Что такое «проблема разделенного мозга» в распределенных системах, почему она возникает, при чем здесь зомби-продюсеры и как с этим бороться. Разбираем на примере Apache Kafka.
Проблема разделенного мозга или зомби-процессы в распределенных системах
Термин зомби-процесс пришел из области операционных систем, однако, в распределенных системах его интерпретация абсолютно противоположна исходному значению. В Unix-подобных системах процесс называется зомби, когда он фактически завершил свое выполнение, но все еще остается в таблице процессов. О том, как это явление проявляется в Apache AirFlow, мы писали здесь. Однако, в распределенных системах значение этого термина трактуется по-другому: зомби-процессами называются те, которые считаются завершенными для других компонентов, хотя фактически они еще не завершили свое выполнение. Чаще всего это случается из-за временных проблем с сетью, когда процесс был недоступен в течение некоторого времени, за которое уже был запущена замена.
Одним из примеров является система репликации с одним первичным узлом, который работает на чтение и запись данных, и несколькими вторичными узлами, которые доступны только для чтения. Когда первичный узел теряет связь с другими узлами, одна из реплик становится новым лидером и выполняет его функции. В то же время прежний лидер может все еще оставаться доступным для приложения и по-прежнему обрабатывать запросы на запись. Но эти запросы уже не реплицируются на другие узлы, так как соединение теряется. Также этот зомби-лидер уже не получает новых данных от других узлов. При восстановлении связи данные, распределенные по узлам, сложно синхронизировать. Такую ситуацию называют проблемой разделенного мозга, когда вместо единого лидера в распределенной системе их получается несколько. Это чревато рассогласованием данных, поскольку оба мозга, т.е. лидера, являются активными и могут вносить противоречивые изменения одновременно.
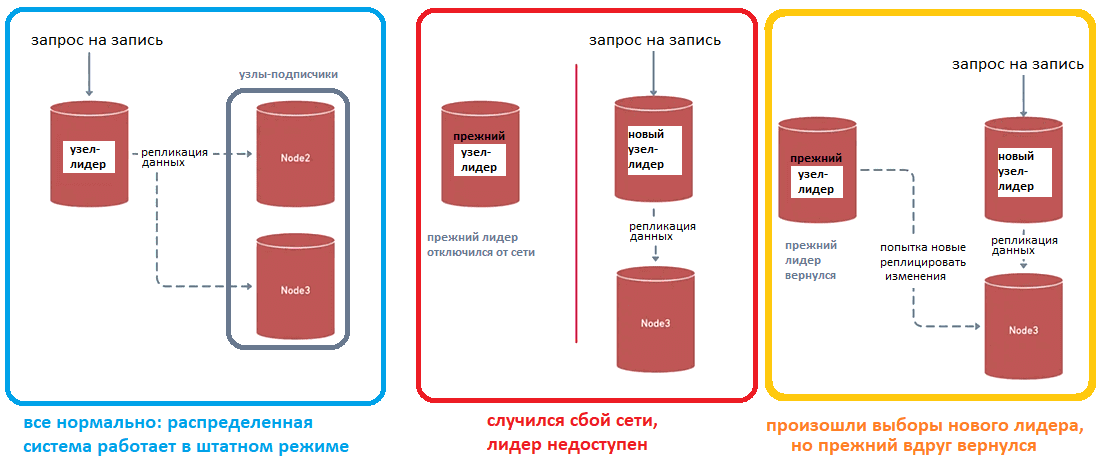
Дополнительную сложность в подобную ситуацию вносят многокластерные развертывания. К примеру, в двух дата-центрах есть пять реплик баз данных: две в одном с текущим лидером и три в другом. Предположим, случился сбой сетевого соединения между этими дата-центрами, хотя все узлы в каждом из них продолжают работать и доступны из других мест. Должны ли три реплики во втором дата-центре выбрать нового лидера? Как синхронизировать данные, когда соединение между дата-центрами будет восстановлено? Ответить на эти вопросы помогают решения, реализующие один или сразу несколько следующих механизмов:
- сторонний актор – независимое приложение вне кластера, которое может проверить доступность всех узлов, например, балансировщик нагрузки, сервис синхронизации метаданных Apache Zookeeper или другое специализированное кластерное ПО, которое проверяет доступность узлов с помощью периодических сигнальных тактов (hearbeat-сигнал) или регистрирует узлы внутри приложения, маркируя основным лишь один узел.
- Консенсус — решение о текущем лидере принимается на основе голосования узлов.Чтобы сделать одну из реплик основной, она должна получить большинство голосов, т.е. собрать кворум. Например, так работают кластеры MongoDB и Hazelcast, используя кворум для операций записи. Если операция записи не может быть выполнена на достаточном количестве членов кластера, возникает исключение.
