 740
740 
Что такое безиндексная смежность и как она снижает сложность алгоритмов обхода графа, позволяя быстро и эффективно запрашивать множество узлов и отношений. Разбираемся с уникальными принципами работы графовых баз данных на примере Neo4j.
Архитектура и принципы работы графовых баз данных
Несмотря на стремление разработчиков современных СУБД к унификации их решений, первичная модель управления данными остается ключевым фактором при проектировании архитектуры информационных систем. К примеру, недавно мы писали о том, что в PostgreSQL и Greenplum существуют инструменты работы с графами, хотя эти системы являются классическими представителями реляционных баз данных. В частности, для поддержки графовых моделей в PostgreSQL можно установить расширение Apache AGE (A Graph Extension) на основе ответвления PostgreSQL 10 от Bitnine и мультимодельной базы данных AgensGraph. А в Greenplum используется библиотека MADlib, позволяя выполнять графовые вычисления без перемещения данных в специализированную графовую СУБД. Аналогично можно применять графовые алгоритмы к табличным данным, используя специализированные пакеты, например, Graphframes для Apache Spark, Gelly для Flink, Python-библиотека Networkx и т.д. В частности, примеры применения графовых алгоритмов Python-библиотека Networkx к pandas-датафреймам мы разбирали здесь, здесь и здесь.
Однако, несмотря на возможность применения графовых алгоритмов, во всех вышеупомянутых примерах работа с данными по-прежнему выполняется согласно принципам реляционной алгебры, которая лежит в основе реляционных баз данных и SQL-запросов. Но в графовых СУБД, которые изначально создавались именно для работы с графами, используется совершенно другая идея управления данными и их хранения.
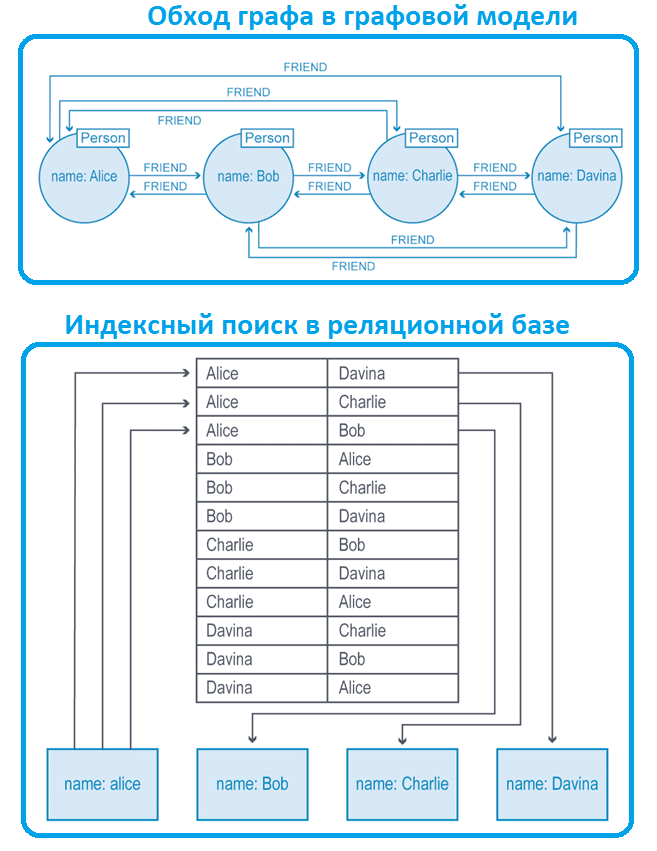
Нативные графовые СУБД представляют данные как элементы графа, т.е. вершины и связи между ними, чтобы хранить их в хранилище и обеспечивать быстрый доступ к ним во время обработки. Благодаря этому операции навигации по глубоким и длинным цепочкам отношений выполняются намного быстрее, чем в таблицах реляционных баз. Поэтому запросы выполняются быстрее и лучше масштабируются за счет специальных шаблонов обхода графа без накладных расходов на поиск по индексу или другие стратегии соединения. Такую возможность обхода связанных данных без накладных расходов на поиск индекса для каждого перемещения по отношению называется смежностью без индекса или безиндексной смежностью.
Возможности обработки с использованием безиндексной смежности присутствуют в нативной графовой СУБД по умолчанию. Это означает, что каждый узел напрямую ссылается на соседние узлы, т.е. доступ к отношениям и связанным данным представляет собой просто поиск указателя памяти. Благодаря этому время обработки графа пропорциональным количеству обработанных данных, а не экспоненциально увеличивается с количеством пройденных отношений и узлов.
