предполагает внесение значительных изменений. Все начинается с публикации предложения, которое рассматривается сообществом, комментируется и пересматривается до...
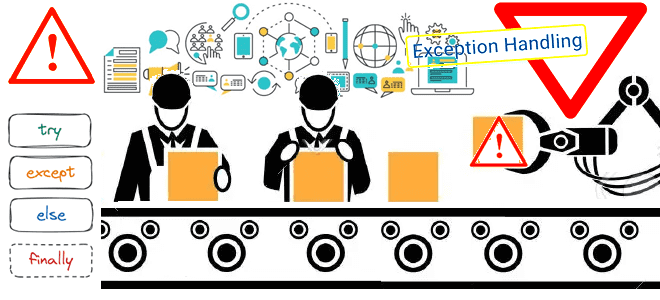
Сегодня поговорим о том, как обработка исключений позволяет спроектировать и реализовать надежную архитектуру конвейера обработки данных, включая ETL/ELT-процессы и их компоненты. Архитектура конвейеров обработки данных: ETL/ELT-процессы Наличие хорошо спроектированной инфраструктуры данных необходимо для получения максимальной отдачи от данных для data-driven управления. Поскольку данные постоянно увеличиваются в объеме, следует организовать управление...
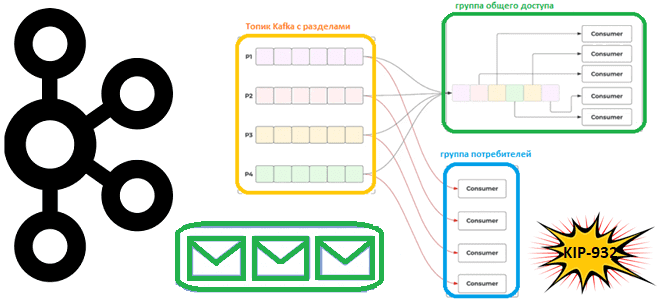
Что такое группы общего доступа для потребителей, чем это отличается от существующей концепции группы потребителей, почему в Apache Kafka появляются очереди и чем это улучшит потоковую обработку событий. Что такое KIP-932: группы общего доступа потребления данных из Apache Kafka Напомним, группы потребителей в Kafka предназначены для повышения надежности упорядоченной доставки...
Что такое «проблема разделенного мозга» в распределенных системах, почему она возникает, при чем здесь зомби-продюсеры и как с этим бороться. Разбираем на примере Apache Kafka. Проблема разделенного мозга или зомби-процессы в распределенных системах Термин зомби-процесс пришел из области операционных систем, однако, в распределенных системах его интерпретация абсолютно противоположна исходному значению....
Что такое безиндексная смежность и как она снижает сложность алгоритмов обхода графа, позволяя быстро и эффективно запрашивать множество узлов и отношений. Разбираемся с уникальными принципами работы графовых баз данных на примере Neo4j. Архитектура и принципы работы графовых баз данных Несмотря на стремление разработчиков современных СУБД к унификации их решений, первичная...
Недавно мы писали, чем Kafka Streams отличается от Consumer API. Сегодня рассмотрим, в чем разница между Kafka Streams и ksqlDB, а также разберем, почему использовать этот компонент экосистемы Apache Kafka не так просто. Как работает ksqlDB: практический пример Apache Kafka является полноценной экосистемой потоковой передачи, вокруг которой существует множество полезных...