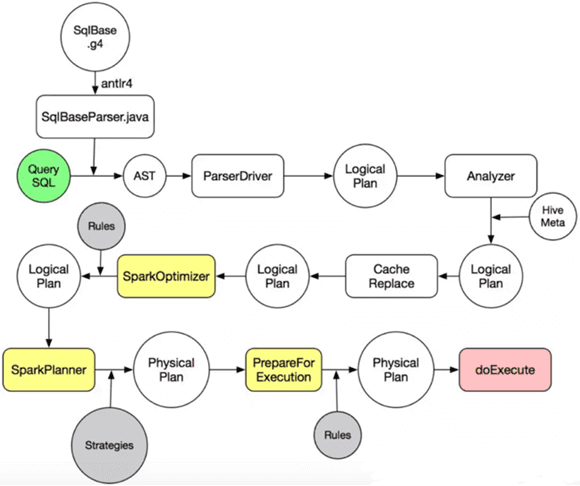
Продолжая разговор про SQL-оптимизацию в Apache Spark, сегодня мы рассмотрим, что такое дерево запросов и как оптимизатор Catalyst преобразует его в исполняемый байт-код при аналитической обработке Big Data в рамках Спарк.
Деревья структурированных запросов и правила управления ими в Apache Spark
Отметим, что деревья запросов отличаются от алгебраических деревьев операций тем, что дерево запроса позволяет сохранить всю декларативность языка SQL. Дерево запроса превращается в дерево операций после физической оптимизации [1].
Дерево является основным типом данных в Catalyst. Дерево содержит объект узла, который может иметь один или нескольких дочерних элементов. Новые узлы определяются как подклассы класса TreeNode. Эти объекты неизменны по своей природе. Объектами можно управлять с помощью функционального преобразования.
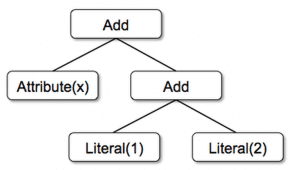
В качестве примера рассмотрим дерево из 3 классов узлов [2]:
- Literal(value: Int) – постоянное значение
- Attribute(name: String) – атрибут из входной строки, например, «x»
- Add(left: TreeNode, right: TreeNode) – сумма двух выражений.
Эти классы могут быть использованы для построения дерева, например, выражение для дерева x+(1+2), будет выглядеть на Scala таким образом: Add(Attribute(x), Add(Literal(1), Literal(2))).
Манипулировать деревом можно с помощью правил, определяя их как функцию от одного дерева к другому дереву. Правила позволяют запускать произвольный код на входном дереве, используя функцию сопоставления с образцом, и заменять поддерево определенной структурой. С помощью функции преобразования можно рекурсивно применить сопоставление с образцом ко всем узлам дерева. Таким образом, получается шаблон, который сопоставляет каждый образец с результатом [3].
В качестве еще одного примера рассмотрим правило, которое складывает операции добавления между константами следующим образом [2]:
tree.transform {
case Add(Literal(c1), Literal(c2)) => Literal(c1+c2)
}
Применение этого правила к дереву для x+(1+2) даст новое дерево x+3. Оператор case означает стандартный синтаксис сопоставления с образцом в Scala, который используется для сопоставления по типу объекта, а также для присвоения имен извлеченным значениям (c1 и c2). Выражение сопоставления с шаблоном, которое передается в преобразование, является частичной функцией, которая должна соответствовать только подмножеству всех возможных входных деревьев. Catalyst проверяет, к каким частям дерева применяется данное правило, автоматически пропуская несоответствующие деревья. Поэтому не стоит изменять правила, если в систему добавляются новые типы операторов. Правила и сопоставление с образцом в Scala могут сопоставлять несколько шаблонов в одном вызове преобразования, что упрощает выполнение нескольких преобразований одновременно [2]:
tree.transform {
case Add(Literal(c1), Literal(c2)) => Literal(c1+c2)
case Add(left, Literal(0)) => left
case Add(Literal(0), right) => right
}
На практике правила могут выполняться несколько раз, чтобы полностью преобразовать дерево. Catalyst группирует правила в пакеты и выполняет каждый из них до тех пор, пока дерево не перестанет меняться после применения своих правил. Запуск правил до этого момента означает, что каждое правило может быть простым и автономным, но, в конечном счете, будет оказывать глобальное влияние на дерево. В приведенном выше примере повторное применение будет постоянно огибать большие деревья, такие как (x+0)+(3+3). Более того, например, один пакет может анализировать выражение для назначения типов всем атрибутам, тогда как другой пакет может использовать эти типы для постоянного свертывания. После каждого пакета разработчик Big Data может проверить работоспособность в новом дереве с помощью рекурсивного сопоставления, в частности, чтобы увидеть, что все типы заданы для всех атрибутов [2].
