Что представляет собой паттерн проектирования микросервисов под названием источник событий (Event Sourcing) и как его реализовать в реляционных базах данных и NoSQL-системах. Разбираемся с архитектурой данных и архитектурой ПО на практических примерах.
Архитектурный шаблон Event Sourcing
Многие архитектурные шаблоны рассматривают сущности (entity) как основную концепцию, описывая способы их сохранения и манипулирования. В таких архитектурах события (event) являются последствиями изменения сущностей. Подробнее о том, что такое событие в EDA-архитектуре, читайте в нашей новой статье. Центральным звеном таких архитектур является хранилище сущностей, например, реляционная СУБД или документо-ориентированная база. Но архитектурный шаблон Event Sourcing, наоборот, фокусируется на реализации событий: как они сохраняются и используются для получения состояния сущности. В данном случае в хранилище хранится последовательный лог всех событий, которые произошли за время существования системы. Эти записи служат источником получения текущего состояния сущности и журналом аудита того, что происходило в приложении за время его существования. Event sourcing способствует децентрализованному изменению и чтению данных. Такая архитектура, управляемая событиями (EDA, Evant Driven Architecture) хорошо масштабируется и подходит для асинхронной интеграции приложений и систем потоковой обработки информации.
Если рассматривать такую систему как совокупность сущностей, представляющих собой контейнеры для хранения состояния, то события отображают изменения сущностей в результате обработки входных данных в рамках различных бизнес-процессов. Часто события инициируется командами (command), исходящими от пользователей, фоновых процессов или интеграций с внешними системами.
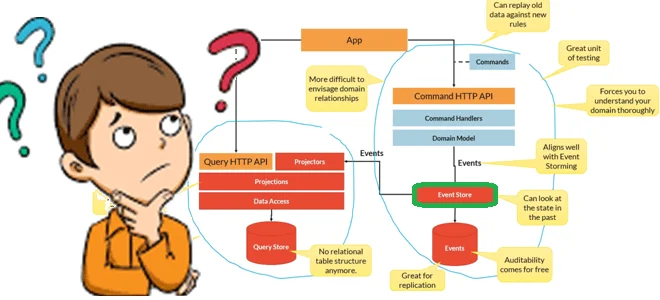
Архитектурный шаблон Event Sourcing фокусируется на событиях, связанных с изменениями в системе, и является парадигмой моделирования предметной области. Он способствует децентрализованному изменению и чтению данных, а потому отлично сочетается с паттерном CQRS (Command Query Responsibility Segregation) – шаблоном разделения ответственности на команды (Command) и запросы (Query). Команды ориентированы на задачи манипуляций с данными, а не на сами данные, они могут помещаться в очередь для асинхронной обработки, а не обрабатываться синхронно. Запрос представляет собой операцию чтения, которая не изменяет базу данных.
Наличие отдельных моделей запросов и команд упрощает проектирование систем, повышает безопасность и эффективность выполнения типовых сценариев. В частности, для запросов можно использовать материализованные представления вместо сложных операций соединения через JOIN-операторы. Также CQRS дает большой простор для выбора хранилища данных, позволяя совмещать реляционные и NoSQL-решения. Если для чтения и записи используются разные базы данных, они должны поддерживать синхронизацию. Обычно это реализуется с помощью событий или захвата измененных данных (CDC, Change Data Capture) при каждом обновлении базы. Обновление базы данных и публикации события должны выполняться в рамках одной транзакции.
Каждое событие в Event Sourcing может обрабатывать несколько задач. Это обеспечивает простую интеграцию с внешними сервисами и системами, которые только слушают новые события. Но сама суть этого паттерна, которая сильно отличается от более привычной парадигмы работы с сущностями с помощью CRUD-операций повышает порог входа в технологию. В частности, Event Sourcing требует много ресурсов на моделирование событий. После сохранения событий в хранилище они должны быть неизменяемыми (immutable), иначе история и состояние могут быть повреждены или искажены. Логи событий являются исходными данными, которые должны содержать всю информацию, необходимую для получения полного состояния системы на определенный момент времени. Также необходимо учитывать, что события могут интерпретироваться повторно, поскольку система и ее бизнес-контекст меняются со временем. Благодаря горизонтальному масштабированию лога событий паттерн Event Sourcing хорошо работает в больших системах, но эта легкость усложняет согласованность данных, в т.ч. конечную (eventual consistency).
