 831
831 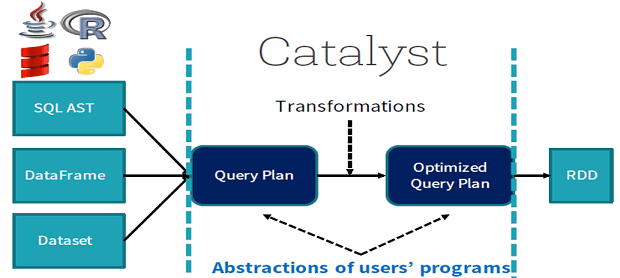
Содержание
Мы уже немного рассказывали об SQL-оптимизации в Apache Spark. Продолжая эту тему, сегодня рассмотрим подробнее, что такое Catalyst – встроенный оптимизатор структурированных запросов в Spark SQL, а также поговорим про базовые понятия SQL-оптимизации. Читайте в нашей статье о логической и физической оптимизации, плане выполнения запросов и зачем эти концепции нужны при аналитической обработке Big Data в рамках фреймворка Спарк.
Как работает SQL-оптимизация и зачем она нужна: немного теории
Благодаря наличию модуля SQL, Apache Spark позволяет группировать, фильтровать и преобразовывать большие данные с помощью структурированных запросов. Однако, в отличие от реляционных СУБД, Apache Spark работает с данными различных форматов и структур, которые не являются типовой таблицей: RDD (распределенная коллекция данных), DataSet и DataFrame. Тем не менее, некоторые аспекты классической теории баз данных актуальны и для Spark SQL.
Напомним, что в традиционных СУБД SQL-оптимизация, как правило, состоит из двух этапов [1]:
- логической оптимизации, когда заданный запрос переписывается (обычно на основе эвристик или правил) в эквивалентную, но потенциально более декларативную или оптимальную форму;
- физической оптимизации, когда выбираются методы доступа, последовательность соединений и методы соединений для генерации эффективного плана выполнения запроса.
Под планом выполнения запроса подразумевают последовательность операций, необходимых для получения его результата. Планирование SQL-запроса также выполняется в 2 этапа [2]:
- Выборка результатов с помощью вложенных циклов (итеративных процессов поиска данных в каждой из соединяемых таблиц) и слияния, если объединяемые таблицы имеют индексы по сравниваемым полям;
- Сортировка и группировка, если не найдено путей доступа для получения результата в запрошенном порядке, а также выполнение агрегаций.
Оптимизатор запросов старается выбрать самый эффективный план выполнения запроса. Для этого он использует хранящуюся в базе данных статистическую информацию для оценки альтернативных способов формирования результатов запроса. Изучая планы выполнения запросов от оптимизатора, можно самостоятельно решить задачу ускорения запроса путем его изменения или через создание в базе данных дополнительного индекса [2].
Core Spark - основы для разработчиков
Код курса
CORS
Ближайшая дата курса
16 марта, 2026
Продолжительность
16 ак.часов
Стоимость обучения
51 200
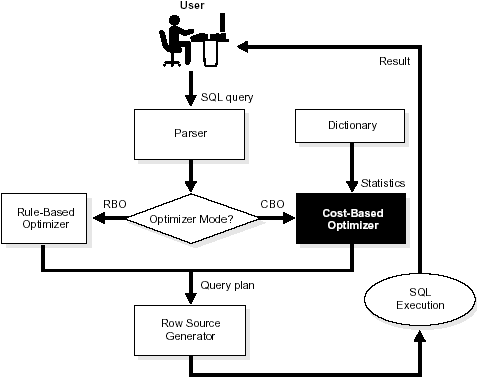
Принято выделять два вида оптимизации SQL-запросов [3]:
- на основе фиксированных правил (Rule-based optimizator, RBO), например, применение условий фильтраций на более ранних этапах, если это возможно, предварительном вычислении констант и т.д.
- на базе оценки стоимости выполнения запроса (Cost-based optimizator, CBO), когда для оценки качества полученного плана используется стоимостная функция, которая обычно зависит от объема обрабатываемых данных, количества строк, попадающих под фильтры, стоимости выполнения тех или иных операций. Для корректной работы CBO-оптимизатору необходимо знать и хранить информацию по статистике данных, используемых в запросе (количество записей, размер записи, гистограммы распределения данных в столбцах таблиц).
Если SQL-оптимизатор поддерживает оба вышеотмеченных варианта (RBO и CBO), это позволит получить лучшие результаты, т.е. повысит скорость выполнения запросов. Однако, стоит следить за применимостью основных правил, позволяющих отфильтровать как можно больше «лишних» данных на как можно более ранних этапах [3]. Оптимизатор структурированных запросов Spark SQL, о котором мы поговорим далее, реализует оба этих подхода. Об улучшениях оптимизатора Catalyst в рамках проекта Radiant читайте в нашей новой статье.
Что такое Catalyst – оптимизатор Spark SQL
Итак, для оптимизации структурированных запросов с целью сокращения времени и вычислительных ресурсов на их выполнение в Spark SQL имеется модуль Catalyst. Этот оптимизатор запросов, написанных как непосредственно на языке SQL, так и на доменном DataFrame DSL (Domain Structured Language). Благодаря Catalyst SQL-запросы в DataSet и DataFrame выполняются намного быстрее, чем их функциональные аналоги в RDD [4].
Сам Catalyst написан на языке Scala и основан на конструкциях функционального программирования и является расширяемым, что позволяет разработчикам Big Data дополнять его по мере необходимости [5]. В частности, можно самостоятельно определять внешние источники данных и заданные пользователем типы данных. Catalyst состоит из целого набора библиотек, написанных на Scala [6]:
- общая библиотека для представления деревьев и применения правил для управления ими;
- специфичные библиотеки для обработки реляционных запросов, выражений и планов логических запросов;
- несколько наборов правил, которые обрабатывают различные фазы выполнения запросов: анализ, логическая оптимизация, физическое планирование и генерация кода для компиляции частей запросов в байт-код Java.
- функции Scala для генерации кода из составных выражений.
Анализ данных с помощью современного Apache Spark
Код курса
SPARK
Ближайшая дата курса
16 марта, 2026
Продолжительность
32 ак.часов
Стоимость обучения
102 400
В следующей статье мы расскажем подробнее о том, как Catalyst осуществляет SQL-оптимизацию в Apache Spark, преобразуя деревья и работая с планом выполнения запросов. А реальные навыки эксплуатации Apache Spark для разработки распределенных приложений и аналитики больших данных вам помогут узнать специализированные курсы в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источники
- http://citforum.ru/database/oracle/cost-based_query_tr/
- https://ru.wikipedia.org/wiki/План_выполнения_запроса
- https://habr.com/ru/company/neoflex/blog/417103/
- http://blog.madhukaraphatak.com/introduction-to-spark-two-part-6/
- https://data-flair.training/blog/spark-sql-optimization/
- https://databricks.com/glossary/catalyst-optimizer

