
Чтобы сделать наши курсы по Apache NiFi Для дата-инженеров еще более полезными, сегодня поговорим про настройку процессоров. Читайте далее, как распараллелить задачи и потоки, задержать FlowFile, задать обратное давление и настроить другие полезные конфигурации.
Как настроить конфигурации процессора Apache NiFi
Будучи мощным инструментом дата-инженерии, Apache NiFi содержит множество обработчиков – процессоров, которые включают предварительно настроенные значения их конфигураций. Однако, чтобы повысить эффективность работы этих процессоров, рекомендуется донастраивать их согласно особенностям своего варианта использования. О некоторых настройках мы уже писали здесь, а какие-то сегодня рассмотрим впервые.
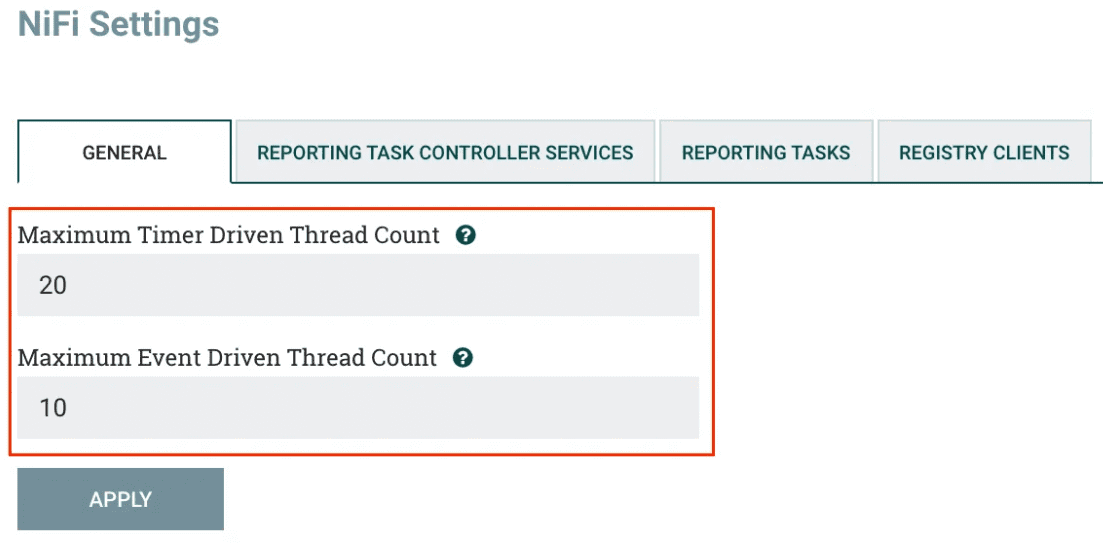
Но перед тем как переходить к конфигурированию процессора, проверим общие настройки фреймворка. В настройках контроллера потока, который предлагает потоки для запуска расширений и управляет расписанием, когда они получают ресурсы для запуска, следует убедиться, что имеется достаточно потоков для настроенных уровней параллелизма (потоков) для всех процессоров и групп процессов. Экземпляр NiFi должен иметь доступ к достаточному количеству ядер ЦП для выделенных потоков.
Поскольку работа с NiFi полностью выполняется в GUI, настройка процессора также происходит в визуальном режиме. Чтобы настроить процессор, его следует сперва перенести на область холста, а затем открыть окно свойств через клик правой кнопкой или двойной щелчок левой кнопкой мыши. Откроется диалоговое окно конфигурации с четырьмя различными вкладками, которые мы рассмотрим далее. После завершения настройки процессора можно применить или отменить сделанные изменения. Настройка процессора возможна только если он не находится в состоянии работы. Поэтому перед тем, как настраивать процессор, его следует остановить и дождаться завершения всех его активных задач.
Из множества параметров конфигурации процессора наиболее важными для его настройки считаются следующие:
- количество одновременно выполняемых задач и потоков;
- интервал расписания запуска;
- длительность штрафа и временной остановки;
- настройки соединения и обратного давления для регулирования скорости работы продюсера, чтобы соотносить ее со скоростью работы потребителя, чтобы быстрый продюсер не переполнил буфер потребителя и не исчерпал его оперативную память.
