Недавно мы писали, чем Kafka Streams отличается от Consumer API. Сегодня рассмотрим, в чем разница между Kafka Streams и ksqlDB, а также разберем, почему использовать этот компонент экосистемы Apache Kafka не так просто.
Как работает ksqlDB: практический пример
Apache Kafka является полноценной экосистемой потоковой передачи, вокруг которой существует множество полезных компонентов. Одним из них является ksqlDB — база данных, специально созданная для приложений потоковой обработки поверх платформы, которая позволяет обрабатывать топики как традиционные таблицы реляционных баз данных с помощью SQL-запросов. Главными структурами данных в ksqlDB являются потоки и таблицы. Потоки похожи на обычные топики — неизменяемые коллекции только для добавления, то есть постоянно растущий список сообщений. Потоки можно использовать для представления исторической последовательности событий, например финансовых транзакций.
Таблицы представляют собой изменяемые коллекции, отражающие текущее состояние (моментальный снимок), используя концепцию первичных ключей. При получении сообщений в таблице будут храниться только последние значения для данного ключа.
Потоки и таблицы основаны на одной и той же структуре сообщения в топике. А порог использования этой технологии снижается благодаря тому, что ksqlDB позволяет вместо разработки полноценного кода использовать SQL-запросы, которыми владеет каждый аналитик.
Однако, ksqlDB не является программой с открытым исходным кодом, а принадлежит корпорации Confluent, которая предоставляет бесплатную версию этого продукта для автономного использования. Ее можно скачать с официального сайта и установить на локальный компьютер. Поэтому попробовать непосредственную работу с ksqlDB у меня, к сожалению, не получилось, т.к. необходим работающий сервер ksqlDB на порту 8088, а я пишу и запускаю Python-код в интерактивной среде Google Colab без локальной среды разработки.
Очень полезной фичей ksqlDB являются материализованные представления, которые постепенно обновляются в реальном времени и их можно запрашивать, используя SQL-запросы типа pull. А push-запросы являются непрерывными и передают дополнительные результаты клиентам в режиме реального времени. Для интеграции с внешним источником или приемником данных используется компонент Connect, о чем мы писали здесь.
Таким образом, ksqlDB позволяет создать полноценное надежное и масштабируемое приложение потоковой передачи, используя только SQL-операторы, сокращая сложность и операционные накладные расходы на агрегацию, соединение, работу с окнами, фильтрацию и преобразования потоков данных.
Поскольку ksqlDB не может напрямую обрабатывать сообщения в топиках Kafka, нужно определить поток (STREAM), что эквивалентно созданию таблицы в SQL. Необходимо указать название, список столбцов с соответствующими типами и некоторые конфигурации в предложении WITH. Также надо задать название топика. Названия и типы данных столбцов в таблице ksqlDB должны соответствовать полям в исходных сообщениях топика.
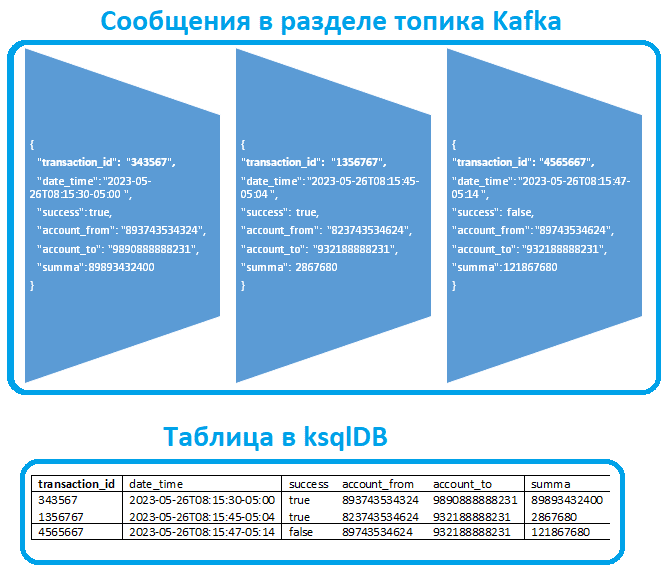
Например, в топике Kafka лежат сообщения с полезной нагрузкой в JSON-формате, которая содержит сведения о финансовых транзакциях:
{
"transaction_id": "343567",
"date_time": "2023-05-26T08:15:30-05:00 ",
"success": true,
"account_from": "893743534324",
"account_to": "9890888888231",
"summa": 89893432400
}
Тогда SQL-запрос на создание поточной таблицы в ksqlDB должен выглядеть так:
CREATE STREAM transactions_table (
transaction_id VARCHAR(STRING) key,
date_time TIMESTAMP,
success BOOLEAN,
account_from VARCHAR(STRING),
account_to VARCHAR(STRING),
summa INT
)
WITH (VALUE_FORMAT='JSON', PARTITIONS=0, KAFKA_TOPIC='topic_name');
Создав табличное представление потока, далее можно запрашивать его в CLI-интерфейсе ksqlDB. Например, следующий SQL-запрос покажет сумму всех успешных переводов на счет с номером 9890888888231 за последний месяц:
SELECT SUM(summa) FROM transactions_table WHERE account_to = "9890888888231" AND success=true GROUP BY account_to HAVING date_time BETWEEN (CURRENT_DATE - 30) AND (CURRENT_DATE);
Как работает Kafka Streams
Напомним, Kafka Streams представляет собой библиотеку для потоковой обработки событий в реальном времени, действуя поверх клиента Kafka Consumer. Приложение Kafka Streams позволяет определяет свою вычислительную логику через одну или несколько топологий процессора, но работает не внутри брокера, а запускается в отдельном экземпляре JVM или полностью в отдельном кластере.
Kafka Streams имеет единый поток для потребления и производства событий в одном кластере Kafka, может выполнять сложную потоковую обработку и поддерживает как stateless-, так и stateful-операции. Разработчик приложения Kafka Streams может реализовывать сложную бизнес-логику на Java или Scala, задавая топологию процессоров, которые будут выполнять преобразования, агрегации, соединения, фильтрацию и другие вычисления над потоками данных, включая интеграции с внешними системами или API-интерфейсами.
Аналогично ksqlDB, Kafka Streams также имеет потоки (KStreams) и таблицы (KTables). Таблицы – это набор изменяющихся фактов: каждое новое событие перезаписывает старое, а потоки представляют собой набор неизменных фактов. KStream обрабатывает поток записей, полный поток данных из топика. KTable управляет потоком журнала изменений с последним состоянием ключа, сохраняя состояние за счет сбора данных из потоков. Каждая запись данных представляет собой обновление.
Однако, с точки зрения алгоритмической сложности программы Kafka Streams намного сложнее SQL-запросов к ksqlDB, но требуют полноценной разработки кода. В частности, из-за сложностей реализации асинхронных вызовов мне пока не удалось разработать и запустить в Google Colab приложение Kafka Streams с помощью Python-библиотеки Faust. Но я все-таки надеюсь сделать это и расскажу об успехах в следующий раз. В заключение отмечу, что ksqlDB отлично подходит для проверки гипотез и создания простых аналитических приложений мониторинга или обогащения событий в реальном времени, когда структуры данных относительно просты, например, без вложенных JSON-объектов.
Освойте администрирование и эксплуатацию Apache Kafka для потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Администрирование кластера Kafka
- Apache Kafka для инженеров данных
- Администрирование Arenadata Streaming Kafka
Источники