Что такое backfill-операции в конвейерах заданий Apache Spark, чем они отличаются от исторического заполнения датасетов, зачем их автоматизировать и как это сделать.
Что такое backfilling для заданий Apache Spark
Мы уже писали про понятие backfill на примере модификации DAG при добавлении новых заданий в конвейер Apache AirFlow. Эта функция полезна, если дата-инженеру нужно выполнить отдельную задачу в DAG за предыдущий период. Для этого в Apache AirFlow есть функция backfill, которая повторно запускает все экземпляры dag_id для всех интервалов в пределах указанных дат начала и окончания. Аналогичная возможность существует и для Spark-заданий, чтобы заполнить исторические данные для прошлых периодов. Такое заполнение исторических данных позволяет повысить точность предупреждений за счет учета сезонности данных, уменьшая количество ложноотрицательных и ложноположительных результатов.
На практике это полезно при прогнозировании событий, например, в ритейле, где данные во время распродаж могут сильно отличаться от привычных значений. В частности, черная пятница может показаться огромной аномалией, если сравнивать ее с данными за пару последних недель. Поэтому для среднесрочного и стратегического прогнозирования важно глубоко изучить прошлые данные, чтобы получить максимально точные результаты. Такое заполнение прошлого периода называется backfilling. При работе с данными временных рядов и ML-проектами дата-инженеру достаточно часто приходится выполнять backfill-операции. Для пакетных конвейеров с небольшим объемом данных, ручное выполнение backfill-операций не проблема. Однако, когда объем данных становится большим и включает потребительские транзакции, геолокации, данные о социальных настроениях, показания датчиков и пр., backfilling становится утомительным процессом, который может дать сбой.
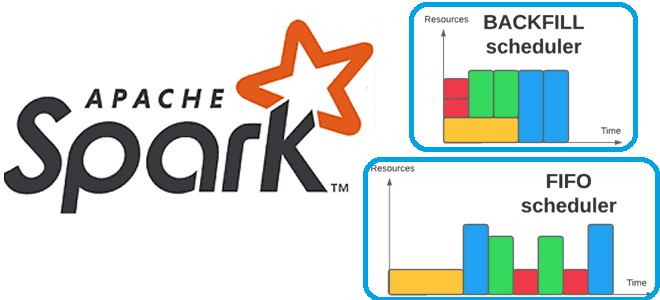
В кластерной среде распределенных вычислений понятие backfilling также означает механизм, с помощью которого задание с более низким приоритетом может быть запущено раньше задания с более высоким приоритетом, чтобы заполнить пробелы планирования и увеличить пропускную способность кластера. Польза от такого backfilling-запуска обратно пропорциональна времени выполнения задания, запускаемого вперед. Но если задание достигает ограничения по времени, оно будет уничтожено системой очередей.
По умолчанию планировщик Spark запускает задания в порядке FIFO (first In First Out). Каждое задание разделено на этапы, и первое задание получает приоритет по всем доступным ресурсам, пока на его этапах есть задачи для запуска. Затем приоритет получает второе задание и т.д. Если заданию во главе очереди не нужно использовать весь кластер, более поздние задания могут начать выполняться сразу, но если задания в начале очереди большие, то более поздние задания могут быть значительно задержаны. Подробнее про задания, этапы и задачи Spark мы писали здесь.
Автоматизация backfill-операций
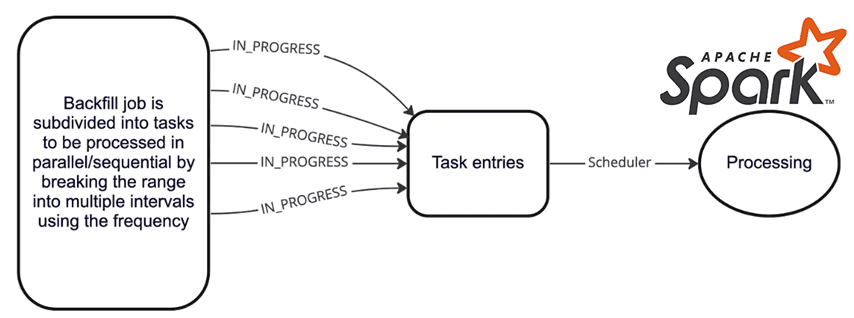
Таким образом, backfilling в кластерной среде можно рассматривать как способ ручного повышения эффективности эксплуатации программно-аппаратных ресурсов. Чтобы backfilling не влиял на другие производственные задания, можно добавить больше ресурсов в кластер. Но для этого потребуется несколько развертываний, настройка конфигураций кластера, а также постоянное ручное вмешательство. Автоматизировать процесс заполнения исторических данных для заданий Apache Spark можно, написав код, который будет передать скрипту запуска в кластере spark-submit исторические данные в виде конфигураций или аргументов командной строки. Как правило, при выполнении в кластере Spark-задание включает несколько задач, количественные значения прочитанных и записанных данных, потребление ресурсов на исполнителях и прочие конфигурации. Представим пример этих параметров в виде JSON-документа:
{
"numTasks": 4,
"executorRunTime": 8330776,
"executorCpuTime": 2907711,
"executorDeserializeTime": 249602,
"executorDeserializeCpuTime": 85655,
"resultSerializationTime": 1358,
"jvmGCTime": 290321,
"shuffleFetchWaitTime": 0,
"shuffleWriteTime": 18454,
"resultSize": 14042307,
"diskBytesSpilled": 0,
"memoryBytesSpilled": 0,
"peakExecutionMemory": 524288,
"recordsRead": 4124000,
"bytesRead": 197579349171,
"recordsWritten": 0,
"bytesWritten": 0,
"shuffleTotalBytesRead": 0,
"shuffleTotalBlocksFetched": 0,
"shuffleLocalBlocksFetched": 0,
"shuffleRemoteBlocksFetched": 0,
"shuffleBytesWritten": 3948635554,
"shuffleRecordsWritten": 4124000
}
При этом следует определить наиболее оптимальный период выполнения backfill-заданий, чтобы не запускать их слишком часто. Определить оптимальный частотный диапазон поможет функция под названием формат записи noop, впервые появившаяся в Spark 3.0. При ее вызове Spark выполнит запрос и все его преобразования, но никуда не запишет результат, позволяя протестировать задание без дополнительных затрат на запись вывода на диск.
(
df
.write
.mode("overwrite")
.format("noop")
.save()
)
Освойте тонкости применения Apache Spark для разработки приложений аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Потоковая обработка в Apache Spark
- Анализ данных с Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источники