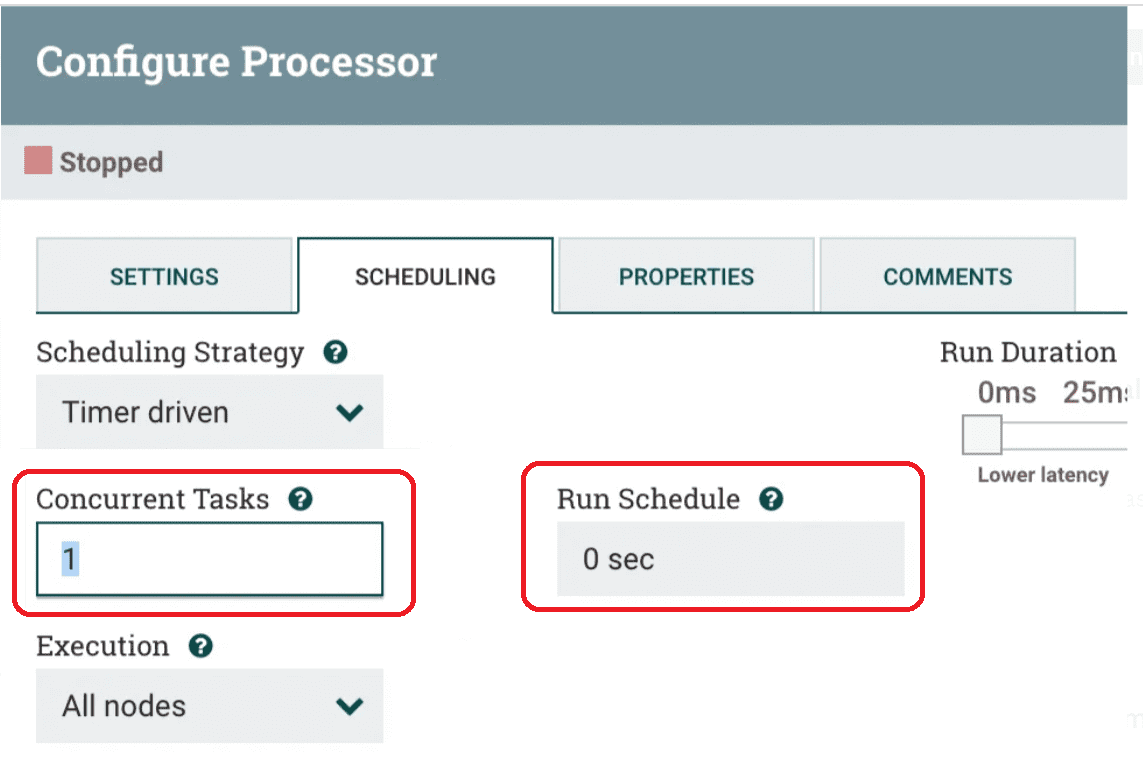
По умолчанию количество параллельно выполняемых задач (параметр Concurrent Tasks) в процессоре NiFi равно 1. Можно вручную увеличить количество потоков, запрошенных для параллельной обработки потоковых файлов. Фреймворк попытается выделить новое количество потоков, если оно доступно. Параметр Concurrent Tasks определяет, сколько FlowFile должно обрабатываться этим процессором одновременно. Увеличение этого значения обычно позволяет процессору обрабатывать больше данных за то же время за счет потребления системных ресурсов, которые не могут использоваться другими процессорами. По сути, так можно задать относительный вес процессора, определив, какая часть системных ресурсов должна быть выделена ему, а не другим. Это поле доступно для большинства процессоров. Но есть некоторые типы процессоров, которые можно запланировать только с одной параллельной задачей.
Всего возможны три режима планирования, т.е. варианта управления запуском процессора:
- Управление по таймеру (по умолчанию) — процессор будет запускаться через регулярные промежутки времени, заданные параметром Run Schedule;
- Управление по событиям — процессор будет запускаться по событию, которое происходит, когда FlowFile входит во входящие соединения процессора. Этот режим пока еще считается экспериментальным и поддерживается не всеми процессорами. Когда выбран этот режим, параметр Run Schedule не настраивается, так как процессор запускается не периодически, а в результате события. Кроме того, это единственный режим, для которого параметр Concurrent Tasks может быть установлен на 0. В этом случае количество потоков ограничено только размером управляемого событиями пула потоков, настроенного администратором.