Поэтому важно учитывать структуру событий и ее эволюцию. Расширяемая схема событий поможет отличать новые события от старых, а периодические моментальные снимки базы данных дают возможность выделить серьезные изменения структуры событий. Обычно при использовании паттерна Event Sourcing события сохраняются в хранилище событий и транслируются с использованием подхода публикации/подписки (pub/sub), чтобы информировать микросервисы-потребители об изменении данных.
Таким образом, Event Sourcing подходит, если в данные необходимо записать намерение, цель или причину их создания/изменения. Также этот шаблон подходит, когда нужно сократить или совсем исключить конфликты операций обновления данных, записывать происходящие события и иметь возможность воспроизвести их для восстановления определенного состояния системы, отката изменений, сохранения истории и аудита логов. Еще одним сценарием использования Event Sourcing является вариант, когда задача включает несколько шагов, необходимых для восстановления обновлений и последующего воспроизведения некоторых действий для восстановления согласованного состояния данных.
Если работа с событиями является типовой операцией приложения или процесс ввода/ обновления данных является многоэтапным и сложным, Event Sourcing может повысить эффективность системы, например, для распределения событий в другие слушатели, выполняющие определенные действия при их возникновении. Например, интеграция платежной системы с веб-сайтом, чтобы события обновления данных, реализованные для веб-сайта, использовались также платежной системой. Когда необходима гибкость для изменения формата материализованных моделей и данных сущности при изменении требований или адаптации модели чтения, Event Sourcing в сочетании с CQRS будет хорошим выбором.
Однако, для простых приложений, которые работают с данными по примитивной CRUD-модели, нет необходимости применять это сложный шаблон проектирования, также как и для потоковых систем реального времени и там, где для отката и воспроизведения действий не требуются аудит логов и историчность. Аналогичное замечание справедливо и для OLTP-систем, которые преимущественно добавляют данные, а не обновляют их.
Стоит отметить, что для Event Sourcing существуют определенные ограничения. Этот шаблон подходит для проектирования микросервисов, но не для их интеграции между собой, поскольку ориентирован на применение в ограниченном контексте. Способ хранения данных в Event Sourcing не должен становиться публичным API. Для взаимодействия между ограниченными контекстами, т.е. разными микросервисами, лучше использовать отдельные доменные события, не связанные с событиями Event Sourcing, которые публикуются в глобальном хранилище событий. Это позволяет гибко моделировать доменные события в ограниченных контекстах. Как это сделать, используя хранилища событий, рассмотрим далее, проанализировав, насколько для этой роли подходят реляционные базы данных и NoSQL-СУБД.
Где хранить события для реализации этого шаблона?
Прежде чем определять требования к хранилищу событий для реализации паттерна Event Sourcing, перечислим основные термины этого шаблона проектирования, активно использующиеся в доменно-ориентированном проектировании (DDD, Domain Driven Design):
- состояние– описание состояния системы, ожидающей выполнения перехода;
- переход – набор действий перевода из одного состояния в другое, выполняемых при выполнении условия или получении события;
- событие предметной области— объект, управляющий изменениями состояния в бизнес-процессе;
- агрегат — кластер объектов домена, который можно рассматривать как единое целое, моделирующий ряд правил или инвариантов, которые всегда должны выполняться в системе;
- корень агрегата (Aggregate Root) – материнский объект внутри агрегата, контролирующий и инкапсулирующий доступ к своим членам так, чтобы защитить его инварианты;
- инвариант— описывает то, что должно быть истинным в проекте всегда, кроме перехода в новое состояние. Инварианты помогают обнаружить ограниченный контекст.
- ограниченный контекст— граница системы, предназначенная для решения конкретной проблемы предметной области. Ограниченный контекст объединяет модель, которая может иметь один или несколько объектов, которые будут иметь инварианты внутри и между ними.
Чтобы реализовать эти понятия DDD в шаблоне Event Sourcing, необходимо иметь хранилище событий, удовлетворяющее следующим требованиям:
- последовательная надежная запись — возможность сохранять изменения состояния в виде последовательности событий, упорядоченных в хронологическом порядке;
- чтение агрегата домена — возможность считывать события отдельных агрегатов в том порядке, в котором они сохранялись;
- последовательное чтение — возможность читать все события в том порядке, в котором они были сохранены;
- транзакционная запись — возможность записи набора событий в одной транзакции, т.е. все события записываются в хранилище или не записывается ни одно из них.
Реализовать эти требования в реляционной базе данных можно с использованием всего двух таблиц: одна для хранения фактического журнала событий, сохраняющая одну запись для каждого события, а другая для хранения источников событий. Само событие хранится в отдельном столбце с использованием какой-либо формы сериализации. Номер версии также хранится вместе с каждым событием в таблице событий в виде автоматически увеличивающегося целого числа. Каждое сохраняемое событие имеет инкрементируемый номер версии, который уникален и последователен только в контексте данного источника событий, поскольку корень агрегата ограничивает согласованность данных. Последовательность, другое целое число с автоматическим инкрементом, также является уникальным и последовательным и хранит глобальную последовательность событий на основе отметки времени.
Столбец с идентификатором источника событий является внешним ключом, который следует индексировать, он указывает на таблицу источников событий, которая хранит сведения о провайдере источника событий (агрегатов). Каждый агрегат имеет запись в этой таблице. Наряду с идентификатором происходит денормализация номера текущей версии, чтобы не выполнять JOIN-операции с таблицей событий. Также в таблице с источниками событий хранится их тип, который будет полным именем типа сохраняемого поставщика источника событий.
Например, объектно-реляционная СУБД PostgreSQL имеет множество расширений, позволяя реализовать схему для эффективного хранения событий, которая позволит писать запросы для полного последовательного чтения или поиск всех событий, связанных с определенным идентификатором источника событий. PostgreSQL также соответствует ACID-требованиям к транзакциям, что дает возможность записывать и считывать события транзакционным способом, обеспечивая целостность и согласованность данных. Политика добавления событий может быть реализована в PostgreSQL без операторов UPDATE или DELETE в записях, чтобы сохранять события в хронологическом порядке по мере добавления новых строк в таблицу. Все, что относится к PostgreSQL? Характерно и для Greenplum, которая является кластерным вариантом этой СУБД с механизмом массовой параллельной загрузки данных.
В NoSQL-хранилище типа ключ-значение событие можно смоделировать, создав ключ как комбинацию совокупного идентификатора и номера версии. В качестве значения будут сериализованные данные события. Так можно хранить события в хронологическом порядке для определенного агрегата. Можно получить события для конкретного агрегата, зная только его идентификатор и увеличивая номер версии до тех пор, пока не будет найден нужный ключ. Однако, при попытке получить события для любого агрегата возникает проблема, поскольку часть ключа неизвестна. Следовательно, становится невозможным получить эти события в том порядке, в котором они были сохранены. Кроме того, важно отметить, что во многих хранилищах ключей-значений отсутствуют возможности транзакций.
С точки зрения практической реализации одной из самых популярных NoSQL-баз типа key/value является Redis, о чем мы писали здесь. В Redis значения ключей могут быть разного типа данных, что определяет различный набор команд для операций над ними. В частности, Redis поддерживает потоковый тип данных (Streams), который отличается от традиционного Pub/Sub и больше похож на файл журнала только для добавления, как в Apache Kafka.
Потоки Redis позволяют добавлять новые события в поток, гарантируя, что они будут упорядочены и сохранены последовательно. Каждое событие в потоке связано с уникальным идентификатором, что позволяет извлекать события в зависимости от порядка их поступления. Кроме того, Redis Streams поддерживает несколько потребителей, что позволяет различным компонентам или службам использовать события из одного и того же потока.
