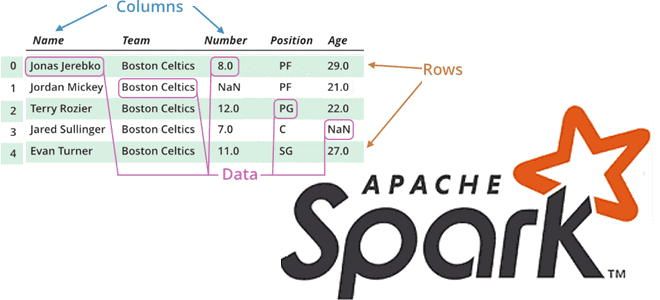
Продолжая разговор про вычислительные операции над датафреймами в Apache Spark, сегодня рассмотрим, какие преобразования (transformations) и действия (actions) чаще всего используются при разработке распределенных приложений и аналитике больших данных. Читайте далее, про виды столбцовых преобразования и отличия действия collect() от take(). Преобразования в Apache Spark: виды и особенности реализации Напомним,...
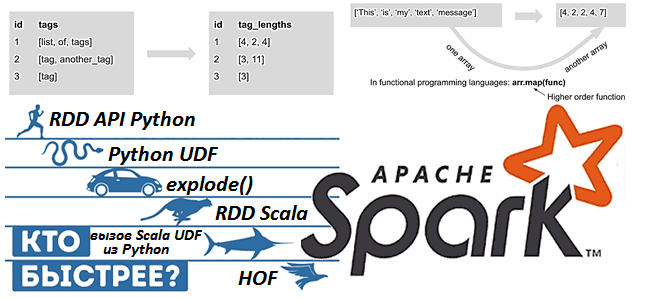
Apache Spark предоставляет для разработчика распределенных приложений множество возможностей, позволяя достигать одной целей разными способами. Чтобы проиллюстрировать это, сегодня рассмотрим бенчмаркинговое сравнение 9 методов обработки массивов в Spark 3.1, обращая внимание на их производительность и особенности использования. Также разберем важные для обучения разработчиков Spark темы про отличия преобразований от действий...

Apache Spark + AirFlow – известная каждому дата-инженеру комбинация технологий Big Data для запуска сложных конвейеров обработки данных. Но совместное использование этих фреймворков ограничено недостатками AirFlow, часть из которых можно обойти с помощью Apache Livy. Однако эксплуатация AirFlow менее удобна, чем Dagster. Поэтому сегодня рассмотрим, как этот альтернативный оркестратор данных...

Сегодня рассмотрим Apache Spark с точки зрения Data Science специалиста: поговорим про сходства и отличия библиотек машинного обучения в этом фреймворке. Также ответим на вопрос «Spark ML vs MLLib», разберем, зачем Data Scientist’у и аналитику больших данных нужны курсы по Apache Spark, а в заключение отметим наиболее важные улучшения библиотеки...

Развивая наши курсы по Apache Spark, сегодня мы рассмотрим несколько особенностей, с разработчик которыми может столкнуться при выполнении обычных операции, от чтения архивированного файла до обращения к сервисам Amazon. Читайте далее, что не так с методом getDefaultExtension(), зачем к AWS S3 так много коннекторов и почему PySpark нужно дополнительно конфигурировать...

В этой статье продолжим говорить про обучение разработчиков Apache Spark и рассмотрим, какие сегменты памяти есть в этом Big Data фреймворке и как с ними работать наиболее эффективно. Читайте далее, почему процессы PySpark и SparkR потребляют внешнюю память, чем пользовательская память кучи JVM отличается от памяти хранилища и какие конфигурации...

С учетом тренда на контейнеризацию при разработке и развертывании любых технологий, в т.ч. Big Data, сегодня рассмотрим плюсы и минусы совместного использования Apache Spark с Kubernetes. Читайте далее, как отправить Спарк-задание в кластер Кубернетес и почему это сэкономит затраты на вашу инфраструктуру аналитики больших данных, не повысив производительность отдельных приложений,...
Мы уже рассказывали, почему качество данных является важнейшим аспектом разработки и эксплуатации Big Data систем. Приемлемое для эффективного использования качество массивов информации достигается не только с помощью процессов подготовки датасета к машинному обучению и профилирования данных, но и за счет их согласования. Читайте далее, что такое Data reconciliation, зачем это...
В продолжение разговора о применении технологий Big Data и Machine Learning в рекламе и маркетинге, сегодня рассмотрим архитектуру системы прогнозирования конверсии рекламных объявлений. Читайте далее, как организовать предиктивную аналитику больших данных на Apache Kafka и компонентах ELK-стека (Elasticsearch, Logstash, Kibana), почему так важно тщательно подготовить данные к машинному обучению, какие...

Обучение Apache Spark, Kafka, Hadoop и прочим технологиям Big Data – это не только курсы, теоретические статьи и практические задания, но и проверка полученных знаний. Поэтому сегодня мы предлагаем вам открытый интерактивный тест по основам Спарк для начинающих. Проверьте, насколько хорошо вы знакомы с особенностями администрирования и эксплуатации этого популярного...