
Продолжая разговор о том, как выбрать курсы по Kafka и другим технологиям больших данных (Big Data), сегодня рассмотрим, кому и в каких случаях нужно такое повышение квалификации. В этой статье мы собрали для вас 5 прикладных кейсов по Кафка для ИТ-профессионалов разных специальностей, от системного администратора до Data Engineer’а. А...

Продолжая разговор про примеры практического использования Apache Cassandra в реальных Big Data проектах, сегодня мы расскажем вам о рекомендательной системе стримингового сервиса Spotify на базе этой нереляционной СУБД в сочетании с другими технологиями больших данных: Kafka, Storm, Crunch и HDFS. Рекомендательная система Spotify: зачем она нужна и что должна делать...

Благодаря быстроте, надежности и другим достоинствам Apache Cassandra, эта распределенная NoSQL-СУБД широко применяется во многих Big Data проектах по всему миру. В этой статье мы собрали для вас несколько интересных примеров реального использования Кассандры в 5 ключевых направлениях современного ИТ. Где используется Apache Cassandra: 5 главных приложений c примерами Промышленные...
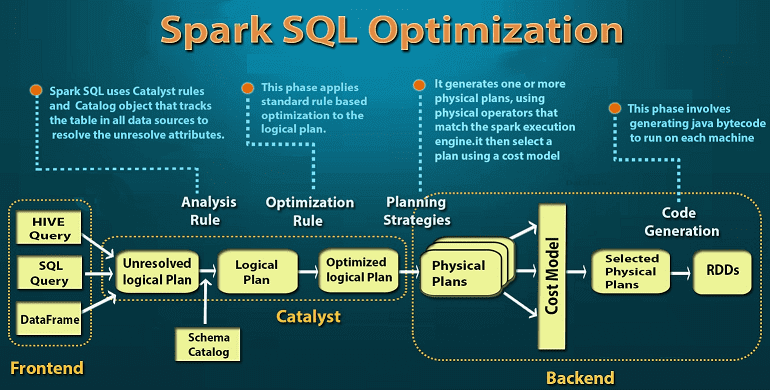
Завершая тему SQL-оптимизации в Big Data на примере Apache Spark, сегодня мы подробнее расскажем, какие действия выполняются на каждом этапе преобразования дерева запросов в исполняемый код. А рассмотрим, за счет чего так эффективна автоматическая кодогенерация в Catalyst. Читайте в нашей статье про планы выполнения запросов, квазиквоты Scala и операции с...
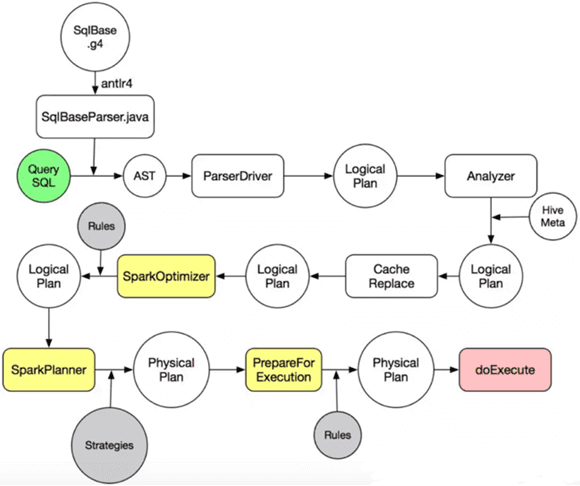
Продолжая разговор про SQL-оптимизацию в Apache Spark, сегодня мы рассмотрим, что такое дерево запросов и как оптимизатор Catalyst преобразует его в исполняемый байт-код при аналитической обработке Big Data в рамках Спарк. Деревья структурированных запросов и правила управления ими в Apache Spark Отметим, что деревья запросов отличаются от алгебраических деревьев операций тем, что...