При использовании Redis Streams в качестве хранилища событий можно хранить данные событий вместе с любыми необходимыми метаданными. Это позволяет фиксировать важные сведения о событии, такие как его тип, отметка времени и полезные данные. Система команд Redis для типа данных Streams позволяет публиковать, потреблять и обрабатывать события масштабируемым образом. Тем не менее, из-за резидентного характера Redis для надежности и постоянства данных могут потребоваться дополнительные механизмы их репликации. Кроме того, необходимо реализовать контроль доступа и меры безопасности для защиты данных о событиях, хранящихся в этой key-value СУБД.
Документо-ориентированная база данных позволяет хранить все события, связанные с агрегатом, в одном документе или вообще представлять каждое событие как отдельный документ. Для сохранения хронологического порядка в документ можно включить поле версии события. Когда все события, относящиеся к агрегату, хранятся в одном документе, можно выполнить запрос для их извлечения в порядке возрастания номеров версий. В результате возвращенные события сохранят тот же порядок, в котором они были сохранены.
Однако, если в одном документе хранится несколько событий из разных агрегатов, получить их в правильной последовательности сложнее. Один из возможных подходов состоит в извлечении всех событий и последующей их сортировке по отметке времени. Но этот метод будет неэффективным. К счастью, большинство документо-ориентированных хранилищ поддерживают ACID-транзакции внутри документа, позволяя записывать набор событий в рамках одной транзакции.
Примером такой реализации может быть MongoDB, популярная документо-ориентированная база данных, которая имеет высокую масштабируемость за счет сегментирования и хранения без схемы. Обеспечить порядок и последовательность событий поможет метка времени или номер версии в каждом документе. Это позволяет извлекать события в том порядке, в котором они были сохранены, путем сортировки по метке времени или по номеру версии. Масштабируемость MongoDB обеспечивается за счет распределения данных о событиях по нескольким серверам для обработки больших объемов. Однако, в MongoDB нет встроенного глобального порядкового номера, что мешает добиться полного последовательного чтения всех событий. Исправить это можно, самостоятельно реализовав пользовательскую логику для поддержания порядка последовательности.
В колоночной СУБД, такой как Cassandra или Apache HBase, события могут храниться в виде столбцов, причем каждая строка содержит все события, связанные с агрегатом. Агрегированный идентификатор служит ключом строки, а события хранятся в столбцах. Каждый столбец представляет собой пару ключ-значение, где ключ обозначает номер версии, а значение содержит данные события. Добавить новое событие так же просто, как добавить новый столбец, поскольку количество столбцов может различаться для каждой строки.
Чтобы получить события для определенного агрегата, необходимо знать ключ строки (идентификатор агрегата). Упорядочивая столбцы на основе их ключей, события можно собирать в правильном порядке. Запись набора событий в строке для агрегата включает сохранение каждого события в новом столбце. Многие колоночные базы данных поддерживают транзакции внутри строки, что позволяет выполнять процесс записи в рамках одной транзакции.
Однако, подобно документо-ориентированным хранилищам, колоночные базы данных сталкиваются с проблемой при попытке получить все события в том порядке, в котором они были сохранены. Не существует простого метода для достижения этого результата. В частности, Cassandra, хорошо масштабируемая и распределенная NoSQL-СУБД отлично справляется с обработкой больших объемов данных и обеспечивает высокую доступность за счет согласованности. Модель данных Cassandra основана на распределенной и разделенной архитектуре, что усложняет достижение надежных гарантий последовательности для всех узлов в кластере. Обеспечение строгого упорядочения обычно требует использования облегченной функции транзакций Cassandra, которая может повлиять на производительность и должна использоваться разумно в соответствии с рекомендациями документации. В Event Sourcing, где добавление событий является обычной операцией, использование облегченных транзакций для упорядочивания событий не будет идеальным решением из-за потенциальной потери производительности Cassandra.
Впрочем, хотя Cassandra может не обеспечивать встроенную поддержку надежных гарантий последовательности событий, она позволяет включить метку времени или номер версии в данные события, чтобы упорядочить их в хронологическом порядке во время поиска. А гарантии масштабируемости и отказоустойчивости Cassandra и Apache HBase позволяют им обрабатывать большие объемы событий и обеспечивать высокую доступность для систем с EDA-архитектурой.
Apache Kafka часто упоминается в Event Sourcing из-за своего событийного характера. Однако, использование Kafka в качестве хранилища событий для Event Sourcing часто является предметом споров. Например, нет точного ответа на вопрос, хранить ли события для отдельных агрегатов в одном топике или создавать отдельные топики для каждого агрегата. Хранение всех событий в одном топике позволяет выполнять полное последовательное чтение всех событий, но усложняет их извлечение для определенного агрегата. С другой стороны, хранение событий в отдельных топиках для каждого агрегата может оптимизировать извлечение для отдельных агрегатов, но создает проблемы с масштабированием из-за структуры топиков в Kafka.
Для решения этой проблемы можно использовать различные стратегии. Например, создать топик для каждого агрегата и использовать разделы для распределения событий. Но обеспечение равномерного распределения сущностей по разделам и обработка восстановления глобального порядка событий могут привести к дополнительным сложностям. Кроме того, при использовании Kafka в качестве хранилища событий важно управлять доступом к экземпляру Kafka, чтобы обеспечить конфиденциальность и целостность данных, поскольку любой пользователь, у кого есть доступ, может читать сохраненные топики.
Наконец, использование Kafka в качестве хранилища событий не совсем соответствует традиционному принципу Event Sourcing, заключающегося в сохранении событий перед их публикацией. В Kafka хранение и публикация событий не являются отдельными этапами, т.е. если брокер выйдет из строя во время процесса, события могут быть потеряны.
Обойти ограничения реляционных СУБД и NoSQL-хранилищ может EventStore — специально созданная база данных, которая хорошо согласуется с принципами и требованиями Event Sourcing. Это популярный вариант, написанный на .NET и хорошо интегрированный в экосистему .NET. Это хранилище фокусируется на эффективном хранении событий и управлении ими в EDA-архитектурах и реализации паттерна Event Sourcing. Одной из ключевых особенностей шаблона Event Store является его способность обрабатывать проекции или логику обработки событий в самой базе данных. Так можно эффективно запрашивать и обрабатывать события, позволяя работать с событиями гибким и масштабируемым образом.
Хранилище событий предоставляет необходимые механизмы для хранения событий в режиме добавления, гарантируя, что события неизменяемы и упорядочены. Оно позволяет хранить события для разных агрегатов или сущностей в одном потоке, упрощая извлечение событий для определенного агрегата в том порядке, в котором они были сохранены.
Кроме того, Event Store предлагает мощную ACID-поддержку транзакций, обеспечивая надежное и последовательное сохранение событий и поддерживая целостность данных.
Хранилище событий также предоставляет функции для управления их версиями, обеспечивая совместимость и эволюцию схем событий с течением времени, что важно для обратной совместимости и обработки изменений в структурах данных по мере развития приложения. Также Event Store обычно предлагает встроенные функции для механизмов публикации событий и подписки на события, упрощая управляемую событиями связь и интеграцию в приложении или между микросервисами. Логика обработки событий размещается и выполняется в самом хранилище событий, позволяя гибко обрабатывать события.
Таким образом, каждое хранилище данных имеет свои сильные стороны и ограничения для реализации паттерна Event Sourcing. При выборе хранилища данных для системы с EDA-архитектурой важно учитывать ее масштабируемость, согласованность, последовательность, транзакционность и поддержку запросов.
Узнайте больше подробностей по проектированию и поддержке современных дата-архитектур в проектах аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://blog.jaykmr.com/picking-the-event-store-for-event-sourcing-988246a896bf
- https://microservices.io/patterns/data/event-sourcing.html
- https://bool.dev/blog/detail/pattern-cqrs-i-event-sourcing
- https://habr.com/ru/companies/otus/articles/492066/
- https://habr.com/ru/companies/otus/articles/518282/

