 1556
1556 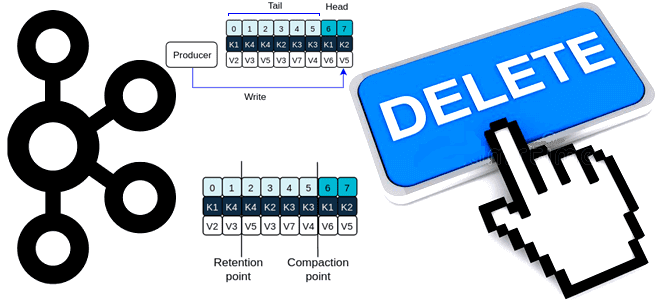
Почему в Apache Kafka нет функций очистки топика и как же все-таки удалить из него все сообщения, если очень нужно, используя конфигурации retention и другие приемы администрирования кластера.
Политика очистки и конфигурации retention
В отличие от брокеров сообщений, которые после отправки данных приложениям-потребителям, удаляют их из очереди, Apache Kafka хранит сообщения, опубликованные в топике до тех пор, пока не сработает политика очистки. Однако, при разработке и отладке потокового конвейера дата-инженеру необходимо полностью очистить топик. Это можно сделать 2-мя способами:
- установить период хранения на очень малое время, например, пара миллисекунд;
- удалить топик и создать заново.
Напомним, топик в Apache Kafka представляет собой не физическое, а логическое хранение данных, которое делится на разделы, состоящие из сегментов. Сообщение, опубликованное приложением-продюсером в топик Kafka, добавляется в конец лога и остается в нем, пока не будет достигнут предельный размер лога или не наступит время его сжатия/удаления согласно политике очистки, заданной в конфигурации log.cleanup.policy. За время хранения сообщений в логе до того, как сработает политика его очистки, отвечает конфигурация log.retention, которую можно определить в часах, минутах или миллисекундах. По умолчанию сегменты лога хранятся неделю, однако это можно настроить на более длинный срок, используя многоуровневое хранилище с разделением локального и удаленного уровней. Как это сделать, читайте в нашей новой статье.
Таким образом, удалить все сообщения из топика Kafka, можно, поиграв с настройками конфигураций. При этом придется выполнить целый ряд действий:
- установить политику очистки в режим удаления, задав конфигурации log.cleanup.policy значение delete (log.cleanup.policy=delete);
- установить миллисекундный срок хранения сообщений в топике с помощью конфигурации log.retention.ms;
- альтернативой предыдущему шагу может стать установка конфигурации bytes в минимальное значение, например, пара байтов. Этот параметр определяет максимально допустимый размер лога для раздела топика. Когда размер лог достигает этого предела, начинается удаление сегментов с конца.
После того, как политика очистки лога сработает, удалив старые сообщения, можно снова изменить значения конфигураций retention для перехода от режима отладки к производственному развертыванию.
Пересоздание топика Kafka
Если не хочется возиться с конфигурациями, можно просто удалить топик и создать его заново. Однако, этот метод имеет некоторые оговорки. Во-первых, удаление не происходит мгновенно, придется немного подождать. Во-вторых, пересоздание топика предполагает пересоздания всех его разделов, в т.ч. на которые подписаны приложения-потребители. Клиентам придется повторно подключаться к Kafka. Если приложения-потребители входят в конвейер обработки данных, т.е. имеют нижестоящих потребителей, возникнут ошибки во всем конвейере.
Для того, чтобы топик можно было удалить, конфигурация delete.topic.enable должна иметь значение true. По умолчанию это так и есть. Если эта конфигурация отключена, т.е. установлена в значение false, удаление топика будет невозможно даже через инструмент администратора.
Что касается создания топика, для этого тоже есть конфигурация — topic.creation.enable. По умолчанию установленная в значение true, она разрешает автоматическое создание топиков, используемых коннекторами источников данных, когда они настроены со свойствами topic.creation. Каждая задача будет использовать клиент администрирования для создания своих топиков вне зависимости от брокеров Kafka для автоматического создания топиков. За автоматическое создание топика на сервере отвечает конфигурация auto.create.topics.enable, по умолчанию установленная в значение true.
Впрочем, иногда бывает полезно отключить эту функцию, как и возможность создания топиков для обычных пользователей, запретив это с помощью ACL-списков, разрешив создавать топики от имени пользователя через скрипты или другие инструменты автоматизации рутинных задач. Подробнее про удаление топика в производственной среде читайте в новой статье.
Освойте администрирование и эксплуатацию Apache Kafka для потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