- Номера эпох — в кластере доступен номер эпохи, который монотонно увеличивается при каждой смене лидера. Все узлы принимают только действия, выполненные с использованием текущего значения этого числа. Когда старый лидер отключается от других узлов, он сохраняет номер старой эпохи и больше не сможет применять изменения.
Рассмотрим, какие из этих принципов используются в Apache Kafka.
Решение проблемы в Apache Kafka
Apache Kafka гарантирует строго однократную доставку сообщений и их хронологический порядок в пределах одного раздела. Эти функции предъявляют дополнительные требования к приложениям-продюсерам сообщений. Каждый продюсер должен быть уникальным и использовать уникальные последовательные идентификаторы сообщений, чтобы брокера мог обнаруживать зомби и отклонять сообщения, которые они пытаются отправить. В Apache Kafka у каждого продюсера есть собственный идентификатор транзакции, который регистрируется в кластере Kafka при первой операции после запуска продюсера. Также есть номер эпохи, связанный с идентификатором транзакции, который хранится на брокере в качестве метаданных. Когда продюсер регистрирует существующий идентификатор транзакции, брокер предполагает, что это новый экземпляр продюсера, и увеличивает номер эпохи. Новый номер эпохи включается в транзакцию, и если он меньше вновь сгенерированного номера эпохи, координатор транзакций отклоняет эту транзакцию.
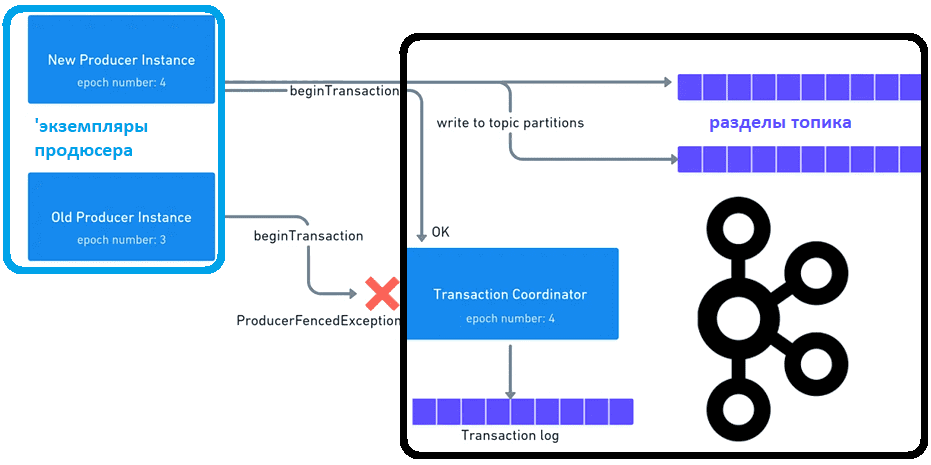
Вспомнив основы публикации сообщений в Kafka, что мы подробно разбирали здесь, рассмотрим как эта платформа потоковой передачи событий решает проблему разделенного мозга. Когда экземпляр первого продюсера временно выходит из строя и появляется другой экземпляр, новый экземпляр вызывает метод initTransactions(), который регистрирует тот же идентификатор транзакции и получает новый номер эпохи. Этот номер включается в транзакции и проверяется координатором транзакций. Эта проверка будет успешной для нового продюсера. А если прежний экземпляр приложения-продюсера снова окажется в сети и попытается начать транзакцию, координатор отклонит ее, поскольку она содержит старый номер эпохи. В этом случае производитель получает исключение ProducerFencedException и должен завершить его выполнение.
В заключение поговорим про незавершенные транзакции в Apache Kafka. Когда экземпляр нового продюсера регистрируется в брокере, он не может запуститься, пока не будут завершены все транзакции для предыдущего экземпляра. Для этого координатор транзакций находит в журнале транзакций все транзакции с идентификатором без сообщения COMMITTED. Иначе транзакция прерывается. Таким образом, благодаря наличию координатора транзакций, который запускается внутри каждого брокера и ведет себя как сторонний актор, регистрирующий продюсеров внутри платформы. Это избавляет от зомби-продюсеров и разгружает разработчика: достаточно лишь назначить продюсеру уникальный идентификатор транзакции, а все остальные проверки выполняются на стороне брокера.
Больше деталей про администрирование и эксплуатацию Apache Kafka для потоковой аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Администрирование кластера Kafka
- Apache Kafka для инженеров данных
- Администрирование Arenadata Streaming Kafka
Источники

