 991
991 
Содержание
Продолжая разговор о том, как выбрать курсы по Kafka и другим технологиям больших данных (Big Data), сегодня рассмотрим, кому и в каких случаях нужно такое повышение квалификации. В этой статье мы собрали для вас 5 прикладных кейсов по Кафка для ИТ-профессионалов разных специальностей, от системного администратора до Data Engineer’а. А о том, почему корпоративное обучение большим данным эффективнее индивидуальных курсов, мы рассказываем здесь.
Что такое Apache Kafka и зачем она нужна в Big Data
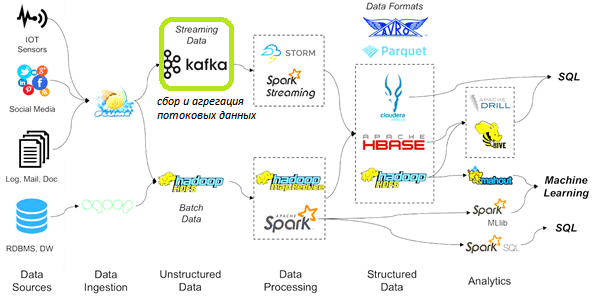
Напомним, что такое Кафка и какова роль этой технологии в общем ландшафте Big Data решений. Apache Kafka – это реплицированный журнал сообщений в виде распределённой, горизонтально масштабируемой Big Data системы. Она используется для централизованного сбора, передачи и непрерывной потоковой обработки большого количества сообщений из различных источников: распределенные файловые системы (HDFS, Amazon S3), устройства интернета вещей (Internet of Things, IoT), в т.ч. промышленного (Industrial IoT, IIoT), журналы информационных систем, логи пользовательского поведения на сайтах и в соцсетях и пр. Подробнее о примерах практического использования Apache Kafka мы писали здесь.
Благодаря своей высокой пропускной способности и сохранению информации на диске, Кафка выгодно отличается от другого популярного брокера сообщений, RabbitMQ. Вместе с автоматической балансировкой кластерной нагрузки и горизонтальной масштабируемостью, это обусловливает широкое распространение Кафка во многих Big Data и IoT/IIoT-проектах. О дилемме Kafka vs RabbitMQ, анализируя сходства и различия этих систем управления очередями сообщений, мы рассказывали в этой статье.
Наличие клиентской библиотеки Kafka Streams позволяет разрабатывать распределенные приложения и микросервисы для Big Data и IoT/IIoT-систем, в которых входные и выходные данные хранятся в кластерах Кафка. А ее интерфейс программирования, API Kafka Streams, доступный через библиотеку Java, позволяет упростить процесс разработки и развертывания в соответствии с DevOps-подходом. Тому, как эффективно обрабатывать большие данные в реальном времени, без использования дополнительных инструментов, таких как Apache Spark, Storm или Flink, с помощью API Kafka Streams, мы посвятили отдельную публикацию.
Впрочем, Кафка отлично интегрируется и с другими Big Data системами, например, через службу синхронизации Apache Zookeeper или путем непосредственной передачи данных за счет отслеживания смещений в разделах (partition) топика (topic) по контрольным точкам (checkpoints). Как это работает, читайте тут.
Таким образом, можно сделать вывод, что Apache Kafka является широко распространенным средством для построения масштабных Big Data и IoT/IIoT-систем, обеспечивая непрерывный сбор и агрегацию первичных данных из разных источников в режиме реального времени. Наряду с Apache Hadoop и Spark это брокер сообщений позволяет построить конвейер данных (Data Pipeline), чтобы с помощью алгоритмов машинного обучения (Machine Learning) извлекать из «сырой информации» сведения, ценные для бизнеса. Или можно использовать подобный конвейер для построения рекомендательных систем, как это делает стриминговый сервис Spotify, о чем мы рассказывали здесь. В общем, Apache Kafka применяется для распределенной агрегации и онлайн-обработки потоковых данных в разных задачах по цифровизации промышленных предприятий и коммерческих бизнес-кейсах, от маркетинга до анализа биржевых операций.
Кто и как в ИТ использует Кафка: практические примеры
Вышеописанные достоинства и примеры использования Apache Kafka позволяют выделить 5 основных кейсов практического применения этой Big Data системы. Итак, обучающие курсы по Кафка нужны следующим ИТ-специалистам:
- системный администратор локального или облачного кластера Apache Kafka, который отвечает за установку, настройку, конфигурирование и поддержку Big Data системы, обеспечивает защиту хранящихся данных с помощью безопасного шифрования, аутентификации и авторизации, а также работает со службой централизации распределенных сервисов Zookeeper;
- DevOps-инженер, который разрабатывает и разворачивает Docker- или Kubernetes-контейнеры распределенных приложений на базе Кафка;
- разработчик Big Data сервисов, использующий Кафка для обработки пользовательских и системных событий в режиме реального времени;
- программист IoT/IIoT-решений, которому необходимо обеспечить непрерывный сбор и агрегацию «сырых данных» (raw data) от технологического оборудования;
- инженер данных (Data Engineer), ответственный за построение информационных конвейеров (data pipeline) в рамках интеграции корпоративных информационных систем или организации ETL-процессов для задач Business Intelligence.

Для этих ИТ-специалистов, а также менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data наш лицензированный учебный центр «Школа Больших Данных» предлагает уникальные практические курсы обучения по Kafka и другим технологиям больших данных (Apache Hadoop, Spark, HBase, Arenadata, Cloudera Impala) в Москве:

