
Мы уже писали про механизмы обеспечения высокой доступности в кластере Greenplum. Сегодня рассмотрим, какие инструменты и приемы помогут выявить сбои координатора и сегментов, а также как администратору кластера этой MPP-СУБД восстановить ее работоспособность. Что такое зеркалирование сегментов Greenplum Напомним, кластер Greenplum представляет собой несколько экземпляров популярной объектно-реляционной базы данных (БД)...
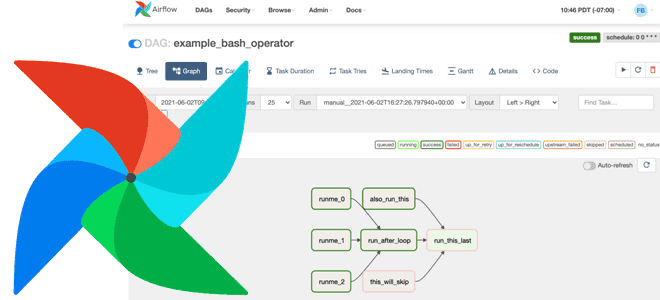
Сегодня рассмотрим, какие ошибки, связанные с DAG, отображаются в пользовательском интерфейсе Apache AirFlow и как дата-инженеру их исправить. А также рассмотрим еще несколько рекомендаций по повышению эффективности этого фреймворка. 4 ошибки с DAG в интерфейсе Apache AirFlow и как их исправить Сегодня все больше компаний, независимо от их домена и...
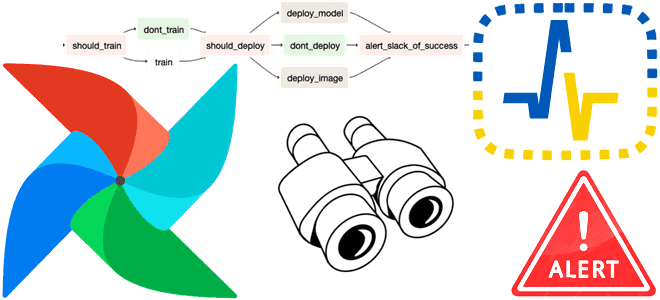
В этой статье для обучения дата-инженеров рассмотрим типы оповещений в Apache AirFlow и их отслеживание в сервисе мониторинга cron-заданий Healthchecks.io. Оповещения Apache AirFlow: какие они бывают и зачем их отслеживать Apache AirFlow позволяет создавать сложные конвейеры обработки данных, которые могут выполняться по расписанию, по событию или запускаться вручную. Для повышения...
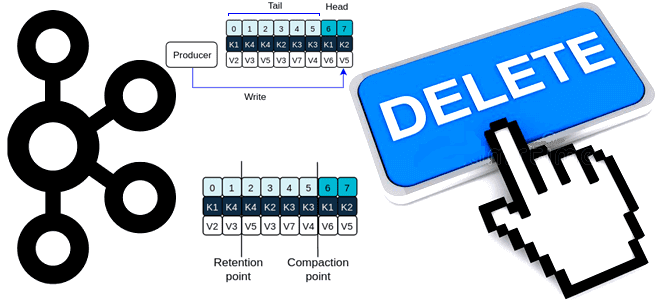
Почему в Apache Kafka нет функций очистки топика и как же все-таки удалить из него все сообщения, если очень нужно, используя конфигурации retention и другие приемы администрирования кластера. Политика очистки и конфигурации retention В отличие от брокеров сообщений, которые после отправки данных приложениям-потребителям, удаляют их из очереди, Apache Kafka хранит...

Как разработчику выбрать подходящий режим развертывания для своего Spark-приложения, достоинства и недостатки клиентского и кластерного режимов, а также особенности запуска под управлением YARN. Архитектура и режимы развертывания Spark-приложения Будучи фреймворком для создания приложений быстрой обработки Big Data, Apache Spark имеет несколько режимов развертывания, которые зависят от варианта запуска Spark-приложения: на...