Условия применения правил и они сами могут содержать произвольный код Scala. Это дает Catalyst больше возможностей, чем DSL-конструкции (Domain Specific Language) – языки, специфичные для предметной области, для оптимизаторов. При этом Catalyst сохраняет краткость для простых правил. Таким образом, функциональные преобразования в неизменяемых деревьях делают весь оптимизатор очень простым для анализа и отладки, включая распараллеливание [2], что присутствует в каждом Big Data проекте.
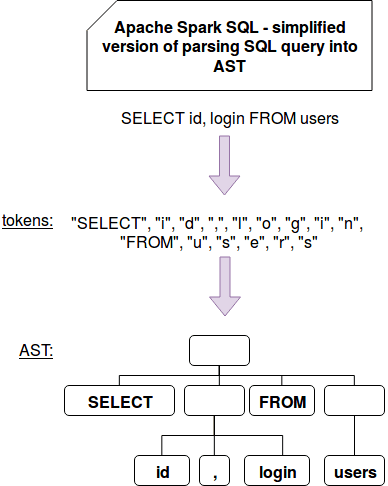
SQL-оптимизация в Apache Spark: как Catalyst преобразует дерево запросов в план выполнения
Дерево запросов появляется на этапе построения оптимизированного логического плана при SQL-оптимизации в Apache Spark с помощью Catalyst. Напомним, план выполнения запроса – это последовательность операций, необходимых для получения его результата. Обычно план SQL-запроса составляется в 2 этапа [4]:
- выборка с помощью вложенных итеративных циклов поиска данных в каждой из объединяемых таблиц и их слияния, если они имеют индексы по сравниваемым полям;
- сортировка и группировка, если не найдено путей доступа для получения результата в запрошенном порядке, а также выполнение агрегаций.
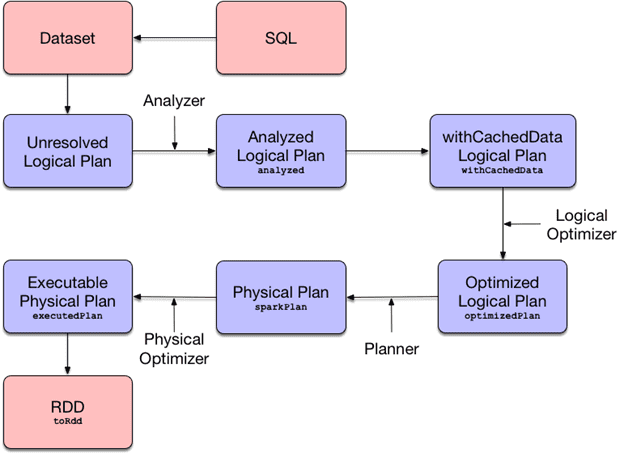
В процессе SQL-оптимизации запрос преобразуется в абстрактное синтаксическое дерево (AST, Abstract Syntax Tree), которое используется в парсерах для промежуточного представления программы между деревом разбора (конкретным синтаксическим деревом) и структурой данных, которая затем используется в качестве внутреннего представления в компиляторе или интерпретаторе для оптимизации и генерации программного кода. Возможные варианты подобных структур описываются абстрактным синтаксисом [5]. Пока SQL-запрос трансформируется в AST, план запросов при этом последовательно меняет свои состояния [6]:
- разобранный логически план (Parsed Logical Plan), который получается после синтаксического разбора SQL, когда проверяется только синтаксическая корректность запроса;
- проанализированный логический план (Analyzed Logical Plan), когда добавляется информация о структуре используемых сущностей, проверяется соответствие структуры и запрашиваемых атрибутов;
- оптимизированный логический план (Optimized Logical Plan), когда происходит преобразование получившегося дерева запроса на основании доступных правил оптимизации;
- физический план (Physical Plan), когда начинают учитываться особенности доступа к исходным данным, включая оптимизации по фильтрации разделов (partition) и данных для минимизации получаемого информационного набора. Здесь выбирается одна из возможных стратегия объединения (join).
Чтение плана выполнения запроса обычно происходит по нарастающей, т.е. сначала выполняются вложенные части, постепенно продвигаясь к итоговой проекции, расположенной на самом верху [6].
Подробнее о каждом из 4-х этапов преобразования SQL-запросов в Apache Spark SQL с помощью Catalyst читайте в нашей следующей статье. Об улучшениях оптимизатора Catalyst в рамках проекта Radiant мы рассказываем здесь.
Узнайте больше подробностей эксплуатации Apache Spark для разработки распределенных приложений и аналитики больших данных вам помогут узнать специализированные курсы в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источники
- http://citforum.ru/database/oracle/cost-based_query_tr/2.shtml
- https://databricks.com/blog/2015/04/13/deep-dive-into-spark-sqls-catalyst-optimizer.html
- https://data-flair.training/blog/spark-sql-optimization/
- https://ru.wikipedia.org/wiki/План_выполнения_запроса
- https://ru.wikipedia.org/wiki/Абстрактное_синтаксическое_дерево
- https://habr.com/ru/company/neoflex/blog/417103/

