
Что такое квоты в Apache Kafka и как этот механизм позволяет управлять ресурсами брокера, предупреждая DDOS-атаки от слишком активных потребителей и продюсеров. Разбираемся с типами клиентских квот, их конфигурациями и принципами работы. Квоты клиента и пользователя в Apache Kafka Чтобы управлять ресурсами брокера, кластер Kafka может применять квоты на запросы...

14 августа 2023 года вышел очередной релиз Apache AirFlow . Разбираем его самые главные новые возможности, улучшения и исправления ошибок: отказ от Python 3.7, задачи установки/демонтажа, встроенная поддержка спецификации OpenLineage, обновления интерфейса, упрощение управления сложными зависимостями и другие фичи Apache AirFlow 2.7. Задачи установки/демонтажа Apache AirFlow 2.7 содержит более 35...

Сегодня рассмотрим, какие системные метрики Greenplum необходимо отслеживать администратору кластера и дата-инженеру для оценки работоспособности и эффективности этой СУБД, а также с помощью каких инструментов это сделать. Мониторинг средствами Greenplum Прежде всего, стоит отметить, что контролировать Greenplum можно с помощью различных инструментов, включенных в систему или доступных в качестве надстроек....
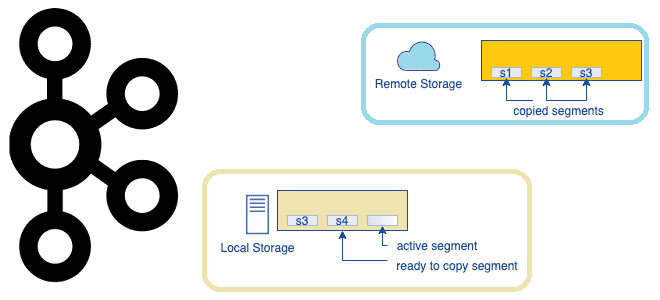
Что представляет собой очередное предложение по улучшению проекта Apache Kafka, которое расширяет возможности этой распределенной платформы потоковой передачи событий, превращая ее в средство долговременного хранения данных. Надежность vs скорость: вечный компромисс в Apache Kafka Изначально Apache Kafka позиционировалась как middleware, т.е. сервисный слой для асинхронной интеграции нескольких информационных систем. Этот...
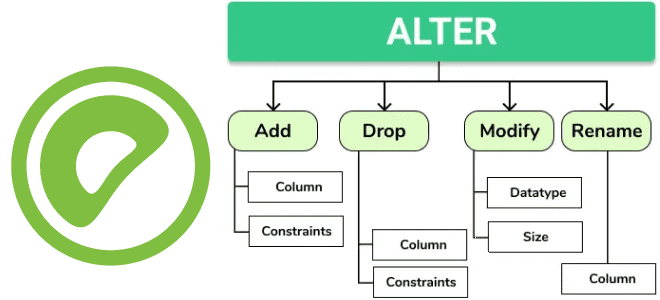
Какие команды изменения таблиц добавлены в 7-ю версию Greenplum и чем они полезны дата-инженеру. Разбираемся с новыми функциями: как добавить столбец, изменить его тип, кодировку хранения и перезаписать несколько таблиц одной командой. Добавление столбца О новых функциях работы с партиционированаными таблицами в Greenplum 7 мы уже писали. В частности, Greenplum...

Что такое кластеризация с нулевым лидером, чем координатор отличается от основного узла, каким образом устроен механизм выбора лидера, зачем нужна изоляция процессоров и как ее реализовать, а также другие особенности кластера Apache NiFi. Ключевые компоненты кластера Apache NiFi Хотя Apache NiFi можно запустить на локальной машине, чтобы он выполнялся как...

Зачем биомедикам понадобился свой язык описания онтологий, как эти задачи решает BioCypher и при чем здесь Neo4j: практическое приложение Data Science и графовых алгоритмов в биомедицинской сфере. Что такое BioCypher Графовые алгоритмы активно применяются в биомедицине для анализа различных биологических данных, таких как геномные, протеомные, данные о белковых взаимодействиях и...

Как расширить возможности MPP-СУБД Greenplum, используя фоновые рабочие процессы и почему это небезопасно. А также рассмотрим, что такое API Greenplum Partner Connector и как это использовать. Фоновые рабочие процессы Обычно фоновыми процессами в СУБД называются системные задания, которые запускаются при запуске базы данных и выполняют различные служебные задачи. К таким рутинным сервисным задачам...

Сегодня заглянем внутрь Neo4j, чтобы разобраться с базовыми концепциями этой графовой базы данных. Какие уровни изоляции транзакций поддерживаются в Neo4j, почему одна установка по умолчанию содержит две базы данных, что такое составная БД и как с этим работать. Транзакции в Neo4j Neo4j — это популярная нативная графовая СУБД, способная управлять...
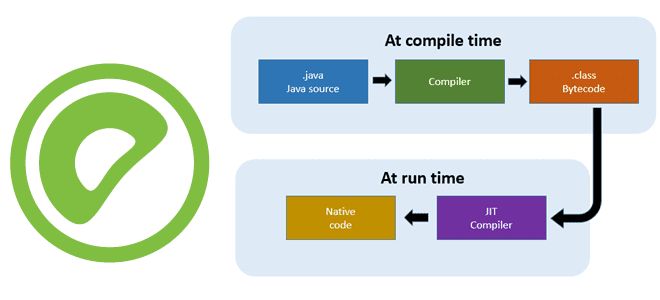
Чтобы SQL-запросы выполнялись быстрее, в Greenplum, как и в PostgreSQL, поддерживается JIT-компиляция. Читайте далее, что это такое и всегда ли эта динамическая генерация машинного кода на лету дает выигрыш в скорости для аналитики больших данных. Что такое JIT-компиляция Технология JIT-компиляции (Just-In-Time) позволяет генерировать машинный код во время выполнения программы. В...