Таким образом, графовые запросы выполняются с постоянной скоростью в зависимости от объема обрабатываемых данных, но независимо от общего размера базы. А поскольку базы данных графов хранят данные об отношениях как объекты первого класса, их легче перемещать в любом направлении. Это повышает эффективность обхода графа вместо зависимости от индексов для соединений.
В отличие от графовых баз, реляционные системы используют множество типов индексов для вычисления соединений для связывания сущностей вместе. Этот метод более затратный, т.к. индексы добавляют еще один слой к каждому чтению и записи, что значительно замедляет обработку. А запросы с несколькими операторами JOIN еще больше снижают производительность. Особенно это становится заметно на большом объеме данных в распределенных системах, когда размеры соединяемых датасетов сильно отличаются и данные по-разному распределены по узлам кластера. При попытке реализовать обход графа в реляционной базе каждое соединение выполняет два поиска по индексу. А, чтобы изменить направление запроса, придется создать дорогостоящий индекс обратного просмотра для каждого обхода или выполнить прямой поиск по исходному индексу. Оба этих метода работают, но не являются эффективными с точки зрения времени и скорости выполнения запросов.
Не графовые базы данных используют другую парадигму для хранения и обработки, добавляя слой или графовый API поверх своей модели представления данных, которая изначально была разработана для других потребностей. Как правило, в таких системах используется поиск по индексу, чтобы перейти к следующему элементу в цепочке для завершения транзакции чтения или записи. Сложность поиска по индексу часто составляет O (log (n)) по сравнению с O (1) для следования прямому указателю отношения к целевому узлу.
Помимо модели управления данными, реализованной в СУБД, графовые системы также имеют хранилище данных, специально оптимизированное для размещения узлов и связей близко друг к другу. В базах данных других типов (реляционная, документо-ориентированная или key-value) данные об узлах и связях хранятся в хранилище как несвязанные объекты, которые могут оказаться далеко друг от друга. Данные графа, т.е. узлы и отношения, в НЕграфовой базе хранятся в виде таблиц или документов, а алгоритмы работы с ними должны каждый раз обновлять или считывать эти узлы и отношения заново для каждого запроса. Это вызывает проблемы с производительностью запросов на большом объеме данных. Кроме того, многократно возрастает сложность аналитических SQL-запросов, что мы разбирали в статье блога нашей Школы прикладного бизнес-анализа и проектирования информационных систем.
В нативной графовой базе данных основная цель записи узла или отношения — просто указать на структурированные списки его меток и свойств, поиск по которым реализуется с помощью графового языка запросов. Если на разных концах одного ребра несколько узлов, речь идет о гиперграфе, что реализации которого требуются специальные средства, например, HyperGraphDB. Таким языком во многих графовых базах данных является Cypher, примеры работы с которым мы разбирали здесь и здесь. Кроме того, в графовой базе каждый уровень архитектуры, от среды выполнения языка запросов до управления файлами хранилища на диске, изначально спроектирован и оптимизирован для хранения и запроса графовых данных. Читайте в нашей новой статье о том, как runtime-среда Cypher-запросов в Neo4j влияет на их скорость их выполнения.
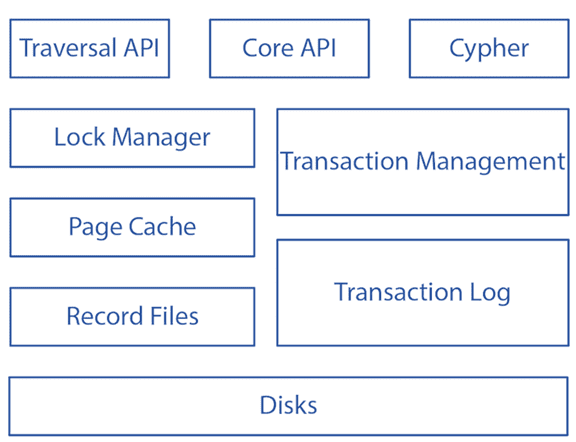
Как эта графовая архитектура управления данными реализуется в популярной СУБД Neo4j, мы рассмотрим в следующий раз. А в заключение отметим, что именно ключевыми критериями выбора графовой базы данных остается ключевое назначение системы, в рамках которой ее планируется использовать. Если объем данных очень велик и варианты использования соответствуют типовым задачам на графах, например, поиск путей, сообществ или анализ социальных связей, тогда графовая база данных будет оптимальным решением для такого сервиса. О том, чем графовые базы данных полезны в системах агентского ИИ, читайте в нашей новой статье.
Узнайте больше про методы и средства работы с графами для эффективного применения в реальных проектах аналитики больших данных на специализированных курсах нашего лицензированного учебного центра обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