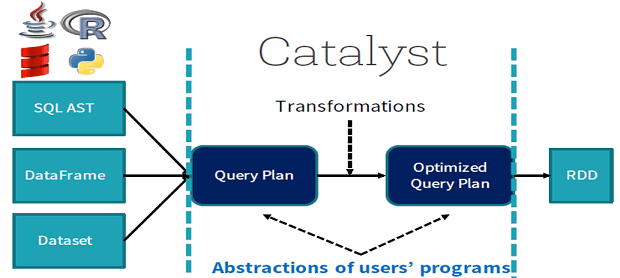
Мы уже немного рассказывали об SQL-оптимизации в Apache Spark. Продолжая эту тему, сегодня рассмотрим подробнее, что такое Catalyst – встроенный оптимизатор структурированных запросов в Spark SQL, а также поговорим про базовые понятия SQL-оптимизации. Читайте в нашей статье о логической и физической оптимизации, плане выполнения запросов и зачем эти концепции нужны...
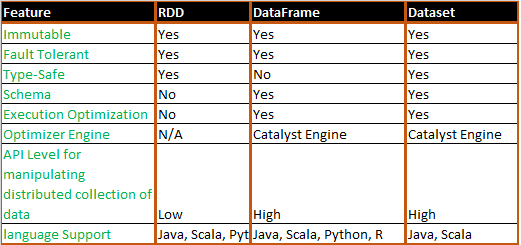
Завершая сравнение структур данных Apache Spark, сегодня мы рассмотрим, в каких случаях разработчику Big Data стоит выбирать датафрейм (DataFrame), датасет (DataSet) или RDD и почему. Также мы приведем практический примеры и сценарии использования (use cases) этих программных абстракций, важных при разработке систем и сервисов по интерактивной аналитике больших данных с...
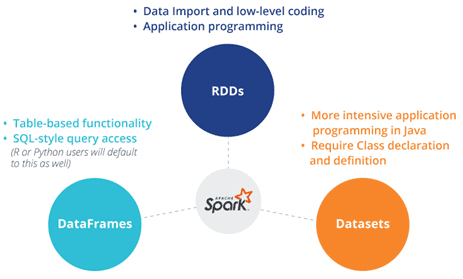
Продолжая говорить о сходствах и отличиях структур данных Apache Spark, сегодня мы рассмотрим, чем похожи датафрейм (DataFrame), датасет (DataSet) и RDD с позиции разработчика Big Data. Читайте в нашей статье, как обеспечивается оптимизация кода, безопасность типов при компиляции и прочие аспекты, важные при разработке распределенных программ и интерактивной аналитике больших...
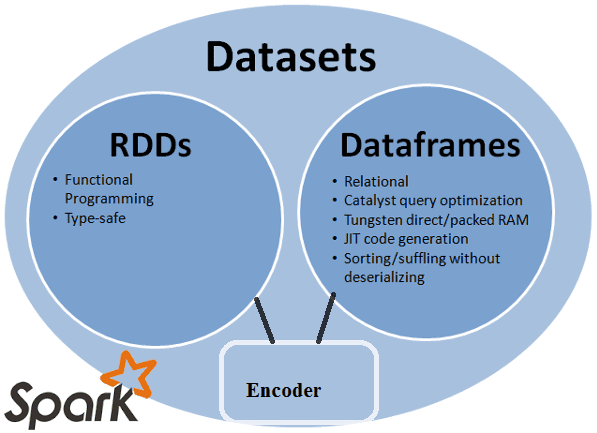
В прошлый раз мы рассмотрели понятия датафрейм (DataFrame), датасет (DataSet) и RDD в контексте интерактивной аналитики больших данных (Big Data) с помощью Spark SQL. Сегодня поговорим подробнее, чем отличаются эти структуры данных, сравнив их по разным характеристикам: от времени возникновения до специфики вычислений. Критерии сравнения структур данных Apache Spark Прежде...
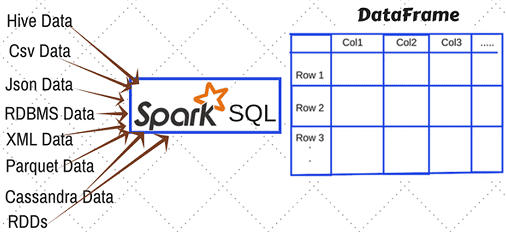
Этой статьей мы открываем цикл публикаций по аналитике больших данных (Big Data) с помощью SQL-инструментов: Apache Impala, Spark SQL, KSQL, Drill, Phoenix и других средств работы с реляционными базами данных и нереляционными хранилищами информации. Начнем со Spark SQL: сегодня мы рассмотрим, какие структуры данных можно анализировать с его помощью и...