- Управление с помощью CRON — процессор запускается периодически, аналогично режиму планирования, управляемому таймером. Однако CRON-режим намного гибче за счет увеличения сложности конфигурации. Значение планирования, управляемое CRON, представляет собой строку из шести обязательных полей и одного необязательного поля, каждое из которых разделено пробелом.
Интервал времени между двумя запусками процессора (параметр Run Schedule) изначально равен 0, что предполагает отсутствие задержки между выполнениями. Иногда рекомендуется специально ввести эту задержку, в зависимости от назначения процессора. Например, процессор ConsumeKafkaRecord, который потребляет записи из топиков Apache Kafka, может получить за один pull-вызов целый пакет записей, чтобы не создавать лишнюю нагрузку на сеть из-за постоянной работы вследствие непрерывных запусков.
Параметр Execution используется для определения, на каком узле будет запланировано выполнение процессора. Выбор всех узлов (All nodes) приведет к тому, что процессор будет запланирован на каждом узле в кластере Apache NiFi. Процессоры, которые были настроены для выполнения на главном узле (Primary Node), обозначаются буквой «P» рядом со значком процессора.
Также можно задать параметр длительности выполнения (Run Duration), который определяет задержку запуска процессора. Когда процессор завершает работу, он должен обновить репозиторий, чтобы передать потоковые файлы следующему соединению. Это довольно ресурсоемкая операция: следующий Процессор не может начать обработку потоковых файлов до тех пор, пока предыдущий Процесс не обновит репозиторий. В результате возрастет задержка — время, необходимое для обработки FlowFile от начала до конца. В настройках процессора можно выбрать более низкую задержку или более высокую пропускную способность.
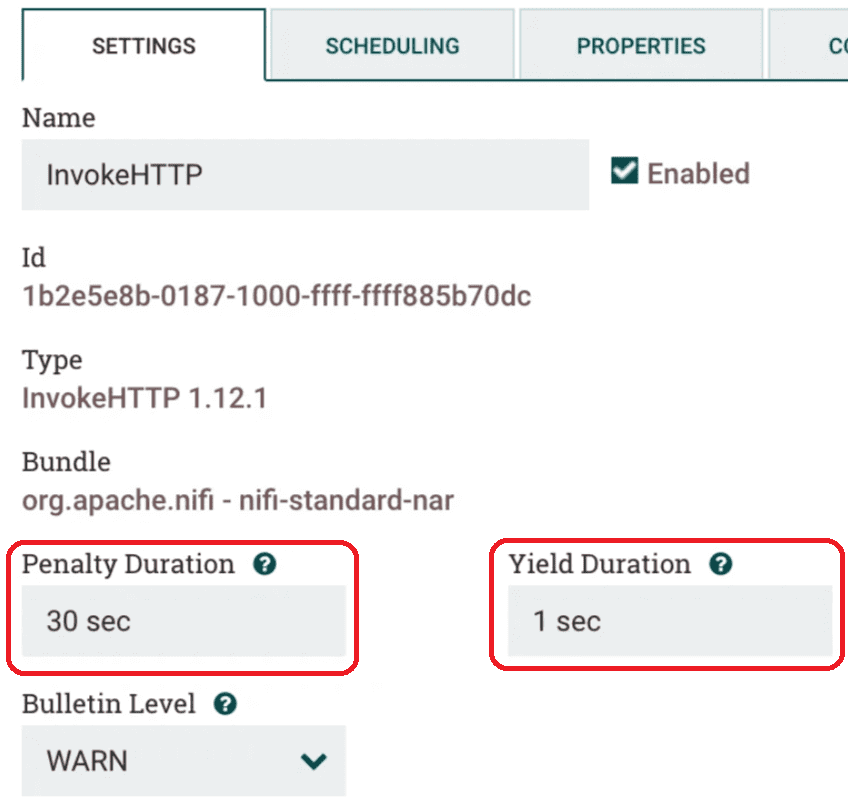
В общих настройках процессора задается его поведение, если он не успел успешно обработать потоковый файл. Напомним, в Apache NiFi к FlowFile применяется концепция штрафа, если он не был успешно обработан. При наложении штрафа FlowFile не появляется в нисходящей очереди в течение штрафного периода времени (Penalty Duration, по умолчанию 30 секунд). Если процессор не может успешно обработать потоковый файл, и надо временно прекратить его работу, используется параметр Yield Duration.
Настроить такое поведение процессора полезно, например, если InvokeHTTP Processor отправляет сообщения на сервер API, получая сообщения из топика Kafka. Сервер API, к которому обращается процессор InvokeHTTP, может быть временно недоступен или перегружен, поэтому процессор должен отключиться на фиксированный интервал времени, а затем повторить попытку.
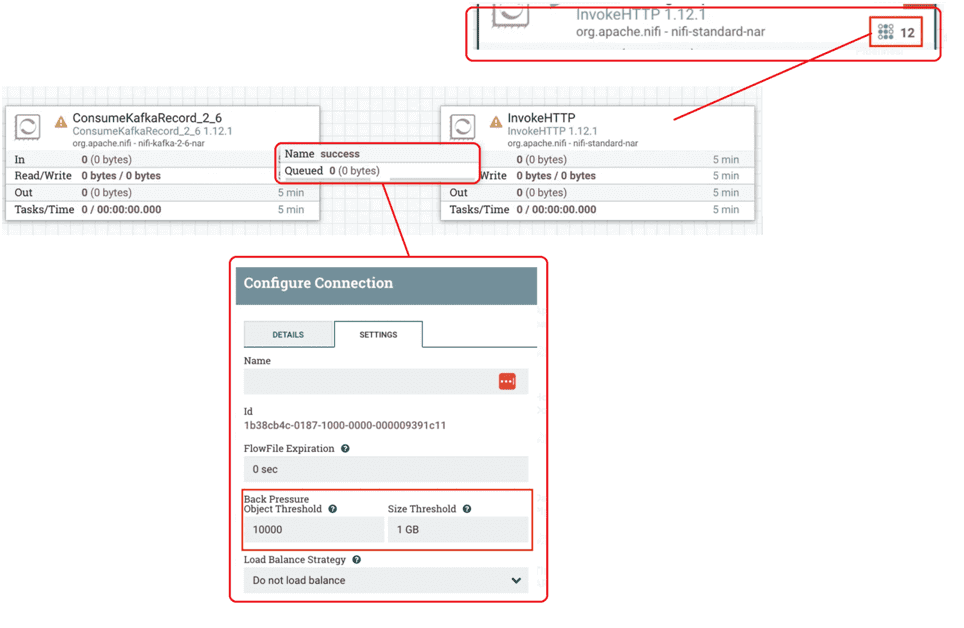
Наконец, следует точно настроить параметры обратного давления, чтобы не перегружать оперативную память, необходимую NiFi для хранения потоковых файлов, которые в данный момент обрабатываются. К примеру, сообщения в топике Kafka перехватываются процессором InvokeHTTP для вызова конечной точки API и следует определить конфигурации для соединения (очереди) отношения успеха. По умолчанию количество потоковых файлов, которые могут храниться в очереди, равно 10000. Когда их становится больше, вышестоящий процессор не будет запускаться. Также можно определить порог размера всех объектов или потоковых файлов, находящихся в очереди (по умолчанию 1 ГБ).
Данные конфигурации важно настроить в случаях работы с Apache Kafka или другим брокером сообщений, поступающих в режиме (почти) реального времени. Например, когда процессор, подобный ConsumeKafka, слишком быстро помещает сообщения в очередь, а нисходящий процессор типа InvokeHTTP обрабатывает их с более низкой скоростью. Это приводит к нежелательному использованию оперативной памяти для хранения потоковых файлов в очереди, тогда как можно просто потребить сообщения из Kafka чуть позже. Найти оптимальное значение этого параметра поможет наблюдение за количеством потоков, которое отображается в строке заголовка процессора. Если настроенное количество потоков отсутствует или меньше, то нижестоящий процессор используется недостаточно эффективно и может быть загружен больше. О других процессорах Apache NiFi, которые можно использовать для работы с HTTP-запросами, читайте в нашей новой статье.
Как эффективно использовать Apache NiFi для построения эффективных ETL-конвейеров потоковой аналитики больших данных, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