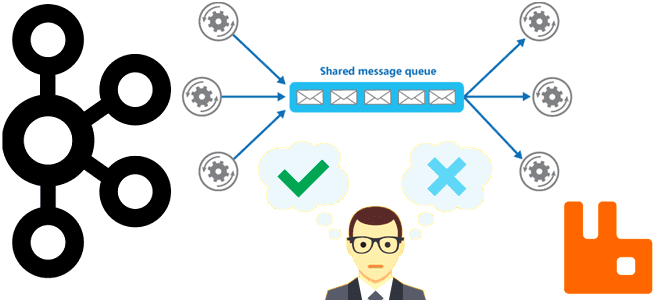
Какие проблемы характерны для распределенных очередей сообщений, почему они случаются и как с ними справиться. Разбираемся со сбоями, ошибками и перегрузками на примере Apache Kafka и RabbitMQ. Проблемы с распределенными очередями и главные причины их появления Хотя Apache Kafka — это целая экосистема со множеством компонентов для потоковой передачи событий,...
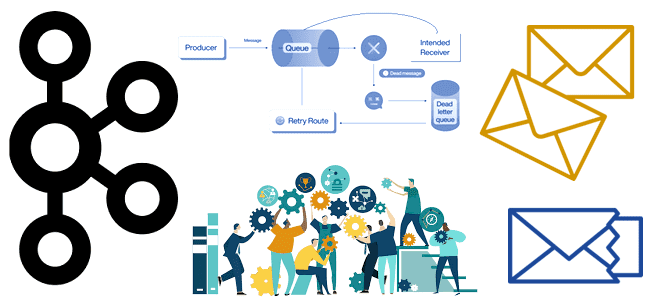
Недавно мы писали про очереди недоставленных сообщений в Apache Kafka и RabbitMQ. Сегодня поговорим про стратегии обработки ошибок, связанные с DLQ-очередями в Kafka, а также рассмотрим, какие сообщения НЕ надо помещать в Dead Letter Queue. 4 стратегии работы с DLQ-топиками в Apache Kafka Напомним, в Apache Kafka в очереди недоставленных...
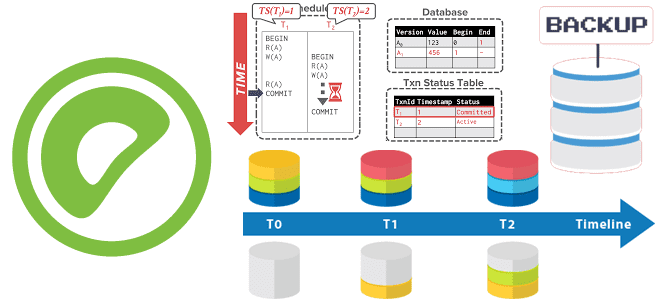
Как Greenplum расширяет MVCC-модель PostgreSQL для управления доступом к данным в многопользовательской среде, обеспечивая согласованность и изоляцию транзакций для нескольких сегментов в большом кластере. Преимущества моментальных снимков перед блокировками и их польза для резервного копирования. MVCC и транзакции в Greenplum с PostgreSQL Будучи основанной на PostgreSQL, о чем мы писали здесь,...

Чтобы сделать наши курсы по Apache NiFi Для дата-инженеров еще более полезными, сегодня поговорим про настройку процессоров. Читайте далее, как распараллелить задачи и потоки, задержать FlowFile, задать обратное давление и настроить другие полезные конфигурации. Как настроить конфигурации процессора Apache NiFi Будучи мощным инструментом дата-инженерии, Apache NiFi содержит множество обработчиков –...
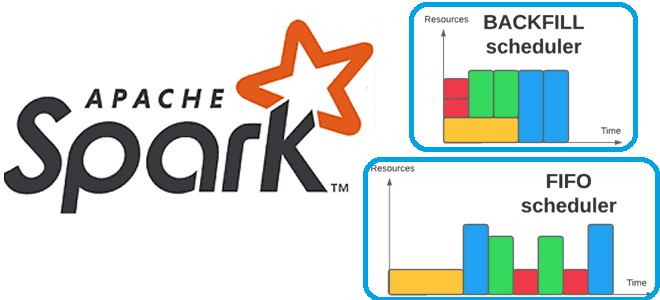
Что такое backfill-операции в конвейерах заданий Apache Spark, чем они отличаются от исторического заполнения датасетов, зачем их автоматизировать и как это сделать. Что такое backfilling для заданий Apache Spark Мы уже писали про понятие backfill на примере модификации DAG при добавлении новых заданий в конвейер Apache AirFlow. Эта функция полезна